O editor do Downcodes descobriu que a Alibaba Damo Academy e a Renmin University of China abriram em conjunto um modelo de processamento de documentos chamado mPLUG-DocOwl1.5. O modelo pode compreender o conteúdo do documento sem reconhecimento de OCR e tem um bom desempenho em vários testes de benchmark. Seu núcleo está no método de "aprendizado de estrutura unificada", que melhora a compreensão estrutural do modelo multimodal de linguagem grande (MLLM) de imagens de rich text. . O modelo divulgou publicamente códigos, modelos e conjuntos de dados no GitHub, fornecendo recursos valiosos para pesquisas em áreas relacionadas.
A Alibaba Damo Academy e a Universidade Renmin da China abriram recentemente em conjunto um modelo de processamento de documentos chamado mPLUG-DocOwl1.5. Este modelo se concentra na compreensão do conteúdo do documento sem reconhecimento de OCR e obteve resultados em vários testes de benchmark de compreensão visual de documentos.
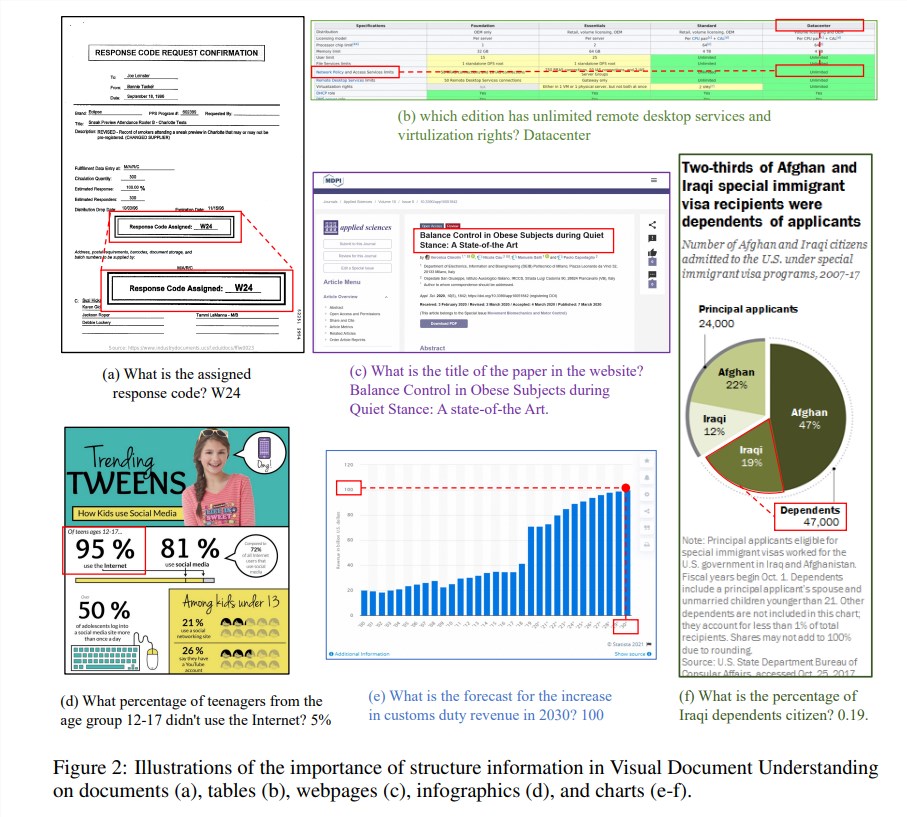
As informações estruturais são cruciais para a compreensão da semântica de imagens ricas em texto, como documentos, tabelas e gráficos. Embora os modelos multimodais de linguagem grande (MLLM) existentes tenham recursos de reconhecimento de texto, eles não têm a capacidade de compreender a estrutura geral das imagens de documentos rich text. Para resolver este problema, mPLUG-DocOwl1.5 enfatiza a importância da informação estrutural na compreensão visual do documento e propõe "aprendizado de estrutura unificada" para melhorar o desempenho do MLLM.
