Na comunicação por voz em tempo real, alterar o timbre do locutor sem afetar a semântica e a prosódia sempre foi um problema técnico. O editor de Downcodes apresentará hoje uma tecnologia inovadora - StreamVC, que pode alterar o timbre da voz do locutor em tempo real, mantendo o conteúdo e o ritmo da voz. É adequado para plataformas móveis e oferece comunicação em tempo real e anonimato de voz. A baixa latência, a síntese de fala de alta qualidade e a estabilidade de tom do StreamVC proporcionam vantagens significativas no campo das comunicações em tempo real.
Num mundo de comunicação em tempo real, seja uma chamada telefónica ou uma videoconferência, o som é uma ferramenta importante para nos expressarmos. Mas você já pensou no que aconteceria se pudéssemos mudar o timbre da voz de um locutor em tempo real sem afetar o conteúdo e o ritmo da linguagem? O surgimento da tecnologia StreamVC nos permite fazer isso?
StreamVC é uma solução inovadora de conversão de voz que combina o timbre da voz alvo, mantendo o conteúdo e a prosódia da voz fonte. Ao contrário dos métodos tradicionais, o StreamVC produz a forma de onda resultante com baixa latência no sinal de entrada, mesmo em plataformas móveis, tornando-o adequado para cenários de comunicação em tempo real, como chamadas telefônicas e videoconferências, bem como para anonimato de voz nesses cenários.
Destaques técnicos:
Tempo real: StreamVC é capaz de 70,8 milissegundos de inferência de baixa latência em dispositivos móveis.
Síntese de fala de alta qualidade: Utilize a arquitetura e a estratégia de treinamento do codec de áudio neural SoundStream para obter síntese de fala leve e de alta qualidade.
Estabilidade de tom: Ao introduzir informações de frequência fundamental (f0) esbranquiçadas, a consistência do tom é melhorada sem vazar as informações de timbre do locutor de origem.
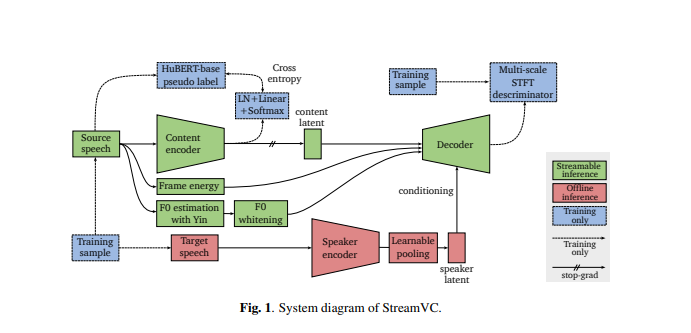
O design do StreamVC é inspirado em Soft-VC e SoundStream. Ele usa unidades de fala discretas extraídas pelo modelo HuBERT como alvos de previsão para a rede codificadora de conteúdo. A arquitetura do codificador e decodificador de conteúdo e a estratégia de treinamento são projetadas a partir do codec de áudio neural SoundStream para obter síntese de áudio causal de alta qualidade.
StreamVC foi comparado com tecnologias existentes em vários benchmarks, incluindo naturalidade, compreensibilidade, semelhança de alto-falante e consistência de tom. Os resultados experimentais mostram que o StreamVC tem um bom desempenho na preservação do tom do idioma de origem e é comparável ao modelo ajustado em termos de similaridade de locutor.
StreamVC prova que a conversão de som eficiente com baixa latência em dispositivos móveis é totalmente viável. Unidades de fala suave derivadas de HuBERT podem ser aprendidas por meio de uma arquitetura de rede neural convolucional causal streamável, e a injeção de informações f0 brancas no decodificador é crucial para fornecer saída de alta qualidade.
Endereço do artigo: https://arxiv.org/pdf/2401.03078
O surgimento da tecnologia StreamVC trouxe novas possibilidades para comunicação de voz em tempo real. Seus recursos de conversão de voz de baixa latência e alta qualidade promoverão a aplicação da tecnologia de voz em mais campos. Acredito que no futuro o StreamVC desempenhará um papel maior no anonimato de voz, efeitos especiais de voz, etc. Ansiosos por aplicativos mais inovadores baseados no StreamVC!