
Antes de estudar o conteúdo deste artigo, devemos primeiro entender o conceito de assíncrono. A primeira coisa a enfatizar é que existe uma diferença essencial entre assíncrono e paralelo .
Paralelismo geralmente se refere à computação paralela, o que significa que múltiplas instruções são executadas ao mesmo tempo. Essas instruções podem ser executadas em múltiplos núcleos da mesma CPU , ou em múltiplas CPU , ou em múltiplos hosts físicos ou mesmo em múltiplas redes.
A sincronização geralmente se refere à execução de tarefas em uma ordem predeterminada. Somente quando a tarefa anterior for concluída, a próxima tarefa será executada.
Assíncrono, correspondente à sincronização, significa que CPU deixa de lado temporariamente a tarefa atual, processa primeiro a próxima tarefa e depois retorna à tarefa anterior para continuar a execução após receber a notificação de retorno de chamada da tarefa anterior. segundo tópico participe .
Talvez seja mais intuitivo explicar o paralelismo, a sincronização e a assincronidade na forma de imagens. Suponha que haja duas tarefas A e B que precisam ser processadas. Os métodos de processamento paralelo, síncrono e assíncrono adotarão os métodos de execução mostrados no exemplo. seguinte figura:
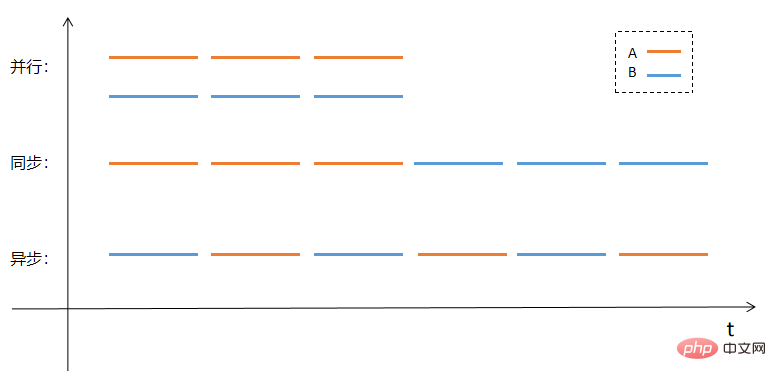
JavaScript nos fornece muitas funções assíncronas. Essas funções nos permitem executar tarefas assíncronas de maneira conveniente. Ou seja, começamos a executar uma tarefa (função) agora, mas a tarefa será concluída mais tarde e o tempo de conclusão específico. não é Não tenho certeza.
Por exemplo, a função setTimeout é uma função assíncrona muito típica. Além disso, fs.readFile e fs.writeFile também são funções assíncronas.
Podemos definir nós mesmos um caso de tarefa assíncrona, como personalizar uma função de cópia de arquivo copyFile(from,to) :
const fs = require('fs')function copyFile(from, to) {
fs.readFile(de, (erro, dados) => {
se (errar) {
console.log(err.mensagem)
retornar
}
fs.writeFile (para, dados, (erro) => {
se (errar) {
console.log(err.mensagem)
retornar
}
console.log('Cópia finalizada')
})
})} A função copyFile primeiro lê os dados do arquivo do parâmetro from e depois grava os dados no arquivo apontado pelo parâmetro to .
Podemos chamar copyFile assim:
copyFile('./from.txt','./to.txt')//Copiar o arquivo Se houver outro código após copyFile(...) neste momento, o programa não irá wait A execução de copyFile termina, mas é executada diretamente para baixo. O programa não se importa quando a tarefa de cópia do arquivo termina.
copyFile('./from.txt','./to.txt')//O código a seguir não irá esperar que a execução do código acima termine... Neste ponto, tudo parece estar normal, mas se we O que acontece se você acessar diretamente o conteúdo do arquivo ./to.txt após a função copyFile(...) ?
