O mais recente modelo de linguagem multimodal BLIP-3-Video lançado pela equipe de pesquisa da Salesforce AI fornece uma solução para processar com eficiência os crescentes dados de vídeo. Este modelo visa melhorar a eficiência e o efeito da compreensão do vídeo e é amplamente utilizado em áreas como direção autônoma e entretenimento, trazendo inovação para todas as esferas da vida. O editor de Downcodes explicará em detalhes a tecnologia central e o excelente desempenho do BLIP-3-Video.
Recentemente, a equipe de pesquisa da Salesforce AI lançou um novo modelo de linguagem multimodal – BLIP-3-Video. Com o rápido aumento do conteúdo de vídeo, como processar dados de vídeo de forma eficiente tornou-se um problema urgente a ser resolvido. O surgimento deste modelo visa melhorar a eficiência e eficácia da compreensão de vídeo e é adequado para diversos setores, desde direção autônoma até entretenimento.
Os modelos tradicionais de compreensão de vídeo geralmente processam vídeos quadro a quadro e geram uma grande quantidade de informações visuais. Este processo não só consome muitos recursos computacionais, mas também limita bastante a capacidade de processar vídeos longos. À medida que a quantidade de dados de vídeo continua a crescer, esta abordagem torna-se cada vez mais ineficiente, por isso é fundamental encontrar uma solução que capture as principais informações do vídeo e, ao mesmo tempo, reduza a carga computacional.
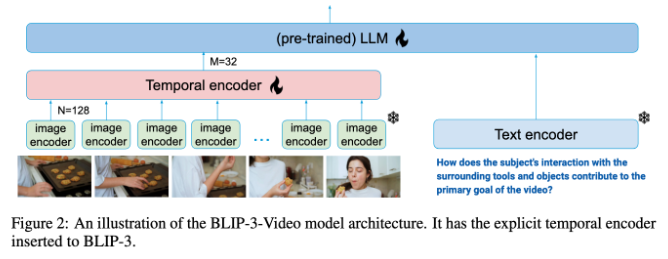
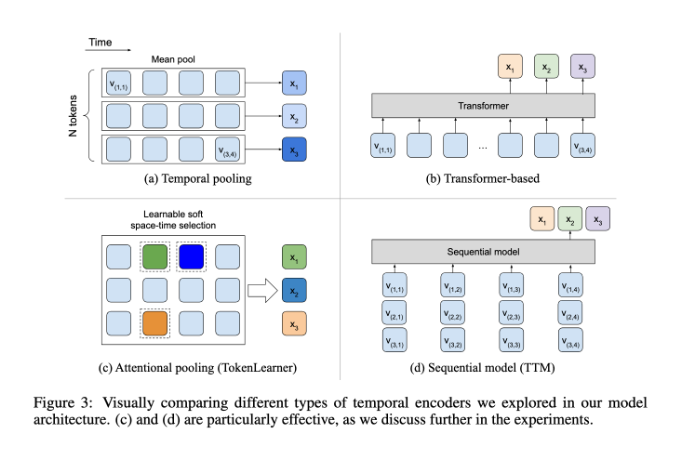
Neste aspecto, o BLIP-3-Video tem um desempenho muito bom. Este modelo reduz com sucesso a quantidade de informação visual necessária no vídeo para 16 a 32 marcadores visuais, introduzindo um “codificador temporal”. Este design inovador melhora muito a eficiência computacional, permitindo que o modelo conclua tarefas complexas de vídeo a um custo menor. Este codificador temporal emprega um mecanismo de agrupamento de atenção espaço-temporal que pode ser aprendido que extrai as informações mais importantes de cada quadro e as integra em um conjunto compacto de marcadores visuais.
BLIP-3-Video também funciona muito bem. Ao comparar com outros modelos de grande escala, o estudo descobriu que a precisão deste modelo em tarefas de resposta a perguntas em vídeo é comparável à dos modelos de topo. Por exemplo, o modelo Tarsier-34B requer 4.608 marcadores para processar 8 quadros de vídeo, enquanto o BLIP-3-Video precisa apenas de 32 marcadores para atingir uma pontuação de benchmark MSVD-QA de 77,7%. Isto mostra que o BLIP-3-Video reduz significativamente o consumo de recursos enquanto mantém o alto desempenho.
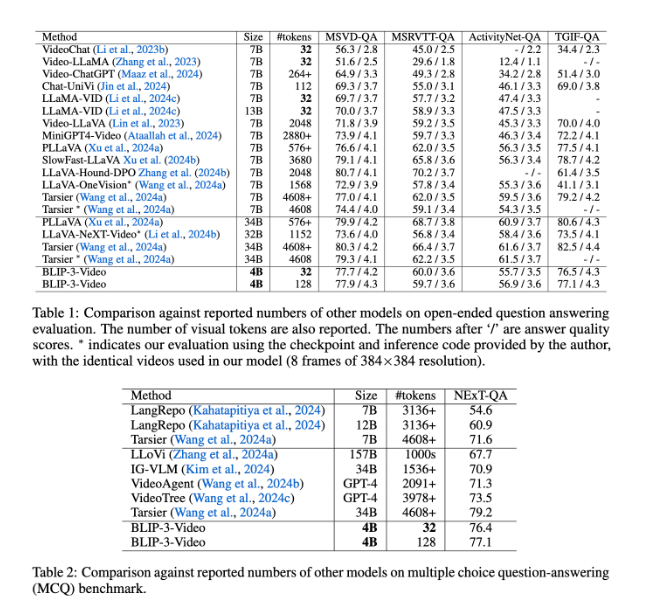
Além disso, o desempenho do BLIP-3-Video em tarefas de perguntas e respostas de múltipla escolha não pode ser subestimado. No conjunto de dados NExT-QA, o modelo alcançou uma pontuação alta de 77,1%, e no conjunto de dados TGIF-QA, também alcançou uma precisão de 77,1%. Esses dados demonstram a eficiência do BLIP-3-Video no tratamento de problemas complexos de vídeo.

BLIP-3-Video abre novas possibilidades no processamento de vídeo com seu inovador codificador de temporização. O lançamento deste modelo não só melhora a eficiência da compreensão do vídeo, mas também oferece mais possibilidades para futuras aplicações de vídeo.
Entrada do projeto: https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html
O BLIP-3-Video fornece uma nova direção para o desenvolvimento futuro da tecnologia de vídeo com seus eficientes recursos de processamento de vídeo. Seu excelente desempenho em tarefas de perguntas e respostas de vídeo e perguntas e respostas de múltipla escolha demonstra seu enorme potencial em economia de recursos e melhoria de desempenho. Esperamos que o BLIP-3-Video desempenhe um papel em mais campos e promova o avanço da tecnologia de vídeo.