Nos últimos anos, inovações em grandes modelos de linguagem (LLM) surgiram uma após a outra, desafiando constantemente os limites das arquiteturas existentes. O editor do Downcodes aprendeu que pesquisadores de Stanford, UCSD, UC Berkeley e Meta propuseram conjuntamente uma nova arquitetura chamada TTT (camadas de treinamento em tempo de teste). Com seu design inovador, espera-se que mude completamente nossa compreensão da linguagem. modelo é reconhecido e aplicado. Ao combinar habilmente as vantagens do RNN e do Transformer, a arquitetura TTT melhora significativamente a capacidade expressiva do modelo, ao mesmo tempo que garante a complexidade linear. Ele tem um desempenho particularmente bom no processamento de textos longos, trazendo novos insights para campos como a possibilidade de modelagem de vídeos longos.
No mundo da IA, a mudança sempre ocorre de forma inesperada. Recentemente, surgiu uma nova arquitetura chamada TTT. Foi proposta em conjunto por pesquisadores de Stanford, UCSD, UC Berkeley e Meta. Ela subverteu o Transformer e o Mamba da noite para o dia e trouxe mudanças revolucionárias nos modelos de linguagem.
TTT, o nome completo das camadas Test-Time-Training, é uma arquitetura totalmente nova que comprime o contexto por meio de gradiente descendente e substitui diretamente o mecanismo de atenção tradicional. Essa abordagem não apenas melhora a eficiência, mas também desbloqueia uma arquitetura de complexidade linear com memória expressiva, permitindo-nos treinar LLMs contendo milhões ou até bilhões de tokens em contexto.

A proposta da camada TTT é baseada em insights profundos sobre as arquiteturas RNN e Transformer existentes. Embora o RNN seja altamente eficiente, ele é limitado por sua capacidade expressiva, enquanto o Transformer possui forte capacidade expressiva, mas seu custo computacional aumenta linearmente com o comprimento do contexto; A camada TTT combina de forma inteligente as vantagens de ambos, mantendo a complexidade linear e aprimorando as capacidades expressivas.
Em experimentos, ambas as variantes, TTT-Linear e TTT-MLP, demonstraram excelente desempenho, superando o Transformer e o Mamba em contextos curtos e longos. Especialmente em cenários de contexto longo, as vantagens da camada TTT são mais óbvias, o que oferece um enorme potencial para cenários de aplicação, como modelagem de vídeo longo.
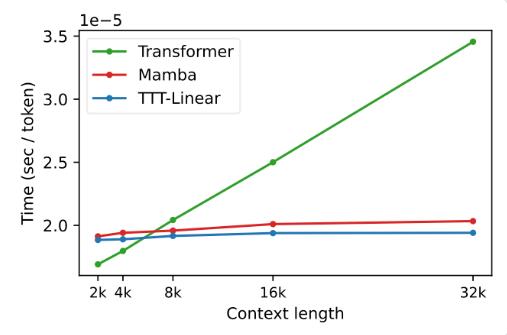
A proposta da camada TTT não é apenas inovadora na teoria, mas também apresenta grande potencial em aplicações práticas. No futuro, espera-se que a camada TTT seja aplicada à modelagem de vídeos longos para fornecer informações mais ricas por meio de amostragem densa de quadros. Isso é um fardo para o Transformer, mas é uma bênção para a camada TTT.
Esta pesquisa é o resultado de cinco anos de trabalho árduo da equipe e vem sendo desenvolvida desde o pós-doutorado do Dr. Yu Sun. Eles persistiram em explorar e tentar e finalmente alcançaram esse resultado inovador. O sucesso da camada TTT é o resultado dos esforços incessantes e do espírito inovador da equipe.
O advento da camada TTT trouxe nova vitalidade e possibilidades ao campo da IA. Isso não apenas muda a nossa compreensão dos modelos de linguagem, mas também abre um novo caminho para futuras aplicações de IA. Aguardemos com expectativa a futura aplicação e desenvolvimento da camada TTT e testemunhemos o progresso e os avanços da tecnologia de IA.
Endereço do artigo: https://arxiv.org/abs/2407.04620
O surgimento da arquitetura TTT sem dúvida injetou um impulso no campo da IA. Seu progresso revolucionário no processamento de textos longos indica que as futuras aplicações de IA terão capacidades de processamento mais poderosas e perspectivas de aplicação mais amplas. Vamos esperar e ver como a arquitetura TTT mudará ainda mais o nosso mundo.