A equipe Emu3 do Zhiyuan Research Institute lançou o revolucionário modelo multimodal Emu3, que subverte a arquitetura tradicional do modelo multimodal, treina com base apenas na próxima previsão de token e alcança desempenho SOTA em tarefas de geração e percepção. A equipe do Emu3 tokeniza habilmente imagens, textos e vídeos em espaços discretos e treina um único modelo do Transformer em sequências multimodais mistas, alcançando a unificação de tarefas multimodais sem depender de arquiteturas de difusão ou combinação, o que fornece múltiplos O campo modal traz novos avanços.
A equipe Emu3 do Zhiyuan Research Institute lançou um novo modelo multimodal Emu3. Este modelo é treinado apenas com base na próxima previsão de token, subvertendo o modelo de difusão tradicional e a arquitetura do modelo de combinação, e obtendo resultados em tarefas de geração e percepção. desempenho de última geração.
A previsão do próximo token há muito é considerada um caminho promissor para a inteligência artificial geral (AGI), mas tem um desempenho fraco em tarefas multimodais. Atualmente, o campo multimodal ainda é dominado por modelos de difusão (como a Difusão Estável) e modelos de combinação (como a combinação de CLIP e LLM). A equipe do Emu3 tokeniza imagens, textos e vídeos em espaços discretos e treina um único modelo do Transformer do zero em sequências multimodais mistas, unificando assim tarefas multimodais sem depender de difusão ou arquiteturas combinacionais.
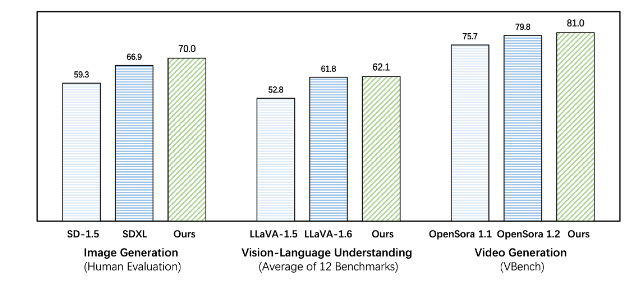
O Emu3 supera os modelos específicos de tarefas existentes em tarefas de geração e percepção, superando até mesmo modelos emblemáticos como SDXL e LLaVA-1.6. O Emu3 também é capaz de gerar vídeos de alta fidelidade prevendo o próximo token em uma sequência de vídeo. Ao contrário do Sora, que usa um modelo de difusão de vídeo para gerar vídeos a partir do ruído, o Emu3 gera vídeos de maneira causal, prevendo o próximo token na sequência de vídeo. O modelo pode simular certos aspectos de ambientes, pessoas e animais do mundo real e prever o que acontecerá a seguir, dado o contexto do vídeo.
O Emu3 simplifica o design complexo de modelos multimodais e concentra o foco em tokens, liberando um enorme potencial de escala durante o treinamento e inferência. Os resultados da pesquisa mostram que a previsão do próximo token é uma forma eficaz de construir inteligência multimodal geral além da linguagem. Para apoiar futuras pesquisas nesta área, a equipe do Emu3 abriu tecnologias e modelos-chave de código aberto, incluindo um poderoso tokenizador visual que pode converter vídeos e imagens em tokens discretos, que não estavam disponíveis publicamente antes.
O sucesso do Emu3 aponta a direção para o desenvolvimento futuro de modelos multimodais e traz uma nova esperança para a realização da AGI.
Endereço do projeto: https://github.com/baaivision/Emu3
O editor Downcodes resume: O surgimento do modelo Emu3 marca um novo marco no campo multimodal. Sua arquitetura simples e desempenho poderoso fornecem novas ideias e direções para pesquisas futuras em AGI. A estratégia de código aberto também promove o desenvolvimento conjunto da academia e da indústria. Vale a pena esperar por mais avanços no futuro!