Recentemente, o Laboratório de Inteligência Artificial Tencent lançou um novo modelo chamado VTA-LDM, que foi projetado para converter com eficiência conteúdo de vídeo em áudio semanticamente e temporalmente consistente. A tecnologia central deste modelo reside no "alinhamento implícito", que combina perfeitamente com o conteúdo de áudio e vídeo gerado, melhorando significativamente a qualidade e os cenários de aplicação da geração de áudio. O editor de Downcodes levará você a um conhecimento aprofundado das inovações e perspectivas de aplicação do modelo VTA-LDM.
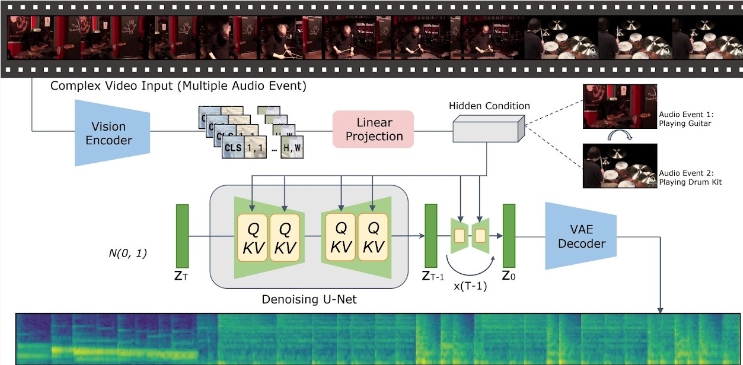
Com o progresso significativo na tecnologia de geração de texto para vídeo, como gerar conteúdo de áudio semanticamente e temporalmente consistente a partir da entrada de vídeo tornou-se um tema quente entre os pesquisadores. Recentemente, a equipe de pesquisa do Laboratório de Inteligência Artificial da Tencent lançou um novo modelo denominado "Vídeo Implicitamente Alinhado à Geração de Áudio" - VTA-LDM, que visa fornecer soluções eficientes de geração de áudio.
Entrada do projeto: https://top.aibase.com/tool/vta-ldm
A ideia central do modelo VTA-LDM é combinar o conteúdo de áudio e vídeo gerado semanticamente e temporalmente por meio da tecnologia de alinhamento implícito. Este método não só melhora a qualidade da geração de áudio, mas também amplia os cenários de aplicação da tecnologia de geração de vídeo. A equipe de pesquisa conduziu uma exploração aprofundada do design do modelo e combinou uma variedade de meios técnicos para garantir a precisão e consistência do áudio gerado.
A pesquisa concentra-se em três aspectos principais: codificadores visuais, embeddings auxiliares e técnicas de aumento de dados. A equipe de pesquisa primeiro estabeleceu um modelo básico e conduziu um grande número de experimentos de ablação com base nisso para avaliar o impacto de diferentes codificadores visuais e incorporações auxiliares no efeito de geração. Os resultados desses experimentos mostram que o modelo apresenta bom desempenho em termos de qualidade de geração e alinhamento simultâneo de vídeo e áudio, alcançando a vanguarda da tecnologia atual.
Em termos de inferência, os usuários só precisam colocar os videoclipes no diretório de dados especificado e executar o script de inferência fornecido para gerar o conteúdo de áudio correspondente. A equipe de pesquisa também fornece um conjunto de ferramentas para ajudar os usuários a mesclar o áudio gerado com o vídeo original, melhorando ainda mais a conveniência do aplicativo.
O modelo VTA-LDM atualmente oferece múltiplas versões de modelos diferentes para atender a diferentes necessidades de pesquisa. Esses modelos abrangem modelos básicos e uma variedade de modelos aprimorados, com o objetivo de fornecer aos usuários opções flexíveis para se adaptarem a vários experimentos e cenários de aplicação.
O lançamento do modelo VTA-LDM marca um progresso importante no campo da geração de vídeo para áudio. Os pesquisadores esperam usar este modelo para promover o desenvolvimento de tecnologias relacionadas e criar possibilidades de aplicação mais ricas.
## Destaques:
O surgimento do modelo VTA-LDM trouxe novos avanços no campo da geração de vídeo e áudio. Seus métodos de operação eficientes e convenientes e funções poderosas anunciam uma perspectiva de aplicação mais ampla no futuro. Acredita-se que com o desenvolvimento contínuo da tecnologia, o modelo VTA-LDM desempenhará um papel importante em mais campos.