O treinamento de modelos grandes é demorado e trabalhoso. Como melhorar a eficiência e reduzir o consumo de energia tornou-se uma questão fundamental no campo da IA. AdamW, como otimizador padrão para pré-treinamento do Transformer, é gradualmente incapaz de lidar com modelos cada vez maiores. O editor de Downcodes levará você a conhecer um novo otimizador desenvolvido por uma equipe chinesa - C-AdamW. Com sua estratégia "cautelosa", reduz bastante o consumo de energia, garantindo velocidade e estabilidade de treinamento, além de trazer grandes benefícios para o treinamento de grandes modelos. . para revolucionar a mudança.
No mundo da IA, trabalhar arduamente para conseguir milagres parece ser a regra de ouro. Quanto maior o modelo, mais dados e mais forte o poder computacional, mais próximo ele parece estar do Santo Graal da inteligência. Contudo, por detrás deste rápido desenvolvimento, existem também enormes pressões sobre os custos e o consumo de energia.
Para tornar o treinamento em IA mais eficiente, os cientistas têm procurado otimizadores mais poderosos, como um treinador, para orientar os parâmetros do modelo para otimizar continuamente e, finalmente, alcançar o melhor estado. AdamW, como otimizador padrão para pré-treinamento do Transformer, tem sido referência no setor há muitos anos. No entanto, face à escala cada vez maior do modelo, AdamW também começou a parecer incapaz de lidar com as suas capacidades.
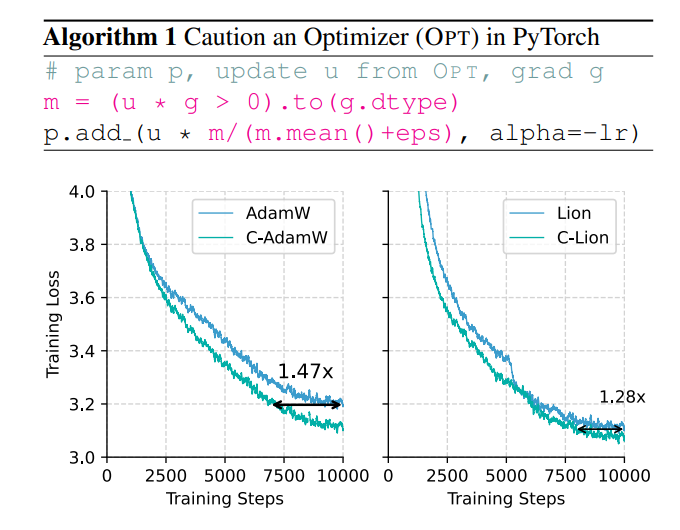
Não existe uma maneira de aumentar a velocidade de treinamento e ao mesmo tempo reduzir o consumo de energia? Não se preocupe, uma equipe totalmente chinesa está aqui com sua arma secreta C-AdamW!
O nome completo de C-AdamW é Cautious AdamW, e seu nome chinês é Cautious AdamW. Não parece muito budista? Sim, a ideia central de C-AdamW é pensar duas vezes antes de agir.

Imagine que os parâmetros do modelo são como um grupo de crianças enérgicas que sempre querem correr. AdamW é como um professor dedicado, tentando guiá-los na direção certa. Mas às vezes as crianças ficam muito entusiasmadas e correm na direção errada, desperdiçando tempo e energia.
Neste momento, C-AdamW é como um ancião sábio com um par de olhos penetrantes, capaz de identificar com precisão se a direção da atualização está correta. Se a direção estiver errada, C-AdamW irá parar de forma decisiva para evitar que o modelo siga na estrada errada.
Esta estratégia cautelosa garante que cada atualização possa efetivamente reduzir a função de perda, acelerando assim a convergência do modelo. Resultados experimentais mostram que C-AdamW aumenta a velocidade de treinamento para 1,47 vezes no pré-treinamento Llama e MAE!
Mais importante ainda, o C-AdamW quase não requer sobrecarga computacional adicional e pode ser implementado com uma simples modificação de uma linha do código existente. Isso significa que os desenvolvedores podem aplicar facilmente o C-AdamW a vários treinamentos de modelos e aproveitar a velocidade e a paixão!
A grande vantagem do C-AdamW é que ele mantém a função hamiltoniana de Adam e não destrói a garantia de convergência sob a análise de Lyapunov. Isso significa que o C-AdamW não só é mais rápido, mas também tem estabilidade garantida e não haverá problemas como travamentos de treinamento.
É claro que ser budista não significa que você não seja empreendedor. A equipe de pesquisa afirmou que continuará a explorar funções ϕ mais ricas e a aplicar máscaras no espaço de recursos em vez do espaço de parâmetros para melhorar ainda mais o desempenho do C-AdamW.
É previsível que o C-AdamW se torne o novo favorito no campo da aprendizagem profunda, trazendo mudanças revolucionárias ao treinamento de grandes modelos!
Endereço do artigo: https://arxiv.org/abs/2411.16085
Github:
https://github.com/kyleliang919/C-Optim
O surgimento do C-AdamW fornece novas idéias para resolver os problemas de eficiência de treinamento de modelos grandes e consumo de energia. Sua alta eficiência, estabilidade e características fáceis de usar o tornam muito promissor para aplicação. Espera-se que o C-AdamW possa ser aplicado em mais campos no futuro e promova o desenvolvimento contínuo da tecnologia de IA. O editor do Downcodes continuará atento aos avanços tecnológicos relevantes, portanto fique atento!