O editor do Downcodes irá levá-lo para conhecer os últimos resultados da pesquisa do Instituto Federal Suíço de Tecnologia em Lausanne (EPFL)! Este estudo fornece uma comparação aprofundada de dois métodos de treinamento adaptativos convencionais para grandes modelos de linguagem (LLM): aprendizagem contextual (ICL) e ajuste fino de instrução (IFT), e usa o benchmark MT-Bench para avaliar a capacidade do modelo de seguir instruções. Os resultados da pesquisa mostram que os dois métodos têm méritos próprios em diferentes cenários, fornecendo uma referência valiosa para a seleção de métodos de treinamento LLM.
Um estudo recente da Ecole Polytechnique Fédérale de Lausanne (EPFL), na Suíça, comparou dois métodos convencionais de treinamento adaptativo para grandes modelos de linguagem (LLM): aprendizagem contextual (ICL) e ajuste fino de instrução (IFT). Os pesquisadores usaram o benchmark MT-Bench para avaliar a capacidade de um modelo de seguir instruções e descobriram que ambos os métodos tiveram desempenho melhor ou pior em determinadas circunstâncias.
A pesquisa descobriu que quando o número de amostras de treinamento disponíveis é pequeno (por exemplo, não mais que 50), os efeitos do ICL e do IFT são muito próximos. Isto sugere que o ICL pode ser uma alternativa ao IFT quando os dados são limitados.
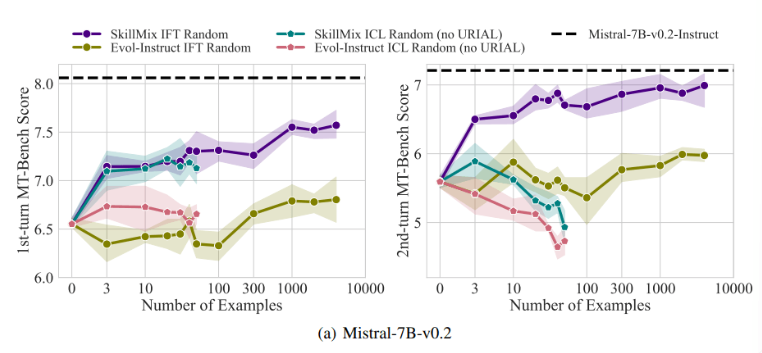
No entanto, à medida que a complexidade da tarefa aumenta, como em cenários de diálogo multivoltas, as vantagens do IFT tornam-se aparentes. Os pesquisadores acreditam que o modelo ICL é propenso a se ajustar demais ao estilo de uma única amostra, resultando em desempenho insatisfatório ao lidar com conversas complexas, ou até pior do que o modelo básico.
O estudo também examinou o método URIAL, que utiliza apenas três amostras e instruções para seguir regras para treinar um modelo de linguagem base. Embora a URIAL tenha alcançado alguns resultados, ainda existe uma lacuna em relação ao modelo treinado pelo IFT. Os pesquisadores da EPFL melhoraram o desempenho do URIAL ao aprimorar a estratégia de seleção de amostras, aproximando-o dos modelos de ajuste fino. Isto destaca a importância de dados de treinamento de alta qualidade para ICL, IFT e treinamento de modelo básico.
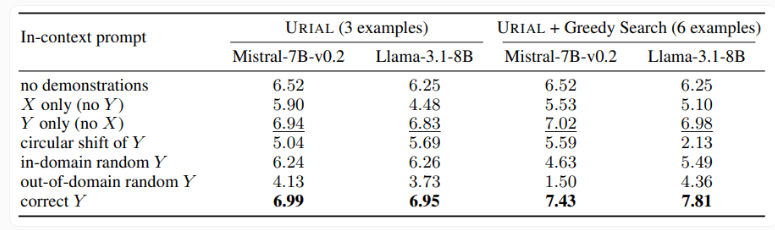
Além disso, o estudo também descobriu que os parâmetros de decodificação têm um impacto significativo no desempenho do modelo. Esses parâmetros determinam como o modelo gera texto e são críticos tanto para o LLM básico quanto para modelos treinados com URIAL.
Os pesquisadores observam que mesmo o modelo básico pode seguir instruções até certo ponto, dados parâmetros de decodificação adequados.
A importância deste estudo é que ele revela que a aprendizagem contextual pode ajustar modelos de linguagem de forma rápida e eficiente, especialmente quando as amostras de treinamento são limitadas. Mas para tarefas complexas, como conversas em vários turnos, o ajuste fino do comando ainda é uma escolha melhor.
À medida que o tamanho do conjunto de dados aumenta, o desempenho do IFT continuará a melhorar, enquanto o desempenho do ICL se estabilizará após atingir um certo número de amostras. Os pesquisadores enfatizam que a escolha entre ICL e IFT depende de vários fatores, como recursos disponíveis, volume de dados e requisitos específicos de aplicação. Seja qual for o método escolhido, dados de treinamento de alta qualidade são cruciais.
Em suma, este estudo da EPFL fornece novos insights sobre a seleção de métodos de treinamento para grandes modelos linguísticos e aponta o caminho para futuras direções de pesquisa. Escolher ICL ou IFT exige pesar os prós e os contras com base na situação específica, e dados de alta qualidade são sempre a chave. Esperamos que esta pesquisa possa ajudar todos a compreender e aplicar melhor os grandes modelos de linguagem.