Nos últimos anos, a inteligência artificial tem feito progressos significativos em vários campos, mas a sua capacidade de raciocínio matemático sempre foi um gargalo. Hoje, o surgimento de um novo benchmark chamado FrontierMath fornece um novo parâmetro para avaliar as capacidades matemáticas da IA. Ele leva as capacidades de raciocínio matemático da IA a limites sem precedentes e coloca sérios desafios aos modelos de IA existentes. O editor de Downcodes levará você a ter uma compreensão profunda do FrontierMath e ver como ele subverte nossa compreensão das capacidades matemáticas da IA.
No vasto universo da inteligência artificial, a matemática já foi considerada o último bastião da inteligência mecânica. Hoje, surgiu um novo teste de referência chamado FrontierMath, que leva as capacidades de raciocínio matemático da IA a limites sem precedentes.
A Epoch AI juntou-se a mais de 60 cérebros importantes do mundo da matemática para criar em conjunto este campo de desafio de IA que pode ser chamado de Olimpíada de Matemática. Este não é apenas um teste técnico, mas também o teste final da sabedoria matemática da inteligência artificial.
Imagine um laboratório repleto dos melhores matemáticos do mundo, que criaram centenas de quebra-cabeças matemáticos que excedem a imaginação das pessoas comuns. Esses problemas abrangem os campos matemáticos mais avançados, como teoria dos números, análise real, geometria algébrica e teoria das categorias, e são de complexidade impressionante. Mesmo um gênio da matemática com uma medalha de ouro nas Olimpíadas Internacionais de Matemática precisa de horas ou até dias para resolver um problema.
Surpreendentemente, os actuais modelos de IA de última geração tiveram um desempenho decepcionante neste benchmark: nenhum modelo foi capaz de resolver mais de 2% dos problemas. Esse resultado foi como um alerta e deu um tapa na cara da IA.
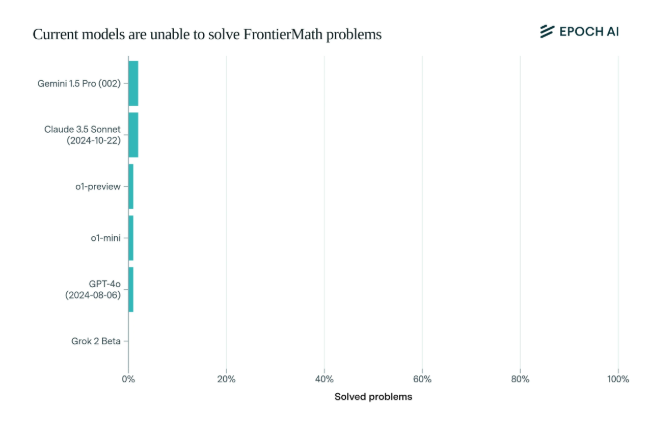
O que torna o FrontierMath único é o seu rigoroso mecanismo de avaliação. Os benchmarks de testes matemáticos tradicionais, como MATH e GSM8K, foram maximizados pela IA, e este novo benchmark usa perguntas novas e não publicadas e um sistema de verificação automatizado para evitar efetivamente a poluição de dados e testar verdadeiramente as capacidades de raciocínio matemático da IA.
Os principais modelos das principais empresas de IA, como OpenAI, Anthropic e Google DeepMind, que atraíram muita atenção, foram derrubados coletivamente neste teste. Isto reflecte uma filosofia técnica profunda: para os computadores, problemas matemáticos aparentemente complexos podem ser fáceis, mas tarefas que os humanos consideram simples podem tornar a IA indefesa.
Como disse Andrej Karpathy, isto confirma o paradoxo de Moravec: a dificuldade das tarefas inteligentes entre humanos e máquinas é muitas vezes contra-intuitiva. Este teste de referência não é apenas um exame rigoroso das capacidades da IA, mas também um catalisador para a evolução da IA para dimensões superiores.
Para a comunidade matemática e os pesquisadores de IA, o FrontierMath é como um Monte Everest invencível. Ele não apenas testa conhecimentos e habilidades, mas também testa o discernimento e o pensamento criativo. No futuro, quem conseguir assumir a liderança na escalada desse pico de inteligência ficará registrado na história do desenvolvimento da inteligência artificial.
O surgimento do teste de benchmark FrontierMath não é apenas um teste severo do nível de tecnologia de IA existente, mas também aponta a direção para o desenvolvimento futuro da IA. Indica que a IA ainda tem um longo caminho a percorrer no campo do raciocínio matemático e. também estimula a investigação. Os investigadores continuam a explorar e a inovar para ultrapassar os estrangulamentos das tecnologias existentes.