Rastreamos todas as informações da página web na seção anterior. Agora temos que encontrar o conteúdo que precisamos no código html. Portanto, precisamos entrar no site de acordo com o problema e analisar as informações da página web.
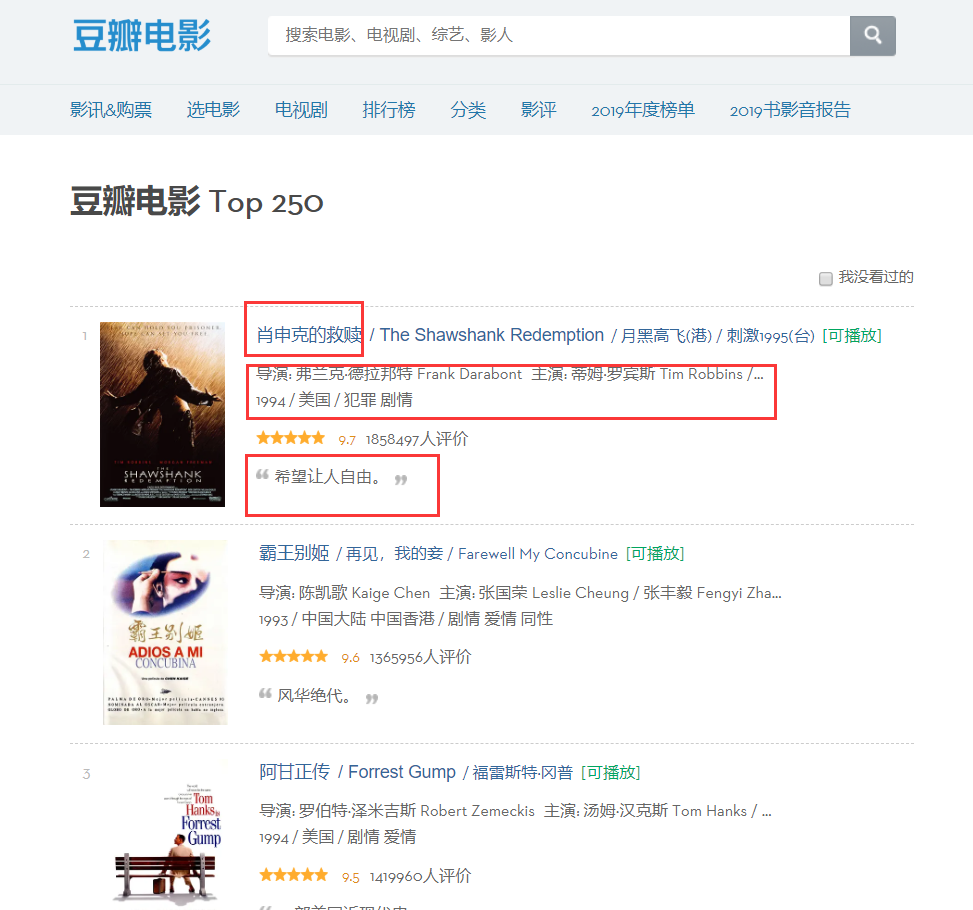
Pode-se descobrir na página que as informações que precisamos rastrear existem em diferentes partições, então vamos verificar os elementos da página, clique com o botão direito na página para verificar o código-fonte da página da web ou F12.

Antes de analisar a página da web, primeiro especificamos o método de armazenamento após a análise. Aqui usamos uma lista para armazenar todas as informações e, em seguida, cada item da lista corresponde a um dicionário, e cada dicionário corresponde a vários tipos de informações.
movies=[]#Primeiro defina uma lista para armazenar todas as informações
Através da análise, podemos determinar que a posição do título é o primeiro 'span' no primeiro 'a' sob o 'div' chamado 'hd', para que possamos bloquear o nome de cada filme através do código a seguir, e então em um dicionário.
moviename=each.find('div',class_='hd').a.span.text.strip()movie['title']=moviename#Um item no dicionárioDa mesma forma, o código-fonte do nome do diretor pode ser encontrado com base no posicionamento, mas esse código-fonte contém muitas informações, por isso precisamos filtrá-lo por meio de expressões regulares.
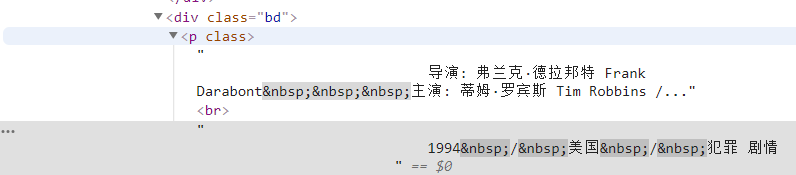
info=each.find('div',class_='bd').p.text.strip()Primeiro, encontramos todo o conteúdo dessa tag e, em seguida, filtramos as informações irrelevantes por meio de expressões regulares.
info=info.replace('n',)#Filtrar retornos de carro info=info.replace(,)#Filtrar espaços info=info.replace(xa0,)#Filtrar caracteres de espaço em branco ininterruptos director=re.findall( r '[Diretor:].+[Estrelando:]',info)[0]diretor=diretor[3:len(diretor)-6]Em seguida, defina-o como um item do dicionário.
filme['diretor']=diretor#Um item no dicionário
Podemos descobrir que o tipo de filme também está nesta tag 'p', e também obtemos essa informação diretamente por meio de expressões regulares.
plot=re.findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index('/') +1:]plot=plot[plot.index('/')+1:]movie['plot']=plot#Adicionar como um item no dicionárioFinalmente, bloqueie as informações de classificação.
star=each.find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()Em seguida, continue salvando-o na forma de um dicionário.
filme['estrela']=estrela
Por fim, adicione este dicionário à lista e repita a saída.
movies.append(movie)#Adicione o dicionário à lista foriinmovies:#Atravesse a saída print(i)
importreimportrequestsfrombs4importBeautifulSoupforiinrange(1):headers={#Simular navegador para acessar'user-agent':'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/52.0.2743.82Safari/537. 36','Host':'movie.douban.com'}res='https://movie.douban.com/top250?start='+str(25*i)#25 vezes r=requests.get(res ,headers=headers,timeout=10)#Defina o tempo limite sopa=BeautifulSoup(r.text,html.parser)#Defina o método de análise, outros métodos também podem ser usados. div_list=soup.find_all('div',class_='item')movies=[]foreachindiv_list:movie={}moviename=each.find('div',class_='hd').a.span.text.strip ()movie['title']=movienamerank=each.find('div',class_='pic').em.text .strip()movie['rank']=rankinfo=each.find('div',class_='bd').p.text.strip()info=info.replace('n',)info=info .replace(,)info=info.replace(xa0,)director=re.findall(r'[Diretor:].+[Estrelando:]',info)[0]diretor=diretor [3:len(diretor)-6]filme['diretor']=diretorrelease_date=re.findall(r'[0-9]{4}',info)[0]filme['release_date']=release_dateplot=re .findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index(' /')+1:]plot=plot[plot.index('/')+1:]movie['plot']=plotstar=each.find('div',class_='star')star=star. find('span',class_='rating_num').text.strip()movie['star']=starmovies.append(movie)foriinmovies:print(i)Console:

Neste exemplo, aprendemos principalmente como encontrar as informações correspondentes no código-fonte da página da web, o que pode nos ajudar a localizá-las rapidamente e, em seguida, combiná-las com expressões regulares para completar a correspondência das informações. salvará esses dados no banco de dados.