O editor de Downcodes irá levá-lo para aprender sobre uma pesquisa inovadora do Google DeepMind: Mixture of Experts (MoE). Esta pesquisa fez um progresso revolucionário na arquitetura do Transformer. Seu núcleo está em um mecanismo de recuperação especializado com eficiência de parâmetros que usa tecnologia de chave de produto para equilibrar o custo computacional e o número de parâmetros, melhorando significativamente o potencial do modelo, mantendo a eficiência. Esta pesquisa não apenas explora configurações extremas do MoE, mas também prova pela primeira vez que a estrutura do índice de aprendizagem pode ser efetivamente encaminhada para mais de um milhão de especialistas, trazendo novas possibilidades para o campo da IA.
O modelo Mixture de um milhão de especialistas proposto pelo Google DeepMind é uma pesquisa que deu passos revolucionários na arquitetura do Transformer.
Imagine um modelo que possa realizar a recuperação esparsa de um milhão de microespecialistas. Isso parece um pouco com o enredo de um romance de ficção científica? Mas é exatamente isso que mostra a pesquisa mais recente da DeepMind. O núcleo desta pesquisa é um mecanismo de recuperação especializada com eficiência de parâmetros que utiliza tecnologia chave do produto para dissociar o custo computacional da contagem de parâmetros, liberando assim o maior potencial da arquitetura do Transformer, mantendo a eficiência computacional.
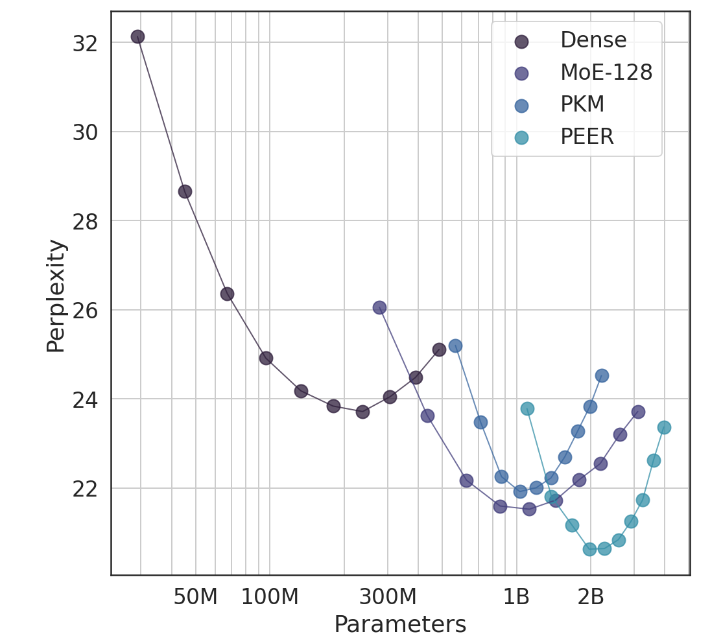
O destaque deste trabalho é que ele não apenas explora configurações extremas do MoE, mas também demonstra pela primeira vez que uma estrutura de índice aprendida pode ser encaminhada de forma eficiente para mais de um milhão de especialistas. É como encontrar rapidamente alguns especialistas que possam resolver o problema em uma grande multidão, e tudo isso é feito sob a premissa de custos de computação controláveis.
Em experimentos, a arquitetura PEER demonstrou desempenho computacional superior e foi mais eficiente do que FFW denso, MoE de granulação grossa e camadas de memória de chave de produto (PKM). Esta não é apenas uma vitória teórica, mas também um enorme salto na aplicação prática. Através dos resultados empíricos, podemos perceber o desempenho superior do PEER nas tarefas de modelagem de linguagem. Ele não só apresenta menor perplexidade, mas também no experimento de ablação, ao ajustar o número de especialistas e o número de especialistas ativos, o desempenho do PEER. modelo foi significativamente melhorado.
O autor deste estudo, Xu He (Owen), é um cientista pesquisador do Google DeepMind. Sua exploração sem dúvida trouxe novas revelações para o campo da IA. Como ele mostrou, através de métodos personalizados e inteligentes, podemos melhorar significativamente as taxas de conversão e reter usuários, o que é especialmente importante na área de AIGC.
Endereço do artigo: https://arxiv.org/abs/2407.04153
Em suma, a pesquisa de modelos híbridos de milhões de especialistas do Google DeepMind fornece novas idéias para a construção de modelos de linguagem em grande escala. Seu mecanismo eficiente de recuperação de especialistas e excelentes resultados experimentais indicam um grande potencial para o desenvolvimento futuro de modelos de IA. O editor do Downcodes aguarda resultados de pesquisas inovadoras mais semelhantes!