O editor do Downcodes irá explicar a você os últimos resultados de pesquisas da Universidade de Princeton e da Universidade de Yale! Esta pesquisa explora profundamente as capacidades de raciocínio da "Cadeia de Pensamento (CoT)" de grandes modelos de linguagem (LLM), revelando que o raciocínio CoT não é uma simples aplicação de regras lógicas, mas uma fusão complexa de múltiplos fatores, como memória, probabilidade e raciocínio de ruído. Os pesquisadores selecionaram a tarefa de quebra de cifra de deslocamento e conduziram uma análise aprofundada de três LLMs: GPT-4, Claude3 e Llama3.1. Finalmente, eles descobriram três fatores-chave que afetam o efeito de inferência do CoT e propuseram o mecanismo de inferência do LLM. novos insights.
Pesquisadores da Universidade de Princeton e da Universidade de Yale divulgaram recentemente um relatório sobre as capacidades de raciocínio da "Cadeia de Pensamento (CoT)" de grandes modelos de linguagem (LLM), revelando o segredo do raciocínio CoT: não é um raciocínio puramente simbólico baseado em regras lógicas, mas Ele combina vários fatores, como memória, probabilidade e raciocínio de ruído.
Os pesquisadores usaram a quebra da cifra de deslocamento como tarefa de teste e analisaram o desempenho de três LLMs: GPT-4, Claude3 e Llama3.1. Uma cifra de deslocamento é uma codificação simples em que cada letra é substituída por uma letra deslocada para frente em um número fixo de casas no alfabeto. Por exemplo, mova o alfabeto 3 casas para frente e CAT se torna FDW.
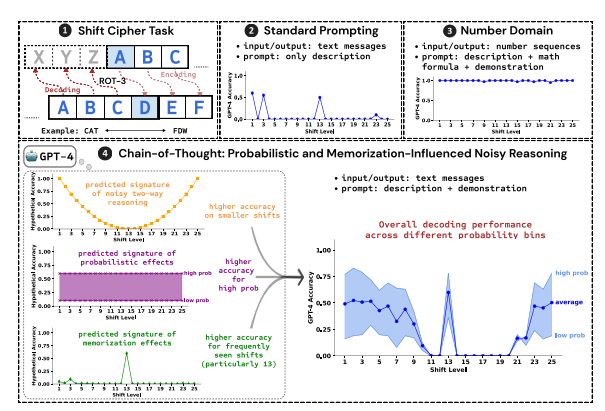
Os resultados da pesquisa mostram que os três fatores principais que afetam o efeito do raciocínio CoT são:
Probabilístico: o LLM prefere gerar resultados de probabilidade mais alta, mesmo que as etapas de inferência levem a respostas de probabilidade mais baixa. Por exemplo, se a etapa de inferência aponta para STAZ, mas STAY é uma palavra mais comum, LLM pode "autocorrigir-se" e gerar STAY.
Memória: o LLM lembra uma grande quantidade de dados de texto durante o pré-treinamento, o que afeta a precisão de sua inferência CoT. Por exemplo, rot-13 é a cifra de deslocamento mais comum, e a precisão do LLM no rot-13 é significativamente maior do que outros tipos de cifras de deslocamento.
Inferência de ruído: O processo de inferência do LLM não é totalmente preciso, mas existe um certo grau de ruído. À medida que a quantidade de deslocamento da cifra de deslocamento aumenta, as etapas intermediárias necessárias para a decodificação também aumentam, e o impacto da inferência de ruído torna-se mais óbvio, fazendo com que a precisão do LLM diminua.
Os pesquisadores também descobriram que o raciocínio CoT do LLM depende do autocondicionamento, ou seja, o LLM precisa gerar explicitamente o texto como contexto para as etapas de raciocínio subsequentes. Se o LLM for instruído a “pensar silenciosamente” sem produzir nenhum texto, sua capacidade de raciocínio será significativamente reduzida. Além disso, a eficácia das etapas de demonstração tem pouco impacto no raciocínio do CoT. Mesmo que haja erros nas etapas de demonstração, o efeito do raciocínio do CoT do LLM ainda pode permanecer estável.
Este estudo mostra que o raciocínio CoT do LLM não é um raciocínio simbólico perfeito, mas incorpora múltiplos fatores, como memória, probabilidade e raciocínio de ruído. LLM mostra as características de um mestre de memória e de um mestre de probabilidade durante o processo de raciocínio CoT. Esta pesquisa nos ajuda a obter uma compreensão mais profunda das capacidades de raciocínio do LLM e fornece insights valiosos para o desenvolvimento de sistemas de IA mais poderosos no futuro.
Endereço do artigo: https://arxiv.org/pdf/2407.01687
Este relatório de pesquisa fornece uma referência valiosa para compreendermos o mecanismo de raciocínio da "cadeia de pensamento" de grandes modelos de linguagem e também fornece uma nova direção para o design e otimização de futuros sistemas de IA. O editor de Downcodes continuará atento aos desenvolvimentos de ponta no campo da inteligência artificial e trará a você conteúdos mais interessantes!