Editor de Downcodes traz grandes novidades! A revolucionária tecnologia de aceleração do Transformer FlashAttention-3 é lançada oficialmente! Esta tecnologia revolucionará a velocidade de inferência e o custo de grandes modelos de linguagem (LLMs), alcançando melhorias de eficiência sem precedentes. A velocidade é aumentada de 1,5 a 2 vezes, a operação de baixa precisão (FP8) mantém alta precisão e os recursos de processamento de texto longo são significativamente aprimorados, o que trará novas possibilidades para aplicações de IA! Vamos dar uma olhada mais de perto nesta tecnologia inovadora.
A nova tecnologia de aceleração do Transformer FlashAttention-3 foi lançada. Esta não é apenas uma atualização, ela anuncia um aumento acentuado na velocidade de inferência e uma queda acentuada no custo de nossos grandes modelos de linguagem (LLMs)!
Vamos falar sobre este FlashAttention-3 primeiro. Comparado com a versão anterior, é simplesmente uma mudança de espingarda:
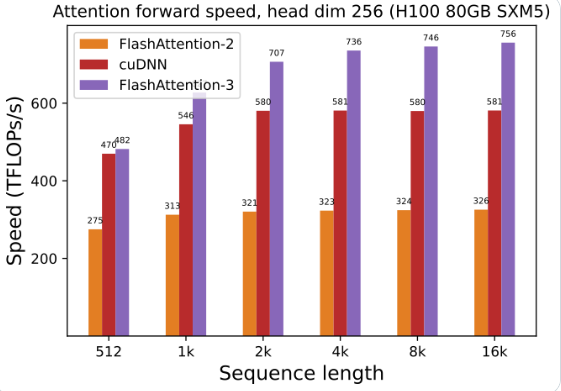
A utilização da GPU foi bastante melhorada: usando FlashAttention-3 para treinar e executar modelos de linguagem grandes, a velocidade é duplicada diretamente, 1,5 a 2 vezes mais rápida. Essa eficiência é incrível!
Baixa precisão, alto desempenho: Ele também pode funcionar com números de baixa precisão (FP8), mantendo a precisão. O que isso significa Menor custo sem comprometer o desempenho!
Processar textos longos é muito fácil: FlashAttention-3 aumenta muito a capacidade do modelo de IA de processar textos longos, o que antes era inimaginável.
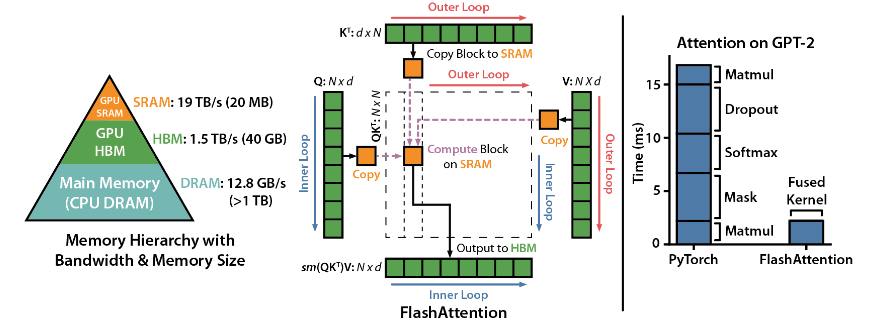
FlashAttention é uma biblioteca de código aberto desenvolvida por Dao-AILab. Ela é baseada em dois artigos pesados e fornece uma implementação otimizada do mecanismo de atenção em modelos de aprendizado profundo. Esta biblioteca é particularmente adequada para processar conjuntos de dados em grande escala e sequências longas. Existe uma relação linear entre o consumo de memória e o comprimento da sequência, que é muito mais eficiente do que a relação quadrática tradicional.
Destaques técnicos:
Suporte tecnológico avançado: atenção local, retropropagação determinística, ALiBi, etc. Essas tecnologias elevam o poder expressivo e a flexibilidade do modelo a um nível superior.
Otimização da GPU Hopper: FlashAttention-3 otimizou especialmente seu suporte à GPU Hopper e o desempenho foi melhorado em mais de um ponto e meio.
Fácil de instalar e usar: suporta CUDA11.6 e PyTorch1.12 ou superior, fácil de instalar com o comando pip no sistema Linux. Embora os usuários do Windows possam precisar de mais testes, definitivamente vale a pena tentar.
Funções principais:
Desempenho eficiente: O algoritmo otimizado reduz bastante os requisitos de computação e memória, especialmente para processamento de dados de sequência longa, e a melhoria de desempenho é visível a olho nu.
Otimização de memória: em comparação com os métodos tradicionais, o FlashAttention consome menos memória e o relacionamento linear faz com que o uso da memória não seja mais um problema.
Recursos avançados: a integração de uma variedade de tecnologias avançadas melhora muito o desempenho do modelo e o escopo da aplicação.
Facilidade de uso e compatibilidade: Guia simples de instalação e uso, juntamente com suporte para múltiplas arquiteturas de GPU, permitem que o FlashAttention-3 seja rapidamente integrado em uma variedade de projetos.
Endereço do projeto: https://github.com/Dao-AILab/flash-attention
O surgimento do FlashAttention-3 irá, sem dúvida, acelerar a aplicação e o desenvolvimento de modelos de linguagem em larga escala e trazer novos avanços no campo da inteligência artificial. Seu desempenho eficiente e facilidade de uso o tornam a escolha ideal para desenvolvedores. Apresse-se e experimente!