O editor de Downcodes levará você a conhecer uma tecnologia inovadora que melhora a eficiência de grandes modelos de linguagem (LLMs) - Q-Sparse. As poderosas capacidades de processamento de linguagem natural dos LLMs atraíram muita atenção, mas seu alto custo computacional e consumo de memória sempre foram gargalos em aplicações práticas. Q-Sparse usa um método inteligente de esparsificação para melhorar significativamente a eficiência da inferência e, ao mesmo tempo, garantir o desempenho do modelo, abrindo caminho para a aplicação generalizada de LLMs. Este artigo explorará profundamente a tecnologia central, as vantagens e os resultados da verificação experimental do Q-Sparse, mostrando seu enorme potencial para melhorar a eficiência dos LLMs.
No mundo da inteligência artificial, os grandes modelos de linguagem (LLMs) são conhecidos por suas capacidades superiores de processamento de linguagem natural. No entanto, a implantação destes modelos em aplicações práticas enfrenta enormes desafios, principalmente devido ao seu alto custo computacional e consumo de memória durante a fase de inferência. Para resolver este problema, os pesquisadores têm explorado como melhorar a eficiência dos LLMs. Recentemente, um método chamado Q-Sparse atraiu muita atenção.
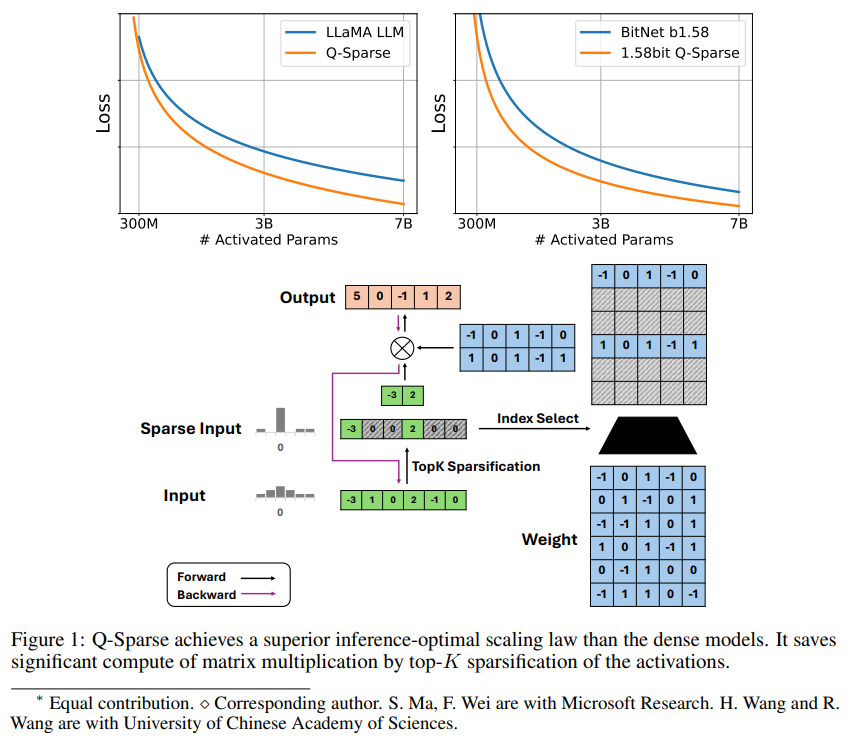
Q-Sparse é um método simples, mas eficaz, que atinge a ativação totalmente esparsa de LLMs aplicando esparsificação top-K nas ativações e um estimador de passagem no treinamento. Isso significa melhorias significativas na eficiência ao inferir. Os principais resultados da pesquisa incluem:
Q-Sparse alcança maior eficiência de inferência enquanto mantém resultados comparáveis aos LLMs de linha de base.
Uma regra de expansão inferencial ótima adequada para LLMs de ativação esparsa é proposta.
Q-Sparse funciona em diferentes ambientes, incluindo treinamento do zero, treinamento contínuo de LLMs prontos para uso e ajuste fino.
Q-Sparse funciona com precisão total e LLMs de 1 bit (por exemplo, BitNet b1.58).
Vantagens da ativação esparsa
A dispersão melhora a eficiência dos LLMs de duas maneiras: primeiro, a dispersão pode reduzir a quantidade de cálculo da multiplicação de matrizes, porque zero elementos não serão calculados, segundo, a dispersão pode reduzir a quantidade de transmissão de entrada/saída (E/S), o que; É o principal gargalo na fase de inferência dos LLMs.
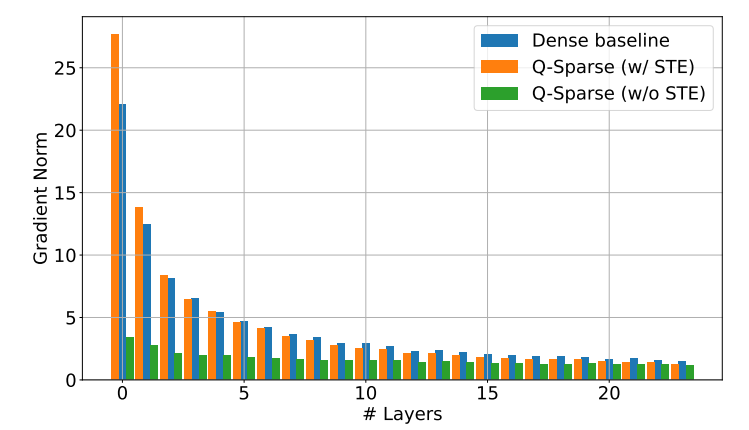
Q-Sparse atinge dispersão total de ativações aplicando uma função de esparsificação top-K em cada projeção linear. Para retropropagação, o gradiente de ativação é calculado usando um estimador de passagem. Além disso, a função ReLU quadrada é introduzida para melhorar ainda mais a dispersão de ativação.
Verificação experimental
Os pesquisadores estudaram a lei de expansão de LLMs escassamente ativados por meio de uma série de experimentos de expansão e chegaram a algumas descobertas interessantes:
O desempenho dos modelos de ativação esparsa melhora com o aumento do tamanho do modelo e da proporção de dispersão.
Dada uma razão de dispersão fixa S, o desempenho de um modelo de ativação esparsa é dimensionado com o tamanho do modelo N de uma maneira de lei de potência.
Dado um parâmetro fixo N, o desempenho do modelo de ativação esparsa aumenta exponencialmente com a razão de esparsidade S.
Q-Sparse pode ser usado não apenas para treinamento do zero, mas também para treinamento contínuo e ajuste fino de LLMs prontos para uso. Nas configurações de treinamento contínuo e ajuste fino, os pesquisadores usaram a mesma arquitetura e processo de treinamento do treinamento do zero, a única diferença foi inicializar o modelo com pesos pré-treinados e permitir funções esparsas para continuar o treinamento.
Os pesquisadores estão explorando o uso do Q-Sparse com LLMs de 1 bit (como BitNet b1.58) e especialistas mistos (MoE) para melhorar ainda mais a eficiência dos LLMs. Além disso, eles estão trabalhando para tornar o Q-Sparse compatível com o modo batch, o que proporcionará mais flexibilidade para treinamento e inferência de LLMs.
O surgimento da tecnologia Q-Sparse fornece novas ideias para resolver o problema de eficiência dos LLMs. Ela tem grande potencial na redução de custos de computação e uso de memória, e espera-se que promova a aplicação de LLMs em mais campos. Acredita-se que mais resultados de pesquisas baseados em Q-Sparse surgirão no futuro para melhorar ainda mais o desempenho e a eficiência dos LLMs.