O editor de Downcodes revelará a verdade sobre modelos de linguagem visual (VLMs) com você! Você acha que os VLMs podem “entender” imagens como os humanos? A verdade não é tão simples. Este artigo explorará profundamente as limitações dos VLMs na compreensão de imagens e, por meio de uma série de resultados experimentais, mostrará a enorme lacuna entre eles e as capacidades visuais humanas. Você está pronto para mudar sua compreensão dos VLMs?
Todos deveriam ter ouvido falar de modelos de linguagem visual (VLMs). Esses pequenos especialistas na área de IA podem não apenas ler textos, mas também “ver” imagens. Mas este não é o caso. Hoje, vamos dar uma olhada em suas “cuecas” para ver se eles realmente conseguem “ver” e compreender imagens como nós, humanos.
Em primeiro lugar, devo apresentar alguns dados científicos populares sobre o que são VLMs. Simplificando, são modelos de linguagem grandes, como GPT-4o e Gemini-1.5Pro, que apresentam um desempenho muito bom no processamento de imagens e texto, e até alcançam pontuações altas em muitos testes de compreensão visual. Mas não se deixe enganar por essas pontuações altas, hoje vamos ver se elas são realmente incríveis.
Os pesquisadores desenvolveram um conjunto de testes chamado BlindTest, que contém sete tarefas extremamente simples para humanos. Por exemplo, determine se dois círculos se sobrepõem, se duas linhas se cruzam ou conte quantos círculos existem no logotipo olímpico. Parece que essas tarefas podem ser facilmente realizadas por crianças do jardim de infância? Mas deixe-me dizer, o desempenho desses VLMs não é tão impressionante?
Os resultados são chocantes. A precisão média desses chamados modelos avançados no BlindTest é de apenas 56,20%, e o melhor Sonnet-3.5 tem uma precisão de 73,77%. É como um excelente aluno que afirma ser capaz de entrar na Universidade de Tsinghua e na Universidade de Pequim, mas descobre que não consegue nem resolver corretamente as questões de matemática do ensino fundamental.

Por que isso está acontecendo? Os pesquisadores analisaram que pode ser porque os VLMs são como a miopia ao processar imagens e não conseguem ver os detalhes com clareza. Embora possam ver aproximadamente a tendência geral da imagem, quando se trata de informações espaciais precisas, como se dois gráficos se cruzam ou se sobrepõem, eles ficam confusos.
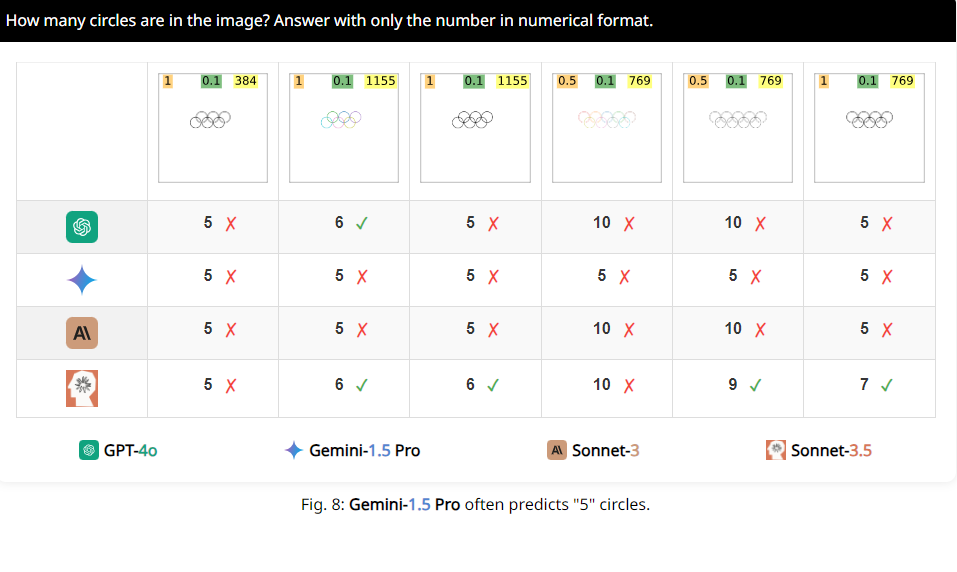
Por exemplo, os investigadores pediram aos VLMs que determinassem se dois círculos se sobrepunham e descobriram que, mesmo que os dois círculos fossem tão grandes como melancias, estes modelos ainda não conseguiam responder à pergunta com 100% de precisão. Além disso, quando solicitados a contar o número de círculos no logotipo olímpico, é difícil descrever seu desempenho.
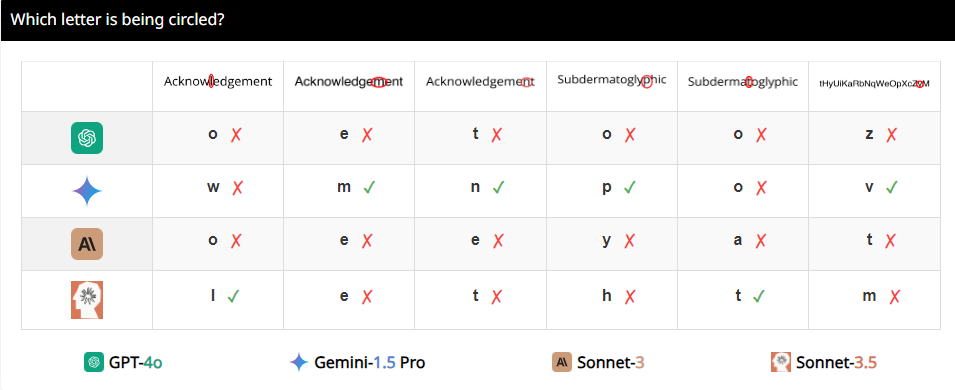
O mais interessante é que os pesquisadores também descobriram que esses VLMs pareciam ter uma preferência especial pelo número 5 durante a contagem. Por exemplo, quando o número de círculos no logotipo olímpico excede 5, eles tendem a responder “5”. Isto pode acontecer porque há 5 círculos no logotipo olímpico e eles estão particularmente familiarizados com este número.
Ok, tendo dito tudo isso, vocês têm uma nova compreensão desses VLMs aparentemente altos? Na verdade, eles ainda têm muitas limitações na compreensão visual, longe de atingirem o nosso nível humano. Então, da próxima vez que você ouvir alguém dizer que a IA pode substituir completamente os humanos, você pode rir.
Endereço do artigo: https://arxiv.org/pdf/2407.06581
Página do projeto: https://vlmsareblind.github.io/
Em resumo, embora os VLMs tenham feito progressos significativos no campo do reconhecimento de imagens, as suas capacidades de raciocínio espacial preciso ainda apresentam grandes deficiências. Este estudo lembra-nos que a avaliação da tecnologia de IA não pode basear-se apenas em pontuações elevadas, mas também requer uma compreensão profunda das suas limitações para evitar o otimismo cego. Esperamos que os VLMs façam avanços na compreensão visual no futuro!