O editor do Downcodes soube que o Instituto de Pesquisa de Inteligência Artificial Zhiyuan de Pequim uniu forças com várias universidades para lançar um grande modelo para compreensão de vídeo ultralongo chamado Video-XL. O modelo tem um bom desempenho no processamento de vídeos longos de mais de dez minutos, alcançando posições de liderança em vários benchmarks, demonstrando fortes capacidades de generalização e eficiência de processamento. Video-XL usa modelos de linguagem para compactar longas sequências visuais e atinge quase 95% de precisão em tarefas como "encontrar uma agulha em um palheiro". Ele só precisa de uma placa gráfica com 80G de memória de vídeo para processar 2.048 quadros de entrada. O código aberto deste modelo promoverá a cooperação e o desenvolvimento da comunidade global de pesquisa de compreensão de vídeo multimodal.
O Instituto de Pesquisa de Inteligência Artificial Zhiyuan de Pequim uniu forças com universidades como a Universidade Jiao Tong de Xangai, a Universidade Renmin da China, a Universidade de Pequim e a Universidade de Correios e Telecomunicações de Pequim para lançar um grande modelo de compreensão de vídeo ultralongo chamado Video-XL. Este modelo é uma demonstração importante das principais capacidades dos grandes modelos multimodais e um passo fundamental em direção à inteligência artificial geral (AGI). Comparado com grandes modelos multimodais existentes, o Video-XL apresenta melhor desempenho e eficiência ao processar vídeos longos de mais de 10 minutos.

Video-XL utiliza os recursos nativos de modelos de linguagem (LLM) para compactar sequências visuais longas, mantém a capacidade de compreender vídeos curtos e mostra excelentes capacidades de generalização na compreensão de vídeos longos. Este modelo ocupa o primeiro lugar em várias tarefas em vários benchmarks convencionais de compreensão de vídeos longos. O Video-XL atinge um bom equilíbrio entre eficiência e desempenho. Ele só precisa de uma placa gráfica com memória de vídeo de 80G para processar entrada de 2.048 quadros, amostrar vídeos de uma hora e atingir quase 95% na tarefa de vídeo "agulha no palheiro". % precisão.
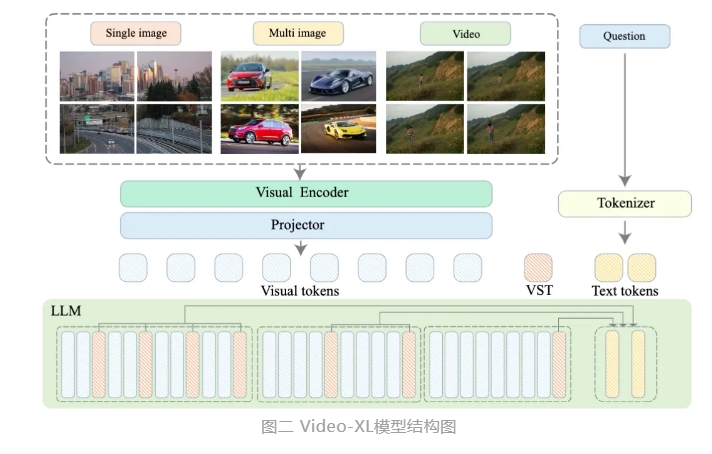
Espera-se que o Video-XL mostre amplo valor de aplicação em cenários de aplicação, como resumo de filmes, detecção de anomalias de vídeo e detecção de posicionamento de anúncios, e se torne um assistente poderoso para compreensão de vídeos longos. O lançamento deste modelo marca um passo importante na eficiência e precisão da tecnologia de compreensão de vídeos longos e fornece forte suporte técnico para o processamento e análise automatizados de conteúdo de vídeos longos no futuro.
Atualmente, o código modelo do Video-XL é de código aberto para promover a cooperação e o compartilhamento de tecnologia na comunidade global de pesquisa de compreensão de vídeo multimodal.
Título do artigo: Video-XL: Modelo de linguagem de visão extralonga para compreensão de vídeo em escala horária
Link do artigo: https://arxiv.org/abs/2409.14485
Link do modelo: https://huggingface.co/sy1998/Video_XL
Link do projeto: https://github.com/VectorSpaceLab/Video-XL
O código aberto do Video-XL traz novas possibilidades para a pesquisa e aplicação no campo da compreensão de vídeos longos. Sua eficiência e precisão promoverão o desenvolvimento de tecnologias relacionadas e fornecerão suporte técnico para mais cenários de aplicação no futuro. Esperamos ver aplicações mais inovadoras baseadas em Video-XL no futuro.