O editor de Downcodes apresentará a você uma pesquisa mais recente da Universidade Técnica de Darmstadt, na Alemanha. Este estudo usou o problema de Bongard como ferramenta de teste para avaliar o desempenho do atual modelo de imagem de IA de última geração em tarefas simples de raciocínio visual. Os resultados da pesquisa são surpreendentes. Mesmo a precisão dos principais modelos multimodais como o GPT-4o é muito inferior ao esperado, o que desencadeia uma reflexão profunda sobre os padrões existentes de avaliação da capacidade visual da IA.
A pesquisa mais recente da Universidade Técnica de Darmstadt, na Alemanha, revela um fenômeno instigante: mesmo os modelos de imagem de IA mais avançados podem cometer erros significativos quando confrontados com tarefas simples de raciocínio visual. Os resultados desta pesquisa apresentam um novo pensamento sobre os padrões de avaliação da capacidade visual da IA.
A equipe de pesquisa usou o problema de Bongard desenvolvido pelo cientista russo Michail Bongard como ferramenta de teste. Este tipo de puzzle visual consiste em 12 imagens simples divididas em dois grupos e requer a identificação das regras que distinguem os dois grupos. Essa tarefa de raciocínio abstrato não é difícil para a maioria das pessoas, mas o desempenho do modelo de IA foi surpreendente.
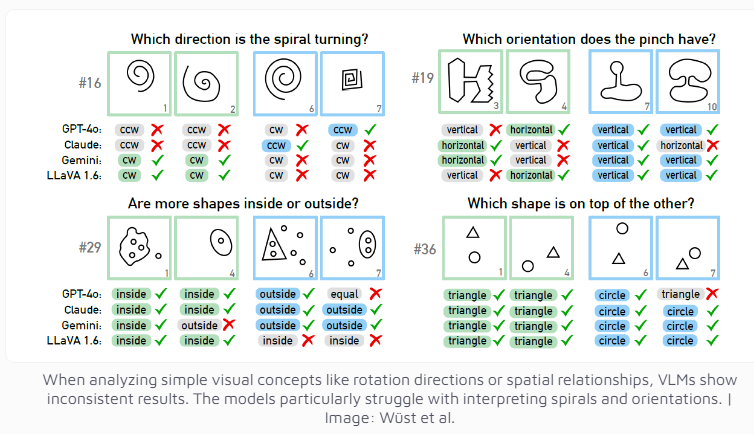
Mesmo o modelo multimodal GPT-4o, atualmente considerado o mais avançado, resolveu com sucesso apenas 21 dos 100 quebra-cabeças visuais. O desempenho de outros modelos de IA bem conhecidos, como Claude, Gemini e LLaVA, é ainda menos satisfatório. Esses modelos mostram dificuldade significativa em identificar conceitos visuais básicos, como linhas verticais e horizontais, ou em julgar a direção de uma espiral.
Os pesquisadores descobriram que mesmo quando foram fornecidas múltiplas opções, o desempenho do modelo de IA melhorou apenas ligeiramente. Somente sob restrições estritas no número de respostas possíveis é que GPT-4 e Claude melhoraram suas taxas de sucesso para 68 e 69 quebra-cabeças, respectivamente. Através de uma análise aprofundada de quatro casos específicos, a equipa de investigação descobriu que os sistemas de IA por vezes têm problemas no nível básico de percepção visual antes de atingir a fase de pensamento e raciocínio, mas as razões específicas ainda são difíceis de determinar.
Esta investigação também suscita reflexão sobre os critérios de avaliação dos sistemas de IA. A equipe de pesquisa apontou: Por que os modelos de linguagem visual funcionam bem em benchmarks estabelecidos, mas lutam com o problema aparentemente simples de Bongard Quão significativos são esses benchmarks na avaliação das capacidades de raciocínio do mundo real? pode precisar ser redesenhado para medir com mais precisão as capacidades de raciocínio visual da IA.
Esta pesquisa não apenas demonstra as limitações da tecnologia atual de IA, mas também aponta o caminho para o desenvolvimento futuro das capacidades visuais de IA. Lembra-nos que, embora torçamos pelo rápido progresso da IA, devemos também perceber claramente que ainda há espaço para melhorias nas capacidades cognitivas básicas da IA.
Esta pesquisa mostra claramente que os modelos de IA ainda têm muito espaço para melhorias no raciocínio visual, e são necessários métodos de avaliação mais eficazes e avanços tecnológicos no futuro para melhorar as capacidades cognitivas da IA. O editor de Downcodes continuará prestando atenção ao progresso de ponta no campo da IA e trazendo a você relatórios mais interessantes.