Isso não lerá o conteúdo copiado, assim:
copyFile('./from.txt','./to.txt')fs.readFile('./to.txt',(err,data)= >{
...}) Se o arquivo ./to.txt não tiver sido criado antes de executar o programa, você obterá o seguinte erro:
PS E:CodeNodedemos�3-callback> node .index.js finalizado Cópia concluída PS E:CodeNodedemos�3-callback> node .index.js Erro: ENOENT: arquivo ou diretório inexistente, abra 'E:CodeNodedemos�3-callbackto.txt'Cópia concluída
Mesmo que ./to.txt exista, o conteúdo copiado não pode ser lido.
A razão para este fenômeno é: copyFile(...) é executado de forma assíncrona Depois que o programa executa copyFile(...) , ele não espera a conclusão da cópia, mas a executa diretamente para baixo, causando o arquivo. aparecer. Erro ./to.txt não existe ou o conteúdo do arquivo está vazio (se o arquivo for criado antecipadamente).
O horário de término de execução específico da função assíncrona da função de retorno de chamada não pode ser determinado. Por exemplo, o horário de término de execução da função readFile(from,to) provavelmente depende do tamanho do arquivo from .
Então, a questão é como podemos localizar com precisão o final da execução copyFile e ler o conteúdo to arquivo?
Isso requer o uso de uma função de retorno de chamada. Podemos modificar a função copyFile da seguinte forma:
function copyFile(from, to, callback) {
fs.readFile(de, (erro, dados) => {
se (errar) {
console.log(err.mensagem)
retornar
}
fs.writeFile (para, dados, (erro) => {
se (errar) {
console.log(err.mensagem)
retornar
}
console.log('Cópia finalizada')
callback() // A função Callback é chamada quando a operação de cópia é concluída})
})} Desta forma, se precisarmos realizar algumas operações imediatamente após a conclusão da cópia do arquivo, podemos escrever essas operações na função de retorno de chamada:
function copyFile(from, to, callback) {
fs.readFile(de, (erro, dados) => {
se (errar) {
console.log(err.mensagem)
retornar
}
fs.writeFile (para, dados, (erro) => {
se (errar) {
console.log(err.mensagem)
retornar
}
console.log('Cópia finalizada')
callback() // A função Callback é chamada quando a operação de cópia é concluída})
})}copyFile('./from.txt', './to.txt', function () {
//Passe uma função de retorno de chamada, leia o conteúdo do arquivo "to.txt" e produza fs.readFile('./to.txt', (err, data) => {
se (errar) {
console.log(err.mensagem)
retornar
}
console.log(dados.toString())
})}) Se você preparou o arquivo ./from.txt , então o código acima pode ser executado diretamente:
PS E:CodeNodedemos�3-callback> node .index.js Cópia concluída Junte-se à comunidade "Xianzong" e cultive a imortalidade comigo. Endereço da comunidade: http://t.csdn.cn/EKf1h
Este método de programação é chamado de estilo de programação assíncrona "baseado em retorno de chamada". usado para chamar após o término da tarefa.
Esse estilo é comum na programação JavaScript . Por exemplo, as funções de leitura de arquivo fs.readFile e fs.writeFile são todas funções assíncronas.
A função de retorno de chamada pode lidar com assuntos subsequentes com precisão após a conclusão do trabalho assíncrono. Se precisarmos executar várias operações assíncronas em sequência, precisamos aninhar a função de retorno de chamada.
Cenário de caso:
Implementação de código para leitura do arquivo A e do arquivo B em sequência:
fs.readFile('./A.txt', (err, data) => {
se (errar) {
console.log(err.mensagem)
retornar
}
console.log('Ler arquivo A: ' + data.toString())
fs.readFile('./B.txt', (erro, dados) => {
se (errar) {
console.log(err.mensagem)
retornar
}
console.log("Ler arquivo B: " + data.toString())
})}) Efeito de execução:
PS E:CodeNodedemos�3-callback> node .index.js Ler o arquivo A: Immortal Sect é infinitamente bom, mas está faltando alguém. Ler o arquivo B: Se você quiser entrar no Immortal Sect, você deve ter o link http://t.csdn.cn/H1faI
. o arquivo Depois de A, o arquivo B é lido imediatamente.
