O editor do Downcodes soube que cientistas da Meta, da Universidade da Califórnia, Berkeley e da Universidade de Nova York desenvolveram em conjunto uma nova tecnologia chamada "Thinking Preference Optimization" (TPO), com o objetivo de melhorar o desempenho de grandes modelos de linguagem (LLMs). Esta tecnologia melhora a capacidade de “pensamento” da IA, permitindo que o modelo gere uma série de etapas de pensamento antes de responder a uma pergunta, e utilizando o modelo de avaliação para otimizar a qualidade da resposta final, permitindo-lhe um melhor desempenho em diversas tarefas. Diferente da tecnologia tradicional de "pensamento em cadeia", o TPO tem uma gama mais ampla de aplicações, mostrando especialmente vantagens significativas na escrita criativa, no raciocínio de bom senso, etc.
Recentemente, cientistas da Meta, da Universidade da Califórnia, Berkeley e da Universidade de Nova York colaboraram para desenvolver uma nova tecnologia chamada Otimização de Preferência de Pensamento (TPO). O objetivo desta tecnologia é melhorar o desempenho de grandes modelos de linguagem (LLMs) ao executar diversas tarefas, permitindo que a IA considere suas respostas com mais cuidado antes de responder.
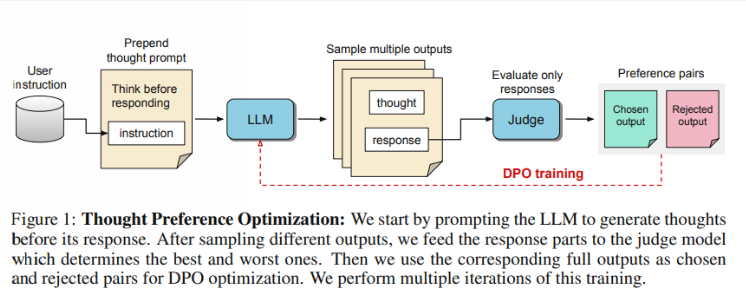
Os pesquisadores dizem que o pensamento deve ter ampla utilidade. Por exemplo, em tarefas de escrita criativa, a IA pode usar processos de pensamento internos para planejar a estrutura geral e o desenvolvimento do personagem. Este método é significativamente diferente da tecnologia anterior de solicitação de "Cadeia de Pensamento" (CoT). Este último é usado principalmente em tarefas matemáticas e lógicas, enquanto o TPO tem uma gama mais ampla de aplicações. Os pesquisadores mencionaram o novo modelo o1 da OpenAI e acreditam que o processo de pensamento também é útil para uma gama mais ampla de tarefas.
Então, como funciona o TPO Primeiro, o modelo gera uma série de etapas de pensamento antes de responder a uma pergunta. Em seguida, ele cria vários resultados, que são então avaliados por um modelo de avaliação apenas na resposta final, e não nas etapas de pensamento em si. Finalmente, o modelo é treinado através da otimização de preferências desses resultados de avaliação. Os investigadores esperam que a melhoria da qualidade das respostas possa ser alcançada através da melhoria do processo de pensamento, para que o modelo possa ganhar capacidades de raciocínio mais eficazes na aprendizagem implícita.
Nos testes, o modelo Llama38B usando TPO teve melhor desempenho em uma instrução geral seguindo benchmark do que uma versão sem inferência explícita. Nos benchmarks AlpacaEval e Arena-Hard, as taxas de vitórias do TPO atingiram 52,5% e 37,3%, respectivamente. Ainda mais emocionante é que a TPO também está a fazer progressos em áreas que normalmente não requerem pensamento explícito, como o bom senso, o marketing e a saúde.
No entanto, a equipe de pesquisa observou que a configuração atual não é adequada para problemas matemáticos, já que o TPO, na verdade, tem um desempenho pior do que o modelo básico nessas tarefas. Isto sugere que uma abordagem diferente pode ser necessária para tarefas altamente especializadas. Pesquisas futuras podem se concentrar em aspectos como o controle da duração dos processos de pensamento e o impacto do pensamento em modelos maiores.
Destaque:
A equipe de pesquisa lançou o "Thinking Preference Optimization" (TPO), que visa melhorar a capacidade de raciocínio da IA na execução de tarefas.
?O TPO usa modelos de avaliação para otimizar a qualidade da resposta, permitindo que o modelo gere etapas de pensamento antes de responder.
Os testes mostraram que os TPOs têm um bom desempenho em áreas como conhecimentos gerais e marketing, mas têm um desempenho fraco em tarefas matemáticas.
Em suma, a tecnologia TPO fornece uma nova direção para a melhoria de grandes modelos de linguagem, e vale a pena esperar pelo seu potencial na melhoria das capacidades de pensamento da IA. No entanto, esta tecnologia também tem limitações, e pesquisas futuras precisam melhorar e ampliar ainda mais o seu escopo de aplicação. O editor do Downcodes continuará prestando atenção aos últimos desenvolvimentos neste campo e trazendo relatórios mais interessantes aos leitores.