A compreensão de vídeo ultralongo sempre foi um problema difícil para modelos multimodais de linguagem grande (MLLM). Os modelos existentes são difíceis de processar dados de vídeo que excedem o comprimento máximo do contexto, e a atenuação da informação e os altos custos computacionais também são um grande desafio. O editor do Downcodes descobriu que o Instituto de Pesquisa Zhiyuan e várias universidades propuseram um modelo de linguagem visual ultralongo chamado Video-XL, projetado para lidar com eficiência com problemas de compreensão de vídeo em nível de hora. A tecnologia central deste modelo é o "resumo latente do contexto visual", que utiliza habilmente os recursos de modelagem de contexto do LLM para compactar longas representações visuais em uma forma mais compacta, semelhante a condensar uma vaca inteira em uma tigela de essência de carne bovina, tornando o modelo mais eficiente. Absorver informações importantes.
Atualmente, os modelos multimodais de linguagem grande (MLLM) fizeram progressos significativos no campo da compreensão de vídeo, mas o processamento de vídeos extremamente longos ainda é um desafio. Isso ocorre porque o MLLM normalmente tem dificuldade para lidar com milhares de tokens visuais que excedem o comprimento máximo do contexto e sofre com a deterioração das informações causada pela agregação de tokens. Ao mesmo tempo, um grande número de tags de vídeo também trará altos custos computacionais.
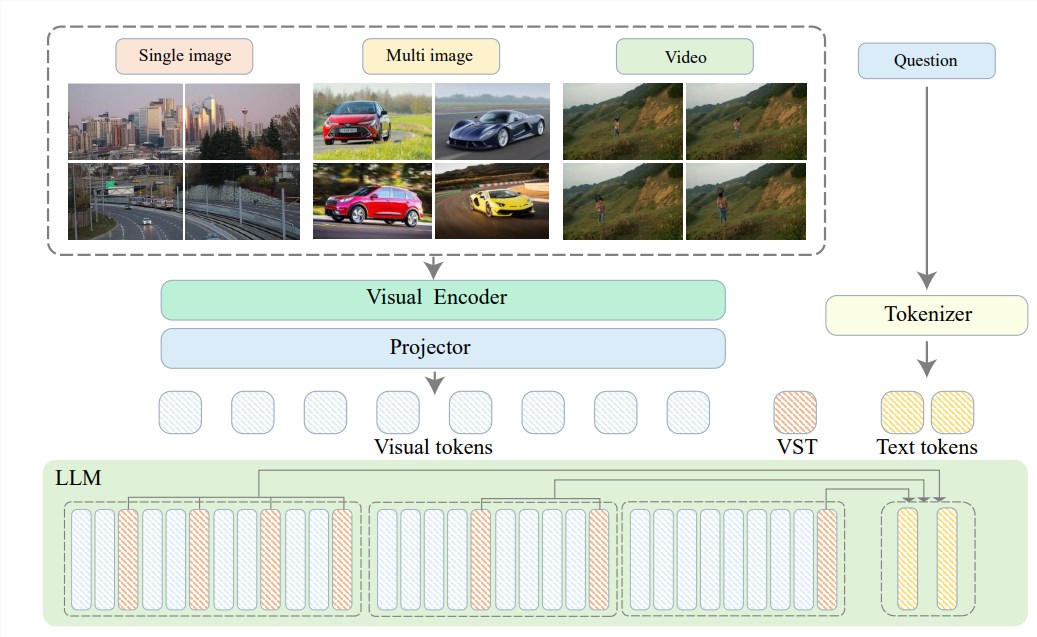
Para resolver esses problemas, o Instituto de Pesquisa Zhiyuan se uniu à Universidade Jiao Tong de Xangai, à Universidade Renmin da China, à Universidade de Pequim, à Universidade de Correios e Telecomunicações de Pequim e outras universidades para propor o Video-XL, um sistema de ultra-alta definição projetado para compreensão eficiente de vídeo em nível de hora. O núcleo do Video-XL está na tecnologia de "resumo latente de contexto visual", que aproveita os recursos inerentes de modelagem de contexto do LLM para compactar com eficácia representações visuais longas em um formato mais compacto.
