A equipe de pesquisa do Instituto de Inovação em Computação da Universidade de Zhejiang fez um avanço na solução do problema de capacidade insuficiente de grandes modelos de linguagem para processar dados tabulares e lançou um novo modelo TableGPT2. Com seu codificador de tabela exclusivo, o TableGPT2 pode processar com eficiência vários dados de tabela, trazendo mudanças revolucionárias para aplicativos orientados a dados, como business intelligence (BI). O editor de Downcodes explicará em detalhes a inovação e a direção de desenvolvimento futuro do TableGPT2.
A ascensão de grandes modelos de linguagem (LLMs) trouxe mudanças revolucionárias às aplicações de inteligência artificial. No entanto, eles apresentam deficiências óbvias no processamento de dados tabulares. Para resolver este problema, uma equipa de investigação do Instituto de Inovação em Computação da Universidade de Zhejiang lançou um novo modelo denominado TableGPT2, que pode integrar e processar dados tabulares de forma direta e eficiente, abrindo novos caminhos para a inteligência empresarial (BI) e outras soluções baseadas em dados. novas possibilidades.
A principal inovação do TableGPT2 reside em seu codificador de tabela exclusivo, que é especialmente projetado para capturar as informações estruturais e de conteúdo da célula da tabela, aumentando assim a capacidade do modelo de lidar com consultas difusas, nomes de colunas ausentes e tabelas irregulares que são comuns no mundo real. - aplicações mundiais. TableGPT2 é baseado na arquitetura Qwen2.5 e passou por pré-treinamento e ajuste fino em grande escala, envolvendo mais de 593.800 tabelas e 2,36 milhões de tuplas de saída de tabela de consulta de alta qualidade, que é uma escala sem precedentes de tabelas relacionadas dados em pesquisas anteriores.
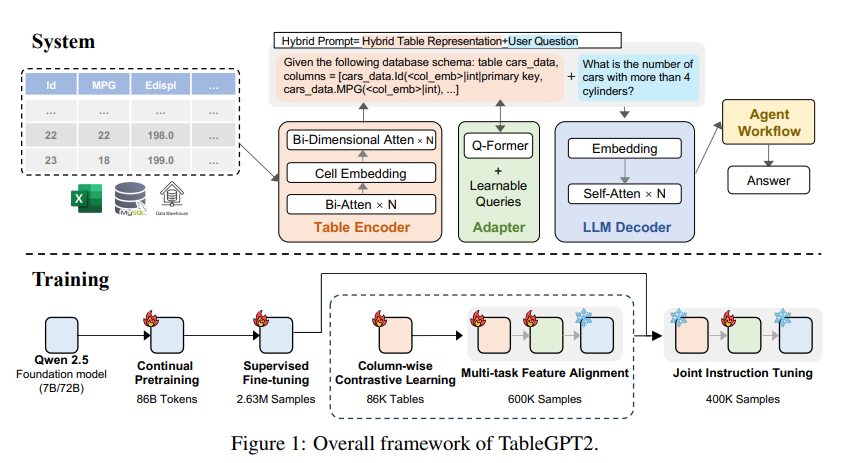
A fim de melhorar as capacidades de codificação e raciocínio do TableGPT2, os pesquisadores realizaram um pré-treinamento contínuo (CPT), no qual 80% dos dados são códigos cuidadosamente anotados para garantir que tenham fortes capacidades de codificação. Além disso, eles também coletaram uma grande quantidade de dados de inferência e livros contendo conhecimento específico do domínio para aprimorar as capacidades de inferência do modelo. Os dados finais do CPT contêm 86 bilhões de tokens estritamente filtrados, que fornecem os recursos necessários de codificação e raciocínio para o TableGPT2 lidar com tarefas complexas de BI e outras tarefas relacionadas.
Para resolver as limitações do TableGPT2 na adaptação a tarefas e cenários específicos de BI, os pesquisadores realizaram o ajuste fino supervisionado (SFT) nele. Eles construíram um conjunto de dados que abrange uma variedade de cenários críticos e do mundo real, incluindo diversas rodadas de conversas, raciocínio complexo, uso de ferramentas e consultas altamente voltadas para os negócios. O conjunto de dados combina anotação manual com um processo de anotação automatizado orientado por especialistas para garantir a qualidade e relevância dos dados. O processo SFT, utilizando um total de 2,36 milhões de amostras, aprimorou ainda mais o modelo para atender às necessidades específicas de BI e outros ambientes que envolvem tabelas.
