O editor de Downcodes irá levá-lo para aprender sobre o Emu3, o mais recente modelo mundial multimodal lançado pelo Zhiyuan Research Institute! O Emu3 conta com sua capacidade única de “previsão do próximo token” para alcançar capacidades inovadoras de compreensão e geração em três modalidades: texto, imagem e vídeo. Ele pode não apenas gerar imagens de alta qualidade e vídeos suaves e naturais, mas também realizar compreensão precisa de imagens e previsão de vídeo. Seu desempenho excede o de muitos modelos de código aberto bem conhecidos. A natureza de código aberto do Emu3 também injeta nova vitalidade no desenvolvimento da IA multimodal. Vamos explorar a inovação tecnológica e o potencial futuro por trás dela.
O Zhiyuan Research Institute lançou oficialmente seu modelo mundial multimodal de nova geração Emu3. O maior destaque deste modelo é que ele pode prever o próximo token em três modos diferentes: texto, imagem e vídeo.

Em termos de geração de imagens, o Emu3 é capaz de gerar imagens de alta qualidade com base na previsão visual de tokens. Isso significa que os usuários podem esperar resoluções flexíveis e uma variedade de estilos.

Em termos de geração de vídeo, o Emu3 funciona de uma forma completamente nova. Ao contrário de outros modelos que geram vídeos através de ruído, o Emu3 gera vídeos diretamente através de previsão sequencial. Este avanço tecnológico torna a geração de vídeo mais suave e natural.

Em tarefas como geração de imagens, geração de vídeos e compreensão de linguagem visual, o desempenho do Emu3 excede o de muitos modelos de código aberto bem conhecidos, como SDXL, LLaVA e OpenSora. Por trás dele está um poderoso tokenizador visual que pode converter vídeos e imagens em tokens discretos. Esse design fornece novas ideias para processamento unificado de texto, imagens e vídeos.
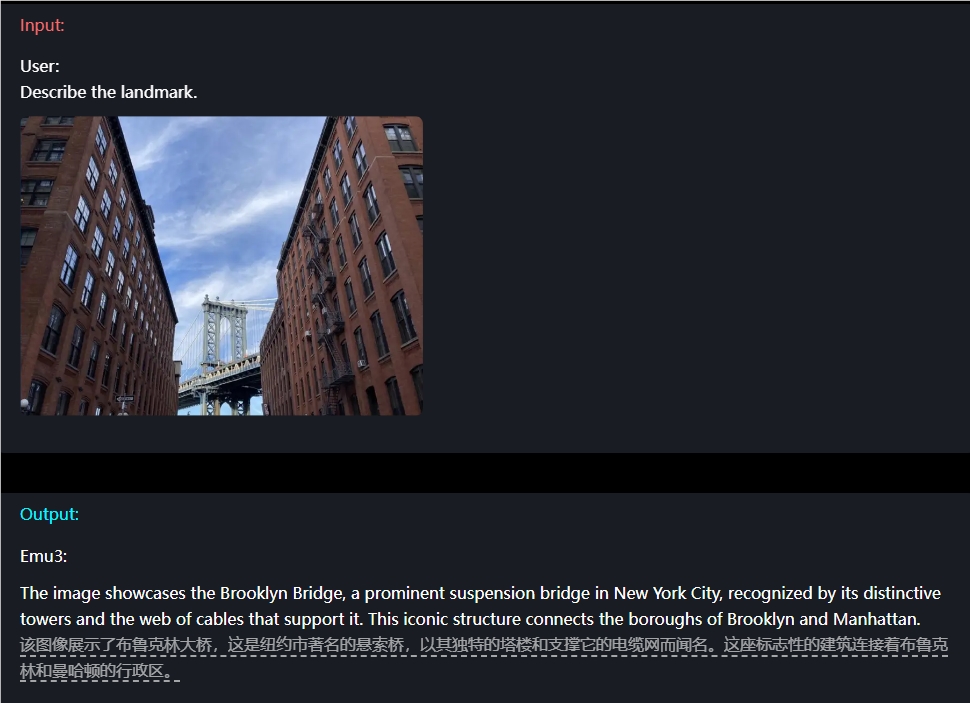
Por exemplo, em termos de compreensão da imagem, os usuários só precisam inserir uma pergunta e o Emu3 pode descrever com precisão o conteúdo da imagem.
O Emu3 também possui recursos de previsão de vídeo. Ao receber um vídeo, o Emu3 pode prever o que acontecerá a seguir com base no conteúdo existente. Isto permite-lhe demonstrar fortes capacidades na simulação de ambientes e comportamentos humanos e animais, permitindo aos utilizadores experimentar uma experiência interactiva mais realista.

Além disso, a flexibilidade de design do Emu3 é revigorante. Pode ser otimizado diretamente com as preferências humanas para que o conteúdo gerado esteja mais alinhado com as expectativas do usuário. Além disso, o Emu3, como modelo de código aberto, atraiu discussões acaloradas na comunidade técnica. Muitas pessoas acreditam que esta conquista mudará completamente o padrão de desenvolvimento da IA multimodal.
URL do projeto: https://emu.baai.ac.cn/about
Artigo: https://arxiv.org/pdf/2409.18869
Destaque:
Emu3 realiza compreensão multimodal e geração de texto, imagens e vídeos por meio da previsão do próximo token.
Em múltiplas tarefas, o desempenho do Emu3 superou o de muitos modelos de código aberto bem conhecidos, demonstrando suas poderosas capacidades.
O design flexível e os recursos de código aberto do Emu3 oferecem aos desenvolvedores novas oportunidades e devem promover a inovação e o desenvolvimento da IA multimodal.
O surgimento do Emu3 marca um novo marco no campo da IA multimodal. O seu desempenho poderoso, design flexível e recursos de código aberto terão, sem dúvida, um impacto profundo no desenvolvimento futuro da IA. Esperamos que o Emu3 seja usado em mais áreas e traga mais comodidade e surpresas para a humanidade!