Simplificando, trata-se de compactar o conteúdo do vídeo de uma forma mais simplificada, como condensar uma vaca inteira em uma tigela de essência de carne bovina, que é mais fácil para o modelo digerir e absorver.
Esta tecnologia de compressão não só melhora a eficiência, mas também preserva eficazmente as principais informações do vídeo. Você sabe, vídeos longos costumam ser repletos de informações redundantes, como a palmilha de uma senhora idosa, longa e fedorenta. O Video-XL pode eliminar com precisão essas informações inúteis e reter apenas as partes essenciais, o que garante que o modelo não se perderá na compreensão de conteúdos de vídeo longos.
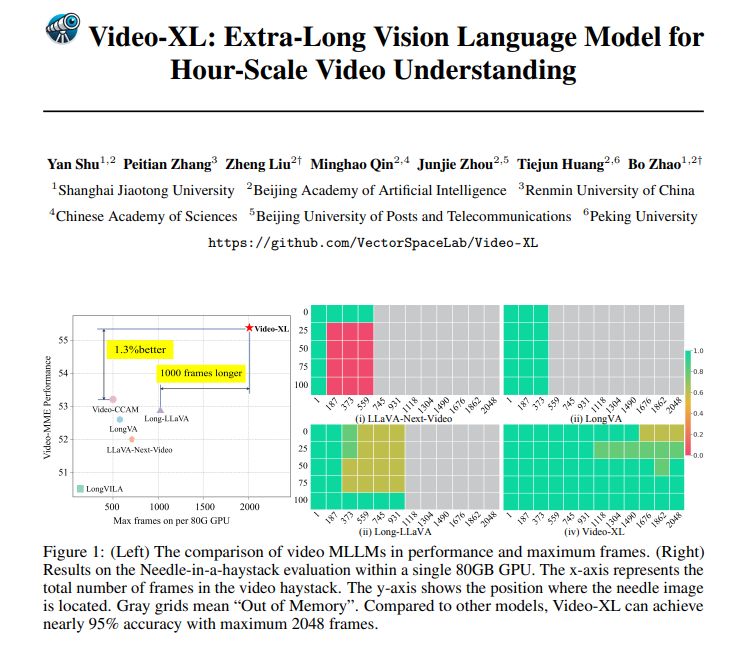
O Video-XL não é apenas excelente na teoria, mas também bastante capaz na prática. O Video-XL alcançou resultados líderes em vários benchmarks de compreensão de vídeos longos, especialmente no teste VNBench, onde sua precisão é quase 10% maior do que os melhores métodos existentes.
Ainda mais impressionante, o Video-XL atinge um equilíbrio incrível entre eficiência e eficácia, capaz de processar 2.048 quadros de vídeo em uma única GPU de 80 GB, mantendo quase 95% de precisão na avaliação da "agulha no palheiro".
Video-XL também tem amplas perspectivas de aplicação. Além de ser capaz de compreender vídeos longos em geral, também é capaz de realizar tarefas específicas, como resumo de filmes, detecção de anomalias de vigilância e reconhecimento de posicionamento de anúncios.
Isso significa que você não precisará mais suportar longas tramas ao assistir filmes no futuro. Você pode usar o Video-XL diretamente para gerar um resumo simplificado, economizando tempo e esforço, ou pode usá-lo para monitorar imagens de vigilância e identificar automaticamente eventos anormais; , que é muito mais eficiente que o rastreamento manual.
Endereço do projeto: https://github.com/VectorSpaceLab/Video-XL
Artigo: https://arxiv.org/pdf/2409.14485
Video-XL fez um progresso revolucionário no campo da compreensão de vídeos ultralongos. Sua combinação perfeita de eficiência e precisão fornece uma nova solução para processamento de vídeos longos. Ele tem amplas perspectivas de aplicação no futuro e vale a pena esperar!