TableGPT2 também introduz de forma inovadora um codificador de tabela semântica que toma a tabela inteira como entrada e gera um conjunto compacto de vetores de incorporação para cada coluna. Essa arquitetura é customizada para as propriedades exclusivas dos dados tabulares, capturando efetivamente os relacionamentos entre linhas e colunas por meio de um mecanismo de atenção bidirecional e um processo hierárquico de extração de recursos. Além disso, um método de aprendizagem contrastivo colunar é adotado para encorajar o modelo a aprender representações semânticas tabulares significativas e com reconhecimento de estrutura.
Para integrar perfeitamente o TableGPT2 com ferramentas de análise de dados de nível empresarial, os pesquisadores também desenvolveram uma estrutura de tempo de execução de fluxo de trabalho de agente. A estrutura consiste em três componentes principais: engenharia de dicas de tempo de execução, sandbox de código seguro e módulo de avaliação de agente, que juntos aprimoram os recursos e a confiabilidade do agente. Os fluxos de trabalho suportam tarefas complexas de análise de dados por meio de etapas modulares (normalização de entrada, execução de agente e invocação de ferramenta) que funcionam em conjunto para gerenciar e monitorar o desempenho do agente. Ao integrar a geração aumentada de recuperação (RAG) para recuperação contextual eficiente e sandbox de código para execução segura, a estrutura garante que o TableGPT2 forneça insights precisos e sensíveis ao contexto em problemas do mundo real.
Os pesquisadores conduziram uma avaliação extensiva do TableGPT2 em uma variedade de benchmarks tabulares e de uso geral amplamente usados. Os resultados mostram que o TableGPT2 se destaca na compreensão, processamento e raciocínio de tabelas, com uma melhoria média de desempenho de 35,20% para um modelo de 7 bilhões de parâmetros, 720. O desempenho médio do modelo de 100 milhões de parâmetros aumentou 49,32%, mantendo ao mesmo tempo um forte desempenho geral. Para uma avaliação justa, eles compararam o TableGPT2 apenas com modelos de código aberto e neutros em termos de benchmark, como Qwen e DeepSeek, garantindo desempenho equilibrado e versátil do modelo em uma variedade de tarefas sem superajuste de nenhum teste de benchmark. Eles também introduziram e lançaram parcialmente um novo benchmark, RealTabBench, que enfatiza tabelas não convencionais, campos anônimos e consultas complexas para ser mais consistente com cenários da vida real.
Embora o TableGPT2 atinja desempenho de última geração em experimentos, ainda existem desafios na implantação do LLM em ambientes de BI do mundo real. Os pesquisadores observaram que as direções de pesquisas futuras incluem:
Codificação específica de domínio: permite que o LLM adapte rapidamente linguagens específicas de domínio (DSLs) ou pseudocódigos específicos da empresa para melhor atender às necessidades específicas da infraestrutura de dados corporativos.
Design multiagente: explore como integrar efetivamente vários LLMs em um sistema unificado para lidar com a complexidade dos aplicativos do mundo real.
Processamento versátil de tabelas: melhore a capacidade do modelo de lidar com tabelas irregulares, como células mescladas e estruturas inconsistentes comuns no Excel e no Pages, para lidar melhor com diversas formas de dados tabulares no mundo real.
O lançamento do TableGPT2 marca o progresso significativo do LLM no processamento de dados tabulares, trazendo novas possibilidades para business intelligence e outras aplicações baseadas em dados. Acredito que à medida que a investigação continua a se aprofundar, o TableGPT2 desempenhará um papel cada vez mais importante no campo da análise de dados no futuro.
Endereço do artigo: https://arxiv.org/pdf/2411.02059v1
O surgimento do TableGPT2 trouxe um novo amanhecer ao campo da inteligência de negócios. Seus recursos eficientes de processamento de dados de tabela e forte escalabilidade indicam que a análise de dados será mais inteligente e conveniente no futuro. Esperamos que o TableGPT2 seja mais amplamente utilizado no futuro e agregue mais valor a todas as esferas da vida.