O editor de Downcodes aprendeu que Meta lançou recentemente um novo comando de diálogo multi-turno multilíngue após o teste de benchmark de avaliação de habilidade Multi-IF. O benchmark cobre oito idiomas e contém 4.501 tarefas de diálogo de três rodadas, com o objetivo de avaliar de forma mais abrangente grandes. modelos de linguagem (LLM) em aplicações práticas. Ao contrário dos padrões de avaliação existentes que se concentram principalmente no diálogo de turno único e nas tarefas de idioma único, o Multi-IF se concentra em examinar a capacidade do modelo em cenários complexos de vários turnos e multilíngues, fornecendo uma direção mais clara para a melhoria do LLM.
A Meta lançou recentemente um novo teste de benchmark chamado Multi-IF, que foi projetado para avaliar a capacidade de seguimento de instruções de grandes modelos de linguagem (LLM) em conversas multi-turno e ambientes multilíngues. Este benchmark abrange oito idiomas e contém 4.501 tarefas de diálogo de três turnos, com foco no desempenho dos modelos atuais em cenários complexos de vários turnos e vários idiomas.
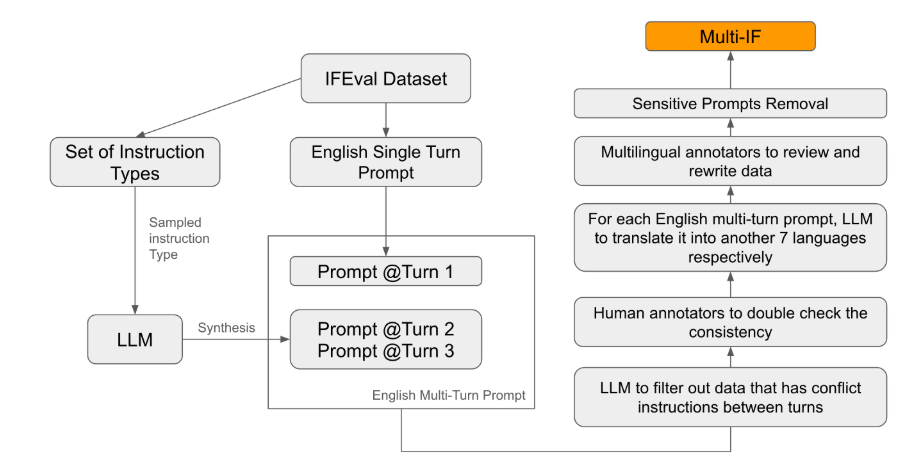
Entre os padrões de avaliação existentes, a maioria concentra-se no diálogo de turno único e nas tarefas de idioma único, que são difíceis de refletir plenamente o desempenho do modelo em aplicações práticas. O lançamento do Multi-IF visa preencher esta lacuna. A equipe de pesquisa gerou cenários de diálogo complexos ao estender uma única rodada de instruções em múltiplas rodadas de instruções e garantiu que cada rodada de instruções fosse logicamente coerente e progressiva. Além disso, o conjunto de dados também obtém suporte multilíngue por meio de etapas como tradução automática e revisão manual.
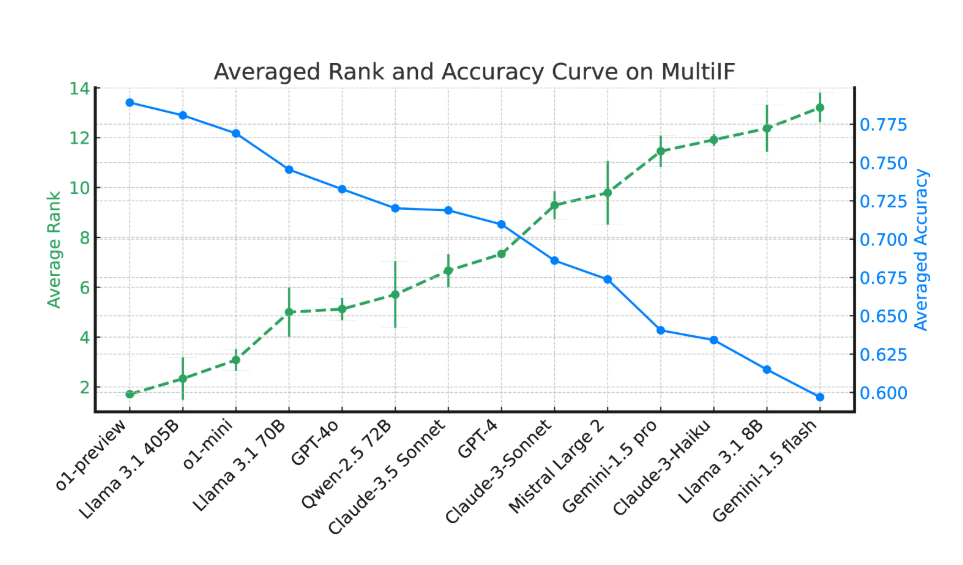
Os resultados experimentais mostram que o desempenho da maioria dos LLMs cai significativamente ao longo de múltiplas rodadas de diálogo. Tomando como exemplo o modelo o1-preview, sua precisão média na primeira rodada foi de 87,7%, mas caiu para 70,7% na terceira rodada. Principalmente em idiomas com escrita não latina, como hindi, russo e chinês, o desempenho do modelo é geralmente inferior ao do inglês, apresentando limitações em tarefas multilíngues.
Na avaliação de 14 modelos de linguagem de ponta, o1-preview e Llama3.1405B tiveram melhor desempenho, com taxas médias de precisão de 78,9% e 78,1% em três rodadas de instruções, respectivamente. No entanto, ao longo de múltiplas rondas de diálogo, todos os modelos mostraram um declínio geral na sua capacidade de seguir instruções, refletindo os desafios enfrentados pelos modelos em tarefas complexas. A equipe de pesquisa também introduziu a "Taxa de esquecimento de instruções" (IFR) para quantificar o fenômeno de esquecimento de instruções do modelo em múltiplas rodadas de diálogo. Os resultados mostram que os modelos de alto desempenho têm um desempenho relativamente bom nesse aspecto.
O lançamento do Multi-IF fornece aos pesquisadores uma referência desafiadora e promove o desenvolvimento do LLM em globalização e aplicações multilíngues. O lançamento deste benchmark não só revela as deficiências dos modelos atuais em tarefas multi-rondas e multilíngues, mas também fornece uma direção clara para melhorias futuras.
Artigo: https://arxiv.org/html/2410.15553v2
O lançamento do teste de benchmark Multi-IF fornece uma referência importante para a pesquisa de grandes modelos de linguagem em diálogo multi-voltas e processamento multilíngue, e também aponta o caminho para futuras melhorias no modelo. Espera-se que surjam LLMs cada vez mais poderosos no futuro para melhor lidar com os desafios de tarefas complexas e multilíngues.