E se quisermos continuar lendo o arquivo C após o arquivo B? Isso requer continuar aninhando retornos de chamada:
fs.readFile('./A.txt', (err, data) => {//Primeiro retorno de chamada if (err) {
console.log(err.mensagem)
retornar
}
console.log('Ler arquivo A: ' + data.toString())
fs.readFile('./B.txt', (err, data) => {//Segundo retorno de chamada if (err) {
console.log(err.mensagem)
retornar
}
console.log("Ler arquivo B: " + data.toString())
fs.readFile('./C.txt',(err,data)=>{//O terceiro retorno de chamada...
})
})}) Em outras palavras, se quisermos realizar várias operações assíncronas em sequência, precisaremos de vários níveis de retornos de chamada aninhados. Isso é eficaz quando o número de níveis é pequeno, mas quando há muitos tempos de aninhamento, alguns problemas ocorrerão. ocorrer pergunta.
Convenções de retorno de chamada
Na verdade, o estilo das funções de retorno de chamada em fs.readFile não é uma exceção, mas uma convenção comum em JavaScript . Personalizaremos um grande número de funções de retorno de chamada no futuro e precisamos respeitar esta convenção e formar bons hábitos de codificação.
A convenção é:
callback é reservado para erro. Quando ocorrer um erro, callback(err) será chamado.callback(null, result1, result2,...) será chamado.Com base na convenção acima, uma função de retorno de chamada tem duas funções: tratamento de erros e recepção de resultados. Por exemplo, a função de retorno de chamada de fs.readFile('...',(err,data)=>{}) segue esta convenção.
Se não nos aprofundarmos, o processamento de métodos assíncronos baseados em retornos de chamada parece ser uma maneira perfeita de lidar com isso. O problema é que se tivermos um comportamento assíncrono após o outro, o código ficará assim:
fs.readFile('./a.txt',(err,data)=>{
se(erro){
console.log(err.mensagem)
retornar
}
//Operação de resultado de leitura fs.readFile('./b.txt',(err,data)=>{
se(erro){
console.log(err.mensagem)
retornar
}
//Operação de resultado de leitura fs.readFile('./c.txt',(err,data)=>{
se(erro){
console.log(err.mensagem)
retornar
}
//Operação de resultado de leitura fs.readFile('./d.txt',(err,data)=>{
se(erro){
console.log(err.mensagem)
retornar
}
...
})
})
})}) O conteúdo de execução do código acima é:
À medida que o número de chamadas aumenta, o nível de aninhamento do código torna-se cada vez mais profundo, incluindo cada vez mais instruções condicionais, resultando em código confuso que é constantemente recuado para a direita, dificultando a leitura e manter.
Chamamos esse fenômeno de crescimento contínuo para a direita (recuo para a direita) de “ inferno de callback ” ou “ pirâmide da desgraça ”!
fs.readFile('a.txt',(err,dados)=>{
fs.readFile('b.txt',(err,dados)=>{
fs.readFile('c.txt',(err,dados)=>{
fs.readFile('d.txt',(err,dados)=>{
fs.readFile('e.txt',(err,dados)=>{
fs.readFile('f.txt',(err,dados)=>{
fs.readFile('g.txt',(err,dados)=>{
fs.readFile('h.txt',(err,dados)=>{
...
/*
Portão para o Inferno ===>
*/
})
})
})
})
})
})
})}) Embora o código acima pareça bastante regular, é apenas uma situação ideal, por exemplo. Normalmente, há um grande número de instruções condicionais, operações de processamento de dados e outros códigos na lógica de negócios, o que perturba a bela ordem atual e faz com que a ordem atual seja interrompida. a mudança de código é difícil de manter.
Felizmente, JavaScript nos fornece várias soluções e Promise é a melhor solução.