
[Recomendações relacionadas: tutoriais em vídeo sobre JavaScript, front-end da web]
Não importa qual linguagem de programação você usa, strings são um tipo de dados importante. Siga-me para aprender mais sobre strings JavaScript !
Uma string é uma string composta de caracteres Se você estudou C e Java , deve saber que os próprios caracteres também podem se tornar um tipo independente. No entanto, JavaScript não possui um único tipo de caractere, apenas strings de comprimento 1 .
As strings JavaScript usam codificação UTF-16 fixa. Não importa qual codificação usarmos ao escrever o programa, ela não será afetada.
strings: aspas simples, aspas duplas e crases.
let single = 'abcdefg';//Aspas simples let double = "asdfghj";//Aspas duplas let backti = `zxcvbnm`;//Aspas
simples e duplas têm o mesmo status, não fazemos distinção.
Os crasesde formatação de strings
nos permitem formatar strings com elegância usando ${...} em vez de usar a adição de strings.
let str = `Tenho ${Math.round(18.5)} anos.`;console.log(str) ;

de strings multilinhas
também permitem que a string abranja linhas, o que é muito útil quando escrevemos strings multilinhas.
let ques = `O autor é bonito? R. Muito bonito; B. Tão lindo; C. Super bonito;`;console.log(ques);
Resultados de execução de código:
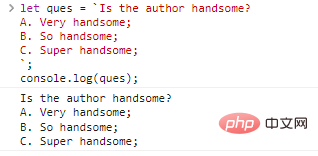
Não parece que não há nada de errado com isso? Mas isso não pode ser conseguido usando aspas simples e duplas. Se você quiser obter o mesmo resultado, você pode escrever assim:
let ques = 'O autor é bonito?nA. Super bonito;'; console.log(ques);
O código acima contém um caractere especial n , que é o caractere especial mais comum em nosso processo de programação.
n também conhecido como "caractere de nova linha", suporta aspas simples e duplas para gerar strings multilinhas. Quando o mecanismo gera uma string, se encontrar n , ele continuará a produzir em outra linha, realizando assim uma string multilinha.
Embora n pareça ter dois caracteres, ele ocupa apenas uma posição de caractere. Isso ocorre porque é um caractere de escape na string e os caracteres modificados pelo caractere de escape tornam-se caracteres especiais.
Lista de caracteres especiais
| Descrição | de caracteres especiais |
|---|---|
n | , usado para iniciar uma nova linha de texto de saída. |
r | move o cursor para o início da linha. Em sistemas Windows , rn é usado para representar uma quebra de linha, o que significa que o cursor precisa ir primeiro para o início da linha e depois. para a próxima linha antes de poder mudar para uma nova linha. Outros sistemas podem usar n diretamente. |
' " | Aspas simples e duplas, principalmente porque aspas simples e duplas são caracteres especiais. Se quisermos usar aspas simples e duplas em uma string, devemos escapá-las. |
\ | Barra invertida, também porque |
b f v | backspace, feed de página, rótulo vertical - ele não é mais usado |
xXX | é um caractere Unicode hexadecimal codificado como XX , por exemplo |
: x7A significa z (a codificação Unicode hexadecimal de z é 7A ). | |
uXXXX | é codificado como o caractere Unicode hexadecimal de XXXX , por exemplo: u00A9 significa © |
( 1-6 caracteres hexadecimais u{X...X} | UTF-32 codificação é o símbolo Unicode de X...X . |
Por exemplo:
console.log('I'ma student.');// 'console.log(""I love U. "");/ / "console.log("\n é um caractere de nova linha.");// nconsole.log('u00A9')// ©console.log('u{1F60D} ');// Código resultados de execução:
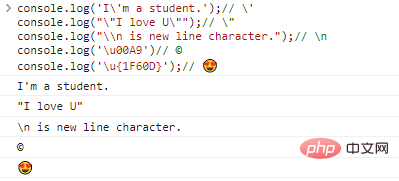
Com a existência do caractere de escape , teoricamente podemos gerar qualquer caractere, desde que encontremos sua codificação correspondente.
Evite usar ' e "
para aspas simples e duplas em strings. Podemos usar aspas duplas dentro de aspas simples, usar aspas simples dentro de aspas duplas ou usar aspas simples e duplas diretamente entre crases. Evite usar caracteres de escape, por exemplo:
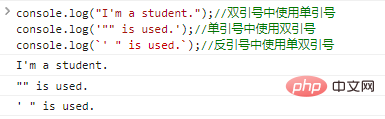
console.log("Sou estudante.");
//Use aspas simples entre aspas duplas console.log('"" is used.');
//Use aspas duplas entre aspas simples console.log(`' " is used.`);
//Os resultados da execução do código usando aspas simples e duplas entre crases são os seguintes:
Através da propriedade .length da string, podemos obter o comprimento da string:
console.log("HelloWorldn".length);//11 n aqui ocupa apenas um caractere.
No capítulo "Métodos de tipos básicos", exploramos por que os tipos básicos em
JavaScriptpossuem propriedades e métodos. Você ainda se lembra?
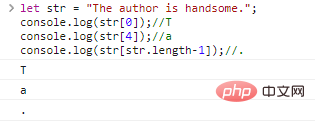
0 é uma string de caracteres Podemos acessar um único caractere através de [字符下标]
.console.log(str[0]);//Tconsole.log(str
[
4]);//aconsole.log(str[str.length-1]);//.
Também podemos usar a função charAt(post) para obter caracteres:
let str = "O autor é bonito.";console.log(str.charAt(0)); //Tconsole.log(str.charAt(4)); //aconsole.log(str.charAt(str.length-1));//.O
efeito de execução dos dois é exatamente o mesmo, a única diferença é ao acessar caracteres fora dos limites:
let str = "01234"; console.log(str[ 9]);//undefinedconsole.log(str.charAt(9));//"" (string vazia)
Também podemos usar for ..of para percorrer a string:
for(let c of '01234'){
console.log(c);} Uma string em JavaScript não pode ser alterada depois de definida. Por exemplo:
let str = "Const";str[0] = 'c' ;console.log(str)
; resultados:
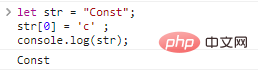
Se você deseja obter uma string diferente, você só pode criar uma nova:
let str = "Const";str = str.replace('C','c');console.log
(str);
alteramos a String de caracteres, na verdade a string original não foi alterada, o que obtemos é a nova string retornada pelo método replace .
converte a caixa de uma string ou converte a caixa de um único caractere em uma string.
Os métodos para essas duas strings são relativamente simples, como mostrado no exemplo:
console.log('Good Boy'.toLowerCase());//good
boyconsole.log('Bom menino'.toUpperCase());//BOM
BOYconsole.log('Good Boy'[5].toLowerCase());//b resultados da execução do código:
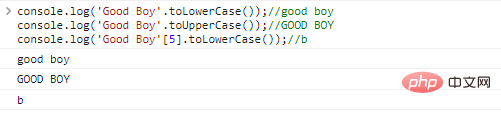
A função .indexOf(substr,idx) começa na posição idx da string, procura a posição da substring substr e retorna o subscrito do primeiro caractere da string. substring se for bem-sucedido ou -1 se falhar.
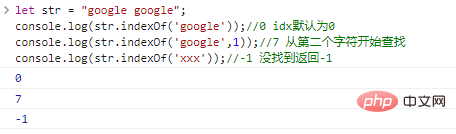
deixe str = "google google";console.log(str.indexOf('google'));
//0 idx é padronizado como 0console.log(str.indexOf('google',1));
//7 Pesquisa console.log(str.indexOf('xxx'));
//-1 não encontrado retorna -1 resultado de execução de código:
Se quisermos consultar as posições de todas as substrings na string, podemos usar um loop:
let str = "I love love love love u.";let sub = "love";let pos = -1;while((pos = str.indexOf (sub,pos+1)) != -1)
console.log(pos); Os resultados da execução do código são os seguintes:
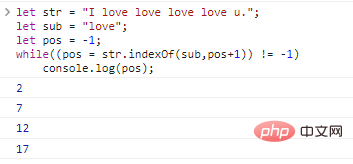
.lastIndexOf(substr,idx) procura por substrings de trás para frente, primeiro encontrando a última string correspondente:
let str = "google google";console.log(str.lastIndexOf('google'));//7 idx tem como padrão 0 porque indexOf() e lastIndexOf() retornarão -1 quando a consulta não for bem-sucedida e ~-1 === 0 . Ou seja, usar ~ só é verdadeiro quando o resultado da consulta não é -1 , então podemos:
let str = "google google";if(~indexOf('google',str)){
...} Normalmente, não recomendamos o uso de uma sintaxe onde as características da sintaxe não possam ser claramente refletidas, pois isso terá um impacto na legibilidade. Felizmente, o código acima só aparece na versão antiga do código. Ele é mencionado aqui para que todos não fiquem confusos ao ler o código antigo.
Suplemento:
~é o operador de negação bit a bit. Por exemplo: a forma binária do número decimal2é0010e a forma binária de~2é1101(complemento), que é-3.Uma forma simples de entender,
~né equivalente a-(n+1), por exemplo:~2 === -(2+1) === -3
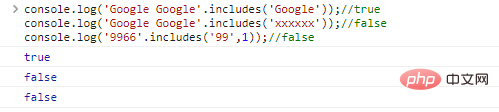
.includes(substr,idx) é usado para determinar se substr está na string idx é a posição inicial da consulta
console.log('Google Google'.includes('Google'));//trueconsole.log( 'Google Google'. include('xxxxxx'));//falseconsole.log('9966'.includes('99',1));// resultados de execução de código falso:
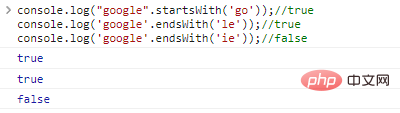
.startsWith('substr') e .endsWith('substr') respectivamente determinam se a string começa ou termina com substr
console.log("google".startsWith('go'));//trueconsole.log('google' .endsWith('le'));//trueconsole.log('google'.endsWith('ie'));// resultado de execução de código falso:
.substr() , .substring() , .slice() são todos usados para obter substrings de strings, mas seu uso é diferente.
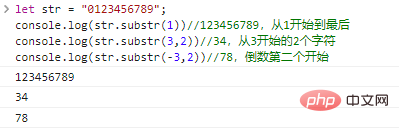
.substr(start,len)
retorna uma string consistindo em caracteres len começando em start . Se len for omitido, ele será interceptado até o final da string original. start pode ser um número negativo, indicando o caractere start de trás para frente.
deixe str = "0123456789";console.log(str.substr(1))//123456789, começando de 1 até o final console.log(str.substr(3,2))//34, 2 começando de 3 caracteres console.log(str.substr(-3,2))//78, o penúltimo
resultado da execução do código inicial:
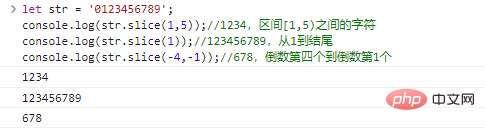
.slice(start,end)
retorna a string começando no start e terminando no end (exclusivo). start e end podem ser números negativos, indicando os penúltimos caracteres start/end .
let str = '0123456789';console.log(str.slice(1,5));//1234, caracteres entre o intervalo [1,5) console.log(str.slice(1));//123456789 , de 1 ao final console.log(str.slice(-4,-1));//678, do quarto ao último
resultado da execução do código:
.substring(start,end)
a
mesma que .slice() . A diferença está em dois lugares:
end > start0 ;deixe str = '0123456789'; 3));//012, -1 é tratado como resultado da execução do código Make 0
:
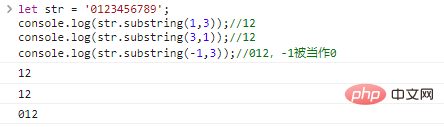
Compare as diferenças entre os três:
| descrição | do método | parâmetros.slice |
|---|---|---|
.slice(start,end) | [start,end) | pode ser negativo.substring |
.substr(start,len) | ||
0 | .substring(start,end) | [start,end) |
começa do start len | muitos |
métodos de substring negativos para len, por isso é naturalmente difícil escolher
.slice(), que é mais flexível que os outros dois.
Já mencionamos a comparação de strings no artigo anterior. Strings são classificadas na ordem do dicionário. Atrás de cada caractere há um código, e o código ASCII é uma referência importante.
Por exemplo:
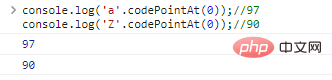
console.log('a'>'Z');// A comparação entre caracteres verdadeiros é essencialmente uma comparação entre codificações que representam caracteres. JavaScript usa UTF-16 para codificar strings. Cada caractere é um código de 16 bits. Se você quiser saber a natureza da comparação, precisará usar .codePointAt(idx) para obter a codificação de caracteres:
console.log('a. '.codePointAt( 0));//97console.log('Z'.codePointAt(0));//90 resultados de execução de código:
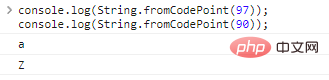
Use String.fromCodePoint(code) para converter a codificação em caracteres:
console.log(String.fromCodePoint(97));console.log(String.fromCodePoint(90))
;
Este processo pode ser alcançado usando o caractere de escape u , como segue:
console.log('u005a');//Z, 005a é a notação hexadecimal de 90 console.log('u0061');//a, 0061 É a notação hexadecimal de 97. Vamos explorar os caracteres codificados no intervalo [65,220] :
let str = '';for(let i = 65; i<=220; i++){
str+=String.fromCodePoint(i);}console.log(str); Os resultados da parte de execução do código são os seguintes:

A imagem acima não mostra todos os resultados, então experimente.
é baseado no padrão internacional ECMA-402 . JavaScript implementou um método especial ( .localeCompare() ) para comparar várias strings, usando str1.localeCompare(str2) :
str1 < str2 , retorne um número negativo;str1 > str2 , retorne um número positivo;str1 == str2 , retorne 0;por exemplo:
console.log("abc".localeCompare('def'));//-1 Por que não usar operadores de comparação diretamente?
Isso ocorre porque os caracteres ingleses têm algumas formas especiais de escrita. Por exemplo, á é uma variante de a :
console.log('á' < 'z');// Embora false também seja a , é maior que z ! !
Neste momento, você precisa usar .localeCompare() :
console.log('á'.localeCompare('z'));//-1 str.trim() remove caracteres de espaço em branco antes e depois do
str.repeat(n)
str.trimStart() str.trimEnd() e no final;
let str = " 999 "; console.log(str.trim());
a string n vezes;
let str = ' 6';console.log(str.repeat(3));//666
str.replace(substr,newstr) substitui a primeira substring, str.replaceAll() é usado para substituir todos substrings;
deixe str = '9 +9';console.log(str.replace('9','6'));//6+9console.log(str.replaceAll('9','6')) ;//6+6ainda Existem muitos outros métodos e podemos visitar o manual para mais conhecimento.
usam JavaScript UTF-16 para codificar strings, ou seja, dois bytes ( 16 bits) são usados para representar um caractere. No entanto, dados 16 bits podem representar apenas 65536 caracteres. caracteres comuns naturalmente não são incluídos. É fácil de entender, mas não é suficiente para caracteres raros (chinês), emoji , símbolos matemáticos raros, etc.
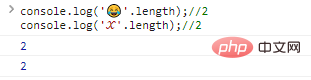
Neste caso, você precisa expandir e usar dígitos mais longos ( 32 bits) para representar caracteres especiais, por exemplo:
console.log(''.length);//2console.log('?'.length);//2 Resultado da execução do código:
O resultado disso é que não podemos processá-los usando métodos convencionais. O que acontece se gerarmos cada byte individualmente?
console.log(''[0]);console.log(''[1]) ;
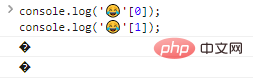
Como você pode ver, os bytes de saída individuais não são reconhecidos.
Felizmente, String.fromCodePoint() e .codePointAt() podem lidar com essa situação porque foram adicionados recentemente. Em versões mais antigas do JavaScript , você só pode usar String.fromCharCode() e .charCodeAt() para converter codificações e caracteres, mas eles não são adequados para caracteres especiais.
Podemos lidar com caracteres especiais julgando o intervalo de codificação de um caractere para determinar se é um caractere especial. Se o código de um caractere estiver entre 0xd800~0xdbff , então é a primeira parte do caractere de 32 bits e sua segunda parte deve estar entre 0xdc00~0xdfff .
Por exemplo:
console.log(''.charCodeAt(0).toString(16));//d83
dconsole.log('?'.charCodeAt(1).toString(16));// resultado da execução do código de02:

Em inglês, existem muitas variantes baseadas em letras, por exemplo: a letra a pode ser o caractere básico de àáâäãåā . Nem todos esses símbolos variantes são armazenados na codificação UTF-16 porque há muitas combinações de variações.
Para suportar todas as combinações de variantes, vários caracteres Unicode também são usados para representar um único caractere variante. Durante o processo de programação, podemos usar caracteres básicos mais "símbolos decorativos" para expressar caracteres especiais:
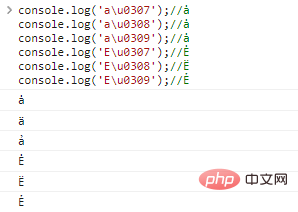
console.log('au0307 '. ); //
console.log('au0308');//ȧ
console.log('au0309');//ȧ
console.log('Eu0307');//Ė
console.log('Eu0308');//E
console.log('Eu0309');// ẺResultados da execução do código:
Uma letra básica também pode ter várias decorações, por exemplo:
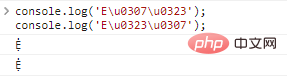
console.log('Eu0307u0323');//Ẹ̇
console.log('Eu0323u0307');// Ẹ̇Resultados da execução do código:
Há um problema aqui. No caso de decorações múltiplas, as decorações são ordenadas de forma diferente, mas os caracteres realmente exibidos são os mesmos.
Se compararmos essas duas representações diretamente, obteremos o resultado errado:
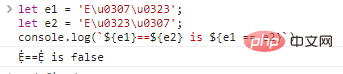
seja e1 = 'Eu0307u0323';
seja e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} é ${e1 == e2}`) resultados de execução de código:
Para resolver esta situação, existe um algoritmo de normalização ** Unicode que pode converter a string em um formato ** universal, implementado por str.normalize() :
let e1 = 'Eu0307u0323';
seja e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} é ${e1.normalize() == e2.normalize()}`)
Resultados de execução de código:

[Recomendações relacionadas: tutoriais em vídeo de JavaScript, front-end da web]
O conteúdo acima é o conteúdo detalhado dos métodos básicos comuns de strings JavaScript. Para obter mais informações, preste atenção a outros artigos relacionados no site PHP chinês!