O editor do Downcodes aprendeu que a equipe de pesquisa chinesa criou com sucesso o maior conjunto público de dados de IA multimodal "Infinity-MM" e treinou um pequeno modelo Aquila-VL-2B com excelente desempenho com base neste conjunto de dados. O modelo obteve excelentes resultados em vários testes de benchmark, demonstrando o enorme potencial dos dados sintéticos na melhoria do desempenho dos modelos de IA. O conjunto de dados Infinity-MM contém vários tipos de dados, como descrições de imagens e dados de instruções visuais. Seu processo de geração utiliza modelos de IA de código aberto, como RAM++ e MiniCPM-V, e passa por processamento em vários níveis para garantir a qualidade e diversidade dos dados. O modelo Aquila-VL-2B é baseado na arquitetura LLaVA-OneVision e usa Qwen-2.5 como modelo de linguagem.
Recentemente, equipes de pesquisa de várias instituições chinesas criaram com sucesso o conjunto de dados "Infinity-MM", que é atualmente um dos maiores conjuntos públicos de dados multimodais de IA, e treinaram um pequeno novo modelo com excelente desempenho - —Aquila-VL-2B .
O conjunto de dados contém principalmente quatro categorias principais de dados: 10 milhões de descrições de imagens, 24,4 milhões de dados de instruções visuais gerais, 6 milhões de dados de instruções selecionados de alta qualidade e 3 milhões de dados gerados por GPT-4 e outros modelos de IA.
Do lado da geração, a equipe de pesquisa aproveitou os modelos existentes de IA de código aberto. Primeiramente, o modelo RAM++ analisa a imagem e extrai informações importantes, gerando posteriormente perguntas e respostas relevantes. Além disso, a equipe construiu um sistema de classificação especial para garantir a qualidade e diversidade dos dados gerados.
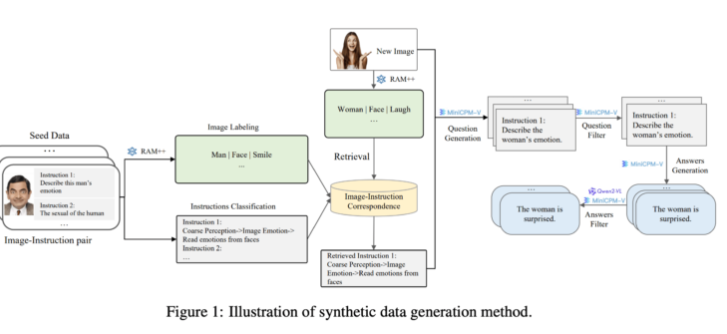
Este método de geração de dados sintéticos usa um método de processamento multinível, combinando modelos RAM++ e MiniCPM-V para fornecer dados de treinamento precisos para o sistema de IA por meio de reconhecimento de imagem, classificação de instruções e geração de respostas.
O modelo Aquila-VL-2B é baseado na arquitetura LLaVA-OneVision, usa Qwen-2.5 como modelo de linguagem e usa SigLIP para processamento de imagens. O treinamento do modelo é dividido em quatro etapas, aumentando gradativamente a complexidade. Na primeira etapa, o modelo aprende associações básicas de imagem-texto; as etapas subsequentes incluem tarefas gerais de visão, execução de instruções específicas e, finalmente, a integração dos dados gerados sintetizados. A resolução da imagem também melhora gradativamente durante o treinamento.
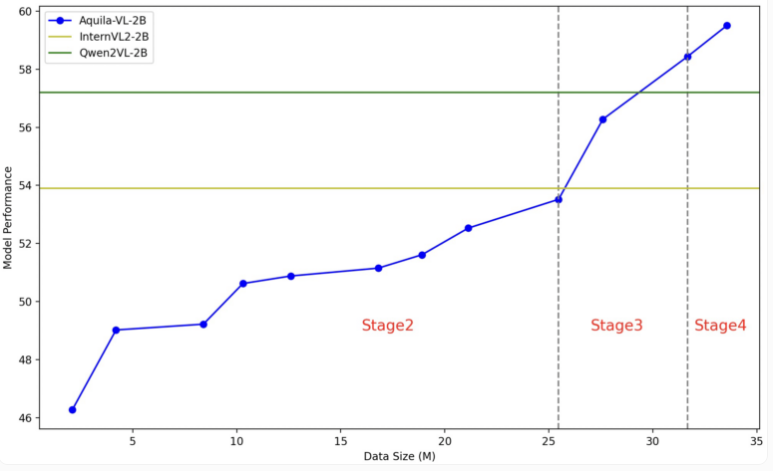
No teste, o Aquila-VL-2B obteve o melhor resultado no teste multimodal baseado em MMStar com pontuação de 54,9%, com volume de apenas 2 bilhões de parâmetros. Além disso, o modelo teve um desempenho particularmente bom em tarefas matemáticas, pontuando 59% no teste MathVista, superando em muito sistemas similares.
No teste geral de compreensão de imagem, o Aquila-VL-2B também teve um bom desempenho, com pontuação HalllusionBench de 43% e pontuação MMBench de 75,2%. Os pesquisadores afirmaram que a adição de dados gerados sinteticamente melhorou significativamente o desempenho do modelo. Sem o uso desses dados adicionais, o desempenho médio do modelo teria caído 2,4%.
Desta vez, a equipe de pesquisa decidiu abrir o conjunto de dados e o modelo para a comunidade de pesquisa. O processo de treinamento usou principalmente Nvidia A100GPU e chips locais chineses. O lançamento bem-sucedido do Aquila-VL-2B mostra que os modelos de código aberto estão gradualmente acompanhando a tendência dos sistemas tradicionais de código fechado na pesquisa de IA, mostrando especialmente boas perspectivas na utilização de dados de treinamento sintéticos.
Entrada de papel Infinity-MM: https://arxiv.org/abs/2410.18558
Entrada do projeto Aquila-VL-2B: https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen
O sucesso do Aquila-VL-2B não só prova a força técnica da China no campo da IA, mas também fornece recursos valiosos para a comunidade de código aberto. O seu desempenho eficiente e a sua estratégia aberta promoverão o desenvolvimento da tecnologia de IA multimodal, e vale a pena aguardar com expectativa as suas futuras aplicações em mais domínios.