Hoje, com o rápido desenvolvimento da tecnologia de IA, os modelos de linguagem pequena (SLM) atraíram muita atenção devido à sua capacidade de execução em dispositivos com recursos limitados. A equipe da Nvidia lançou recentemente o Llama-3.1-Minitron4B, um excelente modelo de linguagem pequena baseado na compactação do modelo Llama 3. Ele utiliza tecnologias de poda e destilação de modelos para rivalizar com modelos maiores em desempenho, ao mesmo tempo que possui vantagens eficientes de treinamento e implantação, trazendo novas possibilidades para aplicações de IA. O editor de Downcodes levará você a um conhecimento profundo desse avanço tecnológico.
Numa era em que as empresas tecnológicas procuram a inteligência artificial nos dispositivos, estão a surgir cada vez mais modelos de linguagem pequena (SLM) que podem ser executados em dispositivos com recursos limitados. Recentemente, a equipe de pesquisa da Nvidia usou tecnologia de ponta de poda e destilação de modelos para lançar o Llama-3.1-Minitron4B, uma versão compactada do modelo Llama3. Este novo modelo não é apenas comparável em desempenho a modelos maiores, mas também compete com modelos menores do mesmo tamanho, sendo ao mesmo tempo mais eficiente em treinamento e implantação.
A poda e a destilação são duas técnicas principais para a criação de modelos de linguagem menores e mais eficientes. A poda refere-se à remoção de partes sem importância do modelo, incluindo "poda de profundidade" - remoção de camadas inteiras, e "poda de largura" - remoção de elementos específicos, como neurônios e cabeças de atenção. A destilação de modelo, por outro lado, transfere conhecimento e capacidades de um modelo grande (ou seja, “modelo de professor”) para um “modelo de aluno” menor e mais simples.
Existem dois métodos principais de destilação. O primeiro é através do "treinamento SGD", que permite ao modelo do aluno aprender a entrada e a resposta do modelo do professor. O segundo é a "destilação do conhecimento clássico". o modelo do aluno também precisa da ativação interna do modelo do professor em aprendizagem.
Em um estudo anterior, os pesquisadores da Nvidia reduziram com sucesso o modelo Nