Grandes modelos de linguagem (LLMs) são cada vez mais utilizados, mas seu grande número de parâmetros traz enormes requisitos de recursos computacionais. A fim de resolver este problema e melhorar a eficiência e precisão do modelo em diferentes ambientes de recursos, os investigadores continuam a explorar novos métodos. Este artigo apresentará a estrutura Flextron desenvolvida em conjunto por pesquisadores da NVIDIA e da Universidade do Texas em Austin. Esta estrutura foi projetada para alcançar a implantação flexível de modelos de IA sem ajustes adicionais e resolver efetivamente os problemas de ineficiência dos métodos tradicionais. O editor de Downcodes explicará detalhadamente as inovações da estrutura Flextron e suas vantagens em ambientes com recursos limitados.
No campo da inteligência artificial, grandes modelos de linguagem (LLMs), como GPT-3 e Llama-2, fizeram progressos significativos e podem compreender e gerar com precisão a linguagem humana. Porém, o grande número de parâmetros desses modelos faz com que eles exijam uma grande quantidade de recursos computacionais durante o treinamento e implantação, o que representa um desafio em ambientes com recursos limitados.
Entrada de papel: https://arxiv.org/html/2406.10260v1
Tradicionalmente, para alcançar um equilíbrio entre eficiência e precisão sob diferentes restrições de recursos computacionais, os pesquisadores precisam treinar múltiplas versões diferentes do modelo. Por exemplo, a família de modelos Llama-2 inclui diferentes variantes com 7 mil milhões, 1,3 mil milhões e 700 milhões de parâmetros. No entanto, este método requer uma grande quantidade de dados e recursos computacionais e não é muito eficiente.
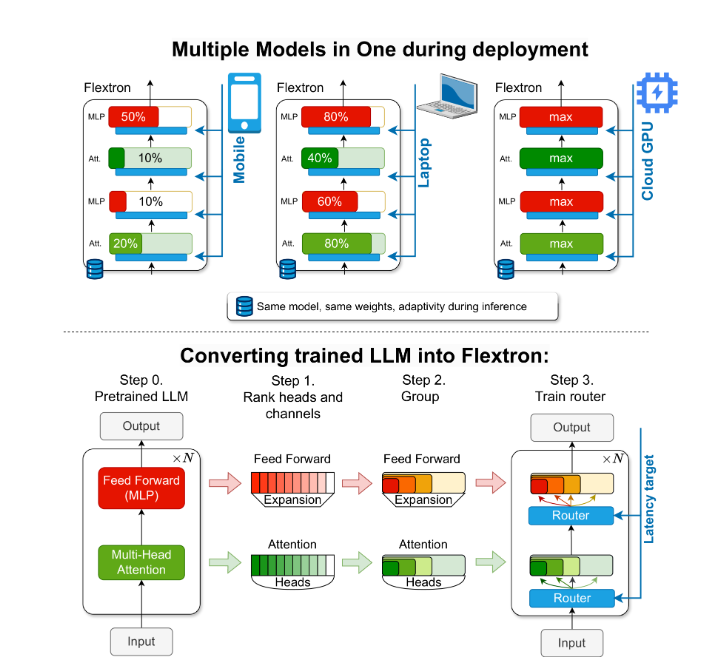
Para resolver esse problema, pesquisadores da NVIDIA e da Universidade do Texas em Austin introduziram a estrutura Flextron. Flextron é uma nova arquitetura de modelo flexível e estrutura de otimização pós-treinamento que suporta implantação adaptativa de modelos sem a necessidade de ajuste fino adicional, resolvendo assim os problemas de ineficiência dos métodos tradicionais.
Flextron transforma LLM pré-treinado em modelos elásticos por meio de métodos de treinamento eficientes em amostras e algoritmos de roteamento avançados. Essa estrutura apresenta um design elástico aninhado que permite ajustes dinâmicos durante a inferência para atender a metas específicas de latência e precisão. Essa adaptabilidade torna possível usar um único modelo pré-treinado em diversos cenários de implantação, reduzindo significativamente a necessidade de múltiplas variantes de modelo.
A avaliação de desempenho do Flextron mostra que ele supera em eficiência e precisão em comparação com vários modelos treinados de ponta a ponta e outras redes elásticas de última geração. Por exemplo, Flextron tem um bom desempenho em vários benchmarks, como ARC-easy, LAMBADA, PIQA, WinoGrande, MMLU e HellaSwag, usando apenas 7,63% dos marcadores de treinamento no pré-treinamento original, economizando assim muitos recursos de computação e tempo .
A estrutura Flextron também inclui camadas elásticas de perceptron multicamadas (MLP) e de atenção elástica multicabeças (MHA), aumentando ainda mais sua adaptabilidade. A camada elástica MHA utiliza efetivamente a memória disponível e o poder de processamento, selecionando um subconjunto de cabeças de atenção com base nos dados de entrada e é particularmente adequada para cenários com recursos computacionais limitados.
Destaque:
? A estrutura Flextron oferece suporte à implantação flexível de modelos de IA sem ajustes adicionais.
Por meio de treinamento eficiente de amostras e algoritmos de roteamento avançados, a eficiência e a precisão do modelo são melhoradas.
A camada elástica de atenção multicabeças otimiza a utilização de recursos e é particularmente adequada para ambientes com recursos computacionais limitados.
Este relatório espera apresentar a importância e a inovação da estrutura Flextron aos alunos do ensino médio de uma forma fácil de entender.
Em suma, a estrutura Flextron fornece uma solução eficiente e inovadora para o problema de implantação de grandes modelos de linguagem em ambientes com recursos limitados. Sua arquitetura flexível e método de treinamento eficiente em amostras proporcionam vantagens significativas em aplicações práticas e fornecem uma nova direção para o desenvolvimento da tecnologia de inteligência artificial. O editor do Downcodes espera que este artigo possa ajudar todos a compreender melhor as ideias centrais e as contribuições técnicas da estrutura Flextron.