O editor do Downcodes soube que a Universidade de Pequim e outras equipes de pesquisa científica lançaram o LLaVA-o1, um modelo de código aberto multimodal de referência. O modelo superou concorrentes como Gemini, GPT-4o-mini e Llama em vários testes de benchmark, e seu mecanismo de raciocínio de "pensamento lento" permitiu realizar raciocínios mais complexos, comparável ao GPT-o1. O código aberto do LLaVA-o1 trará uma nova vitalidade à pesquisa e aplicação no campo da IA multimodal.
Recentemente, a Universidade de Pequim e outras equipes de pesquisa científica anunciaram o lançamento de um modelo multimodal de código aberto chamado LLaVA-o1, que é considerado o primeiro modelo de linguagem visual capaz de raciocínio espontâneo e sistemático, comparável ao GPT-o1.
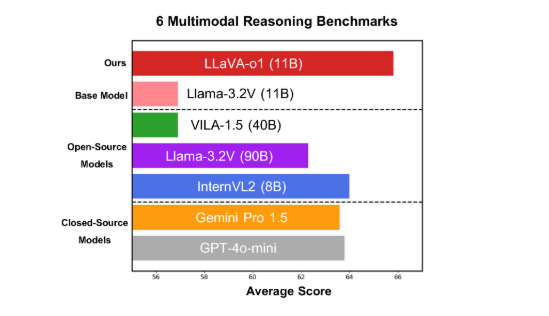
O modelo tem um bom desempenho em seis benchmarks multimodais desafiadores, com sua versão de parâmetro 11B superando outros concorrentes, como Gemini-1.5-pro, GPT-4o-mini e Llama-3.2-90B-Vision-Instruct.
LLaVA-o1 é baseado no modelo Llama-3.2-Vision e adota um mecanismo de raciocínio de "pensamento lento", que pode conduzir de forma independente processos de raciocínio mais complexos, superando o método tradicional de alerta de cadeia de pensamento.
No benchmark de inferência multimodal, o LLaVA-o1 superou seu modelo base em 8,9%. O modelo é único porque seu processo de raciocínio é dividido em quatro etapas: resumo, explicação visual, raciocínio lógico e geração de conclusões. Nos modelos tradicionais, o processo de raciocínio é muitas vezes relativamente simples e pode facilmente levar a respostas erradas, enquanto o LLaVA-o1 garante resultados mais precisos através de um raciocínio estruturado em várias etapas.
Por exemplo, ao resolver o problema "Quantos objetos restam após subtrair todas as pequenas bolas brilhantes e objetos roxos?", o LLaVA-o1 irá primeiro resumir o problema, depois extrair informações da imagem e, em seguida, realizar o raciocínio passo a passo e, finalmente, dê a resposta. Esta abordagem por etapas melhora as capacidades de raciocínio sistemático do modelo, tornando-o mais eficiente no tratamento de problemas complexos.

Vale ressaltar que o LLaVA-o1 introduz um método de busca de feixe em nível de estágio no processo de inferência. Esta abordagem permite que o modelo gere múltiplas respostas candidatas em cada estágio de inferência e selecione a melhor resposta para prosseguir para o próximo estágio de inferência, melhorando significativamente a qualidade geral da inferência. Com ajuste fino supervisionado e dados de treinamento razoáveis, o LLaVA-o1 tem um bom desempenho em comparações com modelos maiores ou de código fechado.
Os resultados da pesquisa da equipe da Universidade de Pequim não apenas promovem o desenvolvimento de IA multimodal, mas também fornecem novas ideias e métodos para futuros modelos de compreensão de linguagem visual. A equipe afirmou que o código, os pesos de pré-treinamento e os conjuntos de dados do LLaVA-o1 serão totalmente de código aberto e espera que mais pesquisadores e desenvolvedores explorem e apliquem em conjunto este modelo inovador.
Artigo: https://arxiv.org/abs/2411.10440
GitHub: https://github.com/PKU-YuanGroup/LLaVA-o1
O código aberto do LLaVA-o1 promoverá, sem dúvida, o desenvolvimento tecnológico e a inovação de aplicações no campo da IA multimodal. Seu eficiente mecanismo de inferência e excelente desempenho o tornam uma referência importante para futuras pesquisas de modelos de linguagem visual e é digno de atenção e antecipação. Esperamos que mais desenvolvedores participem e promovam conjuntamente o progresso da tecnologia de inteligência artificial.