Nos últimos anos, grandes modelos multimodais desenvolveram-se rapidamente e surgiram muitos modelos excelentes. No entanto, a maioria dos modelos existentes depende de codificadores visuais, que sofrem de problemas de viés de indução visual causados pela separação do treinamento, limitando a eficiência e o desempenho. O editor de Downcodes traz para você um novo modelo de linguagem visual EVE lançado pelo Zhiyuan Research Institute em conjunto com universidades. Ele adota uma arquitetura sem código e obteve excelentes resultados em vários testes de benchmark, proporcionando novas oportunidades para o desenvolvimento de modelos multimodais. .
Recentemente, progressos significativos foram feitos na pesquisa e aplicação de grandes modelos multimodais. Empresas estrangeiras como OpenAI, Google, Microsoft, etc. lançaram uma série de modelos avançados, e instituições nacionais como Zhipu AI e Step Star fizeram avanços neste campo. Esses modelos geralmente dependem de codificadores visuais para extrair recursos visuais e combiná-los com grandes modelos de linguagem, mas há um problema de viés de indução visual causado pela separação do treinamento, que limita a eficiência de implantação e o desempenho de grandes modelos multimodais.
Para resolver esses problemas, o Instituto de Pesquisa Zhiyuan, juntamente com a Universidade de Tecnologia de Dalian, a Universidade de Pequim e outras universidades, lançou uma nova geração de modelo de linguagem visual sem codificador EVE. EVE integra representação visual-linguística, alinhamento e inferência em uma arquitetura unificada de decodificador puro por meio de estratégias de treinamento refinadas e supervisão visual adicional. Usando dados públicos, o EVE tem um bom desempenho em vários benchmarks de linguagem visual, aproximando-se ou até mesmo superando os métodos multimodais convencionais baseados em codificadores.
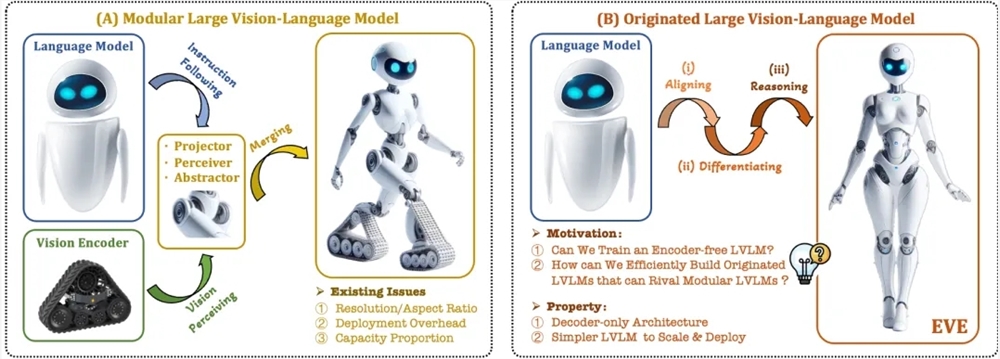
Os principais recursos do EVE incluem:
Modelo de linguagem visual nativa: remove o codificador visual e lida com qualquer proporção de imagem, que é significativamente melhor que o mesmo tipo de modelo Fuyu-8B.
Baixos custos de dados e treinamento: O pré-treinamento utiliza dados públicos como OpenImages, SAM e LAION, e o tempo de treinamento é curto.
Exploração transparente e eficiente: Fornece um caminho de desenvolvimento eficiente e transparente para arquiteturas multimodais nativas de decodificadores puros.
Estrutura do modelo:
Camada de incorporação de patch: obtenha o mapa de recursos 2D da imagem por meio de uma única camada de convolução e uma camada de pooling média para aprimorar recursos locais e informações globais.
Camada de alinhamento de patches: integre recursos visuais de rede multicamadas para obter um alinhamento refinado com a saída do codificador visual.
Estratégia de treinamento:
Etapa pré-formação orientada por grandes modelos de linguagem: estabelecendo a ligação inicial entre visão e linguagem.
Estágio generativo de pré-treinamento: Melhore a capacidade do modelo de compreender o conteúdo linguístico visual.
Fase supervisionada de ajuste fino: regula a capacidade do modelo de seguir as instruções do idioma e aprender padrões de conversação.
Análise quantitativa: EVE tem um bom desempenho em vários benchmarks de linguagem visual e é comparável a uma variedade de modelos de linguagem visual baseados em codificadores convencionais. Apesar dos desafios em responder com precisão a instruções específicas, através de uma estratégia de treinamento eficiente, o EVE atinge um desempenho comparável aos modelos de linguagem visual com bases codificadoras.
EVE demonstrou o potencial de modelos de linguagem visual nativa sem codificador. No futuro, poderá continuar a promover o desenvolvimento de modelos multimodais através de melhorias de desempenho, otimização de arquiteturas sem codificador e a construção de multimodais nativos. modelos.
Endereço do artigo: https://arxiv.org/abs/2406.11832
Código do projeto: https://github.com/baaivision/EVE
Endereço do modelo: https://huggingface.co/BAAI/EVE-7B-HD-v1.0
Em suma, o surgimento do modelo EVE proporciona novos rumos e possibilidades para o desenvolvimento de grandes modelos multimodais. Sua estratégia de treinamento eficiente e excelente desempenho merecem atenção. Esperamos que o futuro modelo EVE seja capaz de demonstrar as suas poderosas capacidades em mais campos.