O editor do Downcodes traz grandes novidades para você! A Cerebras Systems lançou o serviço de inferência de IA mais rápido do mundo - Cerebras Inference, que mudou completamente as regras do jogo no campo da inferência de IA com sua incrível velocidade e preço extremamente competitivo. Ele tem um bom desempenho no processamento de vários modelos de IA, especialmente modelos de linguagem grande (LLMs), e é 20 vezes mais rápido que os sistemas GPU tradicionais a um preço tão baixo quanto um décimo ou até um centésimo. Como isso afetará o desenvolvimento futuro de aplicações de IA? Vamos dar uma olhada mais de perto.
A Cerebras Systems, pioneira em computação de IA de desempenho, lançou uma solução inovadora que revolucionará a inferência de IA. Em 27 de agosto de 2024, a empresa anunciou o lançamento do Cerebras Inference, o serviço de inferência de IA mais rápido do mundo. Os indicadores de desempenho do Cerebras Inference superam os sistemas tradicionais baseados em GPU, fornecendo 20 vezes mais velocidade a um custo extremamente baixo, estabelecendo um novo padrão para a computação de IA.
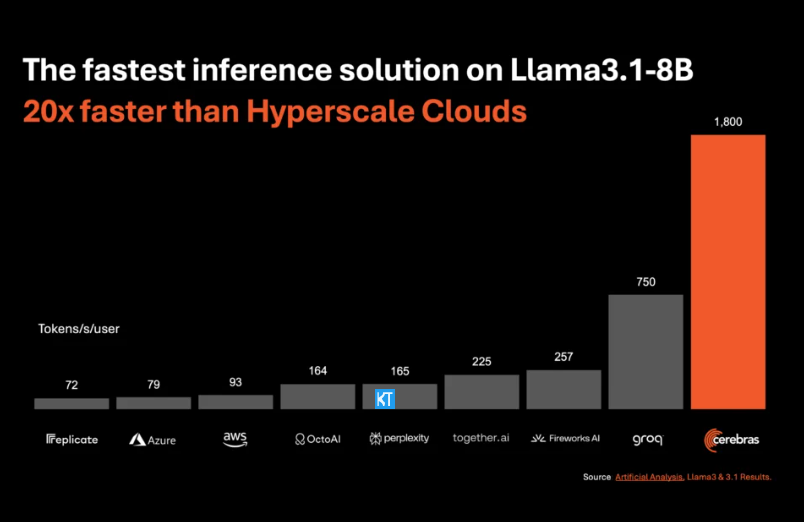
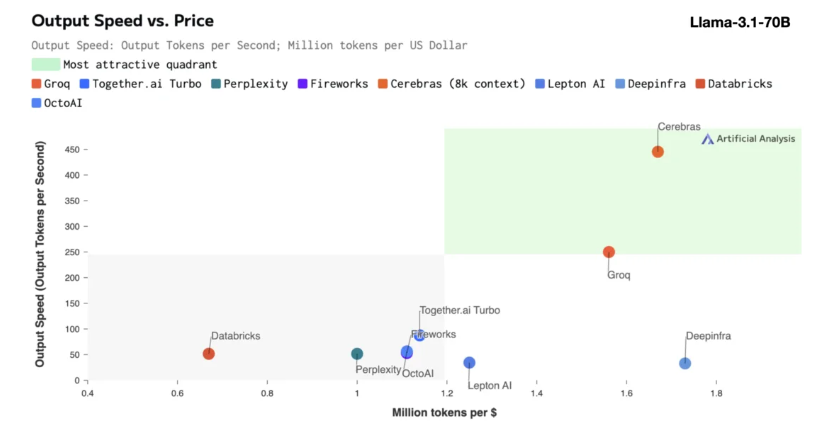
A inferência do Cerebras é particularmente adequada para processar vários tipos de modelos de IA, especialmente os "grandes modelos de linguagem" (LLMs) de rápido desenvolvimento. Tomando como exemplo o modelo Llama3.1 mais recente, sua versão 8B pode processar 1.800 tokens por segundo, enquanto a versão 70B pode processar 450 tokens. Isso não é apenas 20 vezes mais rápido que as soluções de GPU NVIDIA, mas também tem um preço mais competitivo. O preço do Cerebras Inference começa em apenas 10 centavos por milhão de tokens, e a versão 70B custa 60 centavos. Em comparação com os produtos GPU existentes, a relação preço/desempenho é melhorada em 100 vezes.
É impressionante que o Cerebras Inference atinja essa velocidade enquanto mantém a precisão líder do setor. Ao contrário de outras soluções que priorizam a velocidade, a Cerebras sempre realiza inferências no domínio de 16 bits, garantindo que as melhorias de desempenho não ocorram às custas da qualidade de saída do modelo de IA. Micha Hill-Smith, CEO da Artificial Analytics, disse que a Cerebras alcançou uma velocidade de mais de 1.800 tokens de saída por segundo no modelo Llama3.1 da Meta, estabelecendo um novo recorde.
A inferência de IA é o segmento de computação de IA que mais cresce, respondendo por aproximadamente 40% de todo o mercado de hardware de IA. A inferência de IA de alta velocidade, como a fornecida pela Cerebras, é como o surgimento da Internet de banda larga, abrindo novas oportunidades e inaugurando uma nova era para aplicações de IA. Os desenvolvedores podem usar o Cerebras Inference para construir aplicativos de IA de próxima geração que exigem desempenho complexo em tempo real, como agentes inteligentes e sistemas inteligentes.
Cerebras Inference oferece três níveis de serviço com preços razoáveis: nível gratuito, nível de desenvolvedor e nível empresarial. O nível gratuito fornece acesso à API com limites de uso generosos, tornando-o ideal para uma ampla gama de usuários. A camada de desenvolvedor oferece opções flexíveis de implantação sem servidor, enquanto a camada empresarial fornece serviços personalizados e suporte para organizações com cargas de trabalho contínuas.
Em termos de tecnologia central, o Cerebras Inference usa o sistema CerebrasCS-3, impulsionado pelo Wafer Scale Engine3 (WSE-3) líder do setor. Este processador AI é incomparável em escala e velocidade, fornecendo 7.000 vezes mais largura de banda de memória do que o NVIDIA H100.
A Cerebras Systems não apenas lidera a tendência no campo da computação de IA, mas também desempenha um papel importante em vários setores, como médico, energia, governo, computação científica e serviços financeiros. Ao avançar continuamente na inovação tecnológica, a Cerebras está ajudando organizações em diversas áreas a enfrentar desafios complexos de IA.
Destaque:
A velocidade de atendimento da Cerebras Systems aumentou 20 vezes, seu preço é mais competitivo e abre uma nova era de raciocínio de IA.
Suporta vários modelos de IA, especialmente com bom desempenho em modelos de linguagem grandes (LLMs).
Três níveis de serviço são fornecidos para facilitar a escolha flexível dos desenvolvedores e usuários corporativos.
Em suma, o surgimento da Inferência Cerebras marca um marco importante no campo da inferência de IA. Seu excelente desempenho e economia promoverão a ampla popularização e o desenvolvimento inovador de aplicações de IA, e merece a atenção e a expectativa da indústria! O editor de Downcodes continuará trazendo mais informações sobre tecnologia de ponta.