A "aprendizagem de estrutura unificada" do modelo cobre 5 áreas: documentos, páginas da web, tabelas, gráficos e imagens naturais, incluindo tarefas de análise com reconhecimento de estrutura e tarefas de posicionamento de texto multigranularidade. Para codificar melhor as informações estruturais, os pesquisadores projetaram um módulo H-Reducer de visual para texto simples e eficaz, que não apenas preserva as informações do layout, mas também reduz o comprimento dos recursos visuais ao mesclar fragmentos de imagens adjacentes horizontalmente por meio de convolução, permitindo modelos de linguagem grandes para compreender imagens de alta resolução com mais eficiência.
Além disso, para apoiar o aprendizado da estrutura, a equipe de pesquisa construiu o DocStruct4M, um conjunto de treinamento abrangente contendo 4 milhões de amostras baseadas em conjuntos de dados disponíveis publicamente, que contém sequências de texto com reconhecimento de estrutura e pares de caixas delimitadoras de texto multigranularidade. A fim de estimular ainda mais as capacidades de raciocínio do MLLM no campo documental, eles também construíram um conjunto de dados de ajuste fino de raciocínio DocReason25K contendo 25.000 amostras de alta qualidade.
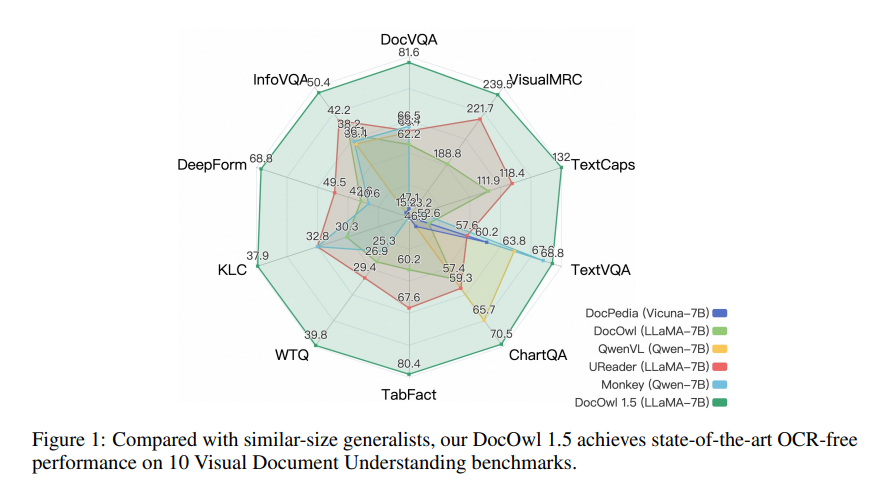
mPLUG-DocOwl1.5 adota uma estrutura de treinamento de dois estágios, que primeiro executa o aprendizado de estrutura unificada e, em seguida, executa o ajuste fino multitarefa em várias tarefas posteriores. Através deste método de treinamento, o mPLUG-DocOwl1.5 alcançou desempenho de última geração em 10 benchmarks de compreensão de documentos visuais, melhorando o desempenho SOTA do 7B LLM em mais de 10 pontos percentuais em 5 benchmarks.
Atualmente, o código, modelo e conjunto de dados do mPLUG-DocOwl1.5 foram divulgados publicamente no GitHub.
Endereço do projeto: https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
Endereço do artigo: https://arxiv.org/pdf/2403.12895
O código aberto do mPLUG-DocOwl1.5 traz novas possibilidades para a pesquisa e aplicação na área de compreensão visual de documentos. Seu desempenho eficiente e métodos de acesso convenientes merecem a atenção e utilização dos desenvolvedores. Espera-se que este modelo possa ser utilizado em cenários mais práticos no futuro.