super json mode
1.0.0
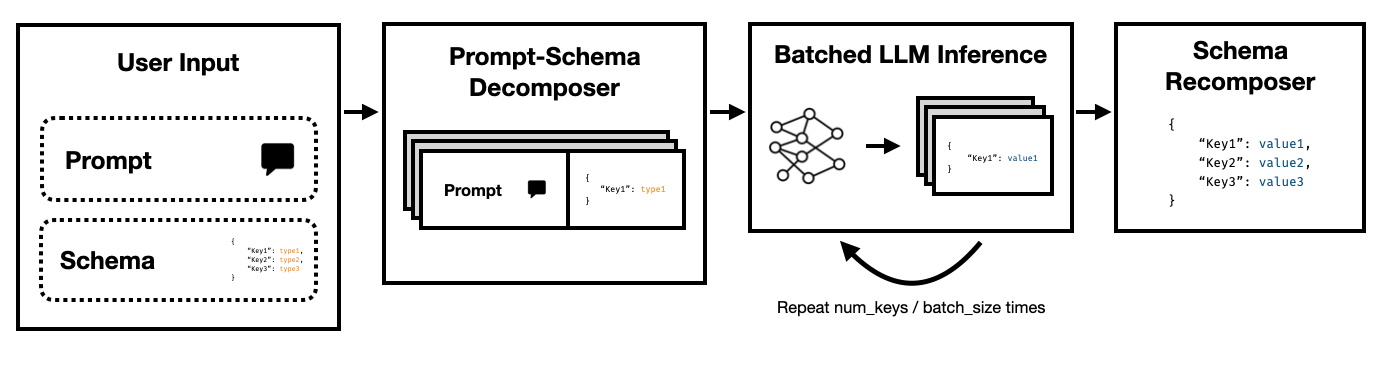
O Modo Super JSON é uma estrutura Python que permite a criação eficiente de saída estruturada de um LLM, quebrando um esquema de destino em componentes atômicos e depois executando gerações em paralelo.
Ele suporta ambas as API de conclusão do Open of the Art LLMs, por meio do Legacy de conclusão do OpenAI , como através de Transformadores de Face Hugging e VLLM . Mais LLMS será suportado em breve!
Comparado a um pipeline de geração JSON ingênuo que confia nos transformadores de estimação e HF, descobrimos que o modo Super JSON pode gerar saídas até 10x mais rapidamente . Também é mais determinístico e menos provável de encontrar problemas de análise quando comparado à geração ingênua.
A instalação é simples: pip install super-json-mode
Os formatos de saída estruturados, como JSON ou YAML, têm uma estrutura paralela ou hierárquica inerente.
Considere a seguinte passagem não estruturada (gerada pelo GPT-4):
Bem -vindo ao 123 Azure Lane, uma impressionante residência de São Francisco, com um design contemporâneo fantástico, agora no mercado por US $ 2.500.000. Espalhado por um luxuoso pés quadrados, esta propriedade combina sofisticação e conforto para criar uma experiência de vida verdadeiramente única.
Um lar idílico para famílias ou profissionais, nossa residência exclusiva está equipada com cinco quartos espaçosos, cada calor escorrendo e elegância moderna. Os quartos são cuidadosamente planejados para permitir amplo espaço natural e espaço de armazenamento generoso. Com três banheiros completos elegantemente projetados, a residência garante conveniência e privacidade para seus residentes.
A grande entrada o leva a uma espaçosa área de estar, proporcionando um excelente ambiente para reuniões ou uma noite tranquila ao lado do incêndio. A cozinha do chef inclui aparelhos de última geração, armários personalizados e belas bancadas em granito, tornando-o um sonho para quem gosta de cozinhar.
Se quisermos extrair address , square footage , number of bedrooms , number of bathrooms e price usando um LLM, poderíamos pedir ao modelo que preencha um esquema de acordo com a descrição.
Um esquema em potencial (como um gerado a partir de um objeto pydantic) poderia ser assim:
{
"address": {
"type": "string"
},
"price": {
"type": "number"
},
"square_feet": {
"type": "integer"
},
"num_beds": {
"type": "integer"
},
"num_baths": {
"type": "integer"
}
}
E uma saída válida pode parecer algo assim:
{
"address": "123 Azure Lane",
"price": 2500000,
"square_feet": 3000,
"num_beds": 5,
"num_baths": 3
}
A abordagem óbvia é aninhar o esquema no prompt e solicitar ao modelo que o preencha. Atualmente, é assim que a maioria das equipes extrai atualmente a saída estruturada do texto não estruturado usando LLMS.
No entanto, isso é ineficiente por três razões.
Observe como cada uma dessas chaves é independente uma da outra. O Modo Super JSON aproveita o paralelismo imediato , tratando todos os pares de valor-chave no esquema como uma investigação separada. Por exemplo, podemos extrair os num_baths sem já ter gerado o address !
Solicitar um modelo para gerar o JSON do zero consome desnecessariamente tokens (e mais antes) com sintaxe previsível, como aparelhos e nomes de chaves, que já são esperados na saída. Este é um forte anterior à geração que devemos poder usar para melhorar as latências.
Os LLMs são embaraçosamente paralelos e as consultas em lotes são muito mais rápidas do que em uma ordem em série. Assim, podemos dividir o esquema em várias consultas. O LLM preencherá o esquema para cada chave independente em paralelo e emitirá muito menos tokens em um único passe, permitindo tempos de inferência muito mais rápidos.
Execute o seguinte comando:
pip install super-json-mode
conda create --name superjsonmode python=3.10 -y
conda activate superjsonmode
git clone https://github.com/varunshenoy/super-json-mode
cd superjsonmode
pip install -r requirements.txt
Tentamos facilitar o uso do Modo Super JSON. Veja a pasta examples para obter mais exemplos e uso de vLLM .
Usando o OpenAI e gpt-3-instruct-turbo :
from superjsonmode . integrations . openai import StructuredOpenAIModel
from pydantic import BaseModel
import time
model = StructuredOpenAIModel ()
class Character ( BaseModel ):
name : str
genre : str
age : int
race : str
occupation : str
best_friend : str
home_planet : str
prompt_template = """{prompt}
Please fill in the following information about this character for this key. Keep it succinct. It should be a {type}.
{key}: """
prompt = """Luke Skywalker is a famous character."""
start = time . time ()
output = model . generate (
prompt ,
extraction_prompt_template = prompt_template ,
schema = Character ,
batch_size = 7 ,
stop = [ " n n " ],
temperature = 0 ,
)
print ( f"Total time: { time . time () - start } " )
# Total Time: 0.409s
print ( output )
# {
# "name": "Luke Skywalker",
# "genre": "Science fiction",
# "age": "23",
# "race": "Human",
# "occupation": "Jedi Knight",
# "best_friend": "Han Solo",
# "home_planet": "Tatooine",
# }Usando o Mistral 7b com Transformers Huggingface:
from transformers import AutoTokenizer , AutoModelForCausalLM
from superjsonmode . integrations . transformers import StructuredOutputForModel
from pydantic import BaseModel
device = "cuda"
model = AutoModelForCausalLM . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" ). to ( device )
tokenizer = AutoTokenizer . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" )
# Create a structured output object
structured_model = StructuredOutputForModel ( model , tokenizer )
passage = """..."""
class QuarterlyReport ( BaseModel ):
company : str
stock_ticker : str
date : str
reported_revenue : str
dividend : str
prompt_template = """[INST]{prompt}
Based on this excerpt, extract the correct value for "{key}". Keep it succinct. It should have a type of `{type}`.[/INST]
{key}: """
output = structured_model . generate ( passage ,
extraction_prompt_template = prompt_template ,
schema = QuarterlyReport ,
batch_size = 6 )
print ( json . dumps ( output , indent = 2 ))
# {
# "company": "NVIDIA",
# "stock_ticker": "NVDA",
# "date": "2023-10",
# "reported_revenue": "18.12 billion dollars",
# "dividend": "0.04"
# } Existem muitos recursos que podem melhorar o modo JSON. Aqui estão algumas idéias.
Análise de Saída Qualitativa : Executamos benchmarks de desempenho, mas devemos apresentar uma abordagem mais rigorosa para julgar os resultados qualitativos do Modo Super JSON.
Amostragem estruturada : Idealmente, devemos mascarar os logits do LLM para aplicar as restrições do tipo, semelhante ao JSONFORMER. Existem alguns pacotes por aí que já fazem isso, e esses devem integrar nosso pipeline de geração JSON paralela ou devemos construí -lo no modo Super JSON.
Suporte do gráfico de dependência : o Modo Super JSON tem um caso de falha muito óbvio: quando uma chave depende de outra chave. Considere uma bolha json com duas chaves, thought e response . Esse tipo de saída desejada é comum para a cadeia de pensamentos com grandes modelos de linguagem, e é muito claro que a response depende do thought . Deveríamos ser capazes de passar em um gráfico de dependências e avisos de lote de uma maneira que as saídas dos pais sejam concluídas e transmitidas para itens de esquema infantil.
Suporte ao modelo local : o Modo Super JSON funciona melhor em situações locais em que o tamanho do lote geralmente é 1. Você pode explorar lote para reduzir a latência, semelhante à decodificação especulativa. Llama.cpp é a estrutura principal para modelos locais + inferência de CPU. Eu adoraria implementar isso usando o ollama, se possível.
Suporte TRT-LLM : O VLLM é ótimo e fácil de usar, mas, idealmente, nos integramos a uma estrutura muito mais com desempenho, como o TRT-LLM.
Agradecemos se você citar este repositório se achar a biblioteca útil para o seu trabalho:
@misc{ShenoyDerhacobian2024,
author = {Shenoy, Varun and Derhacobian, Alex},
title = {Super JSON Mode: A Framework for Accelerated Structured Output Generation},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/varunshenoy/super-json-mode}}
}
Este projeto foi construído para CS 229: Sistemas para aprendizado de máquina. Muito obrigado à equipe de ensino e à TAS por sua orientação ao longo deste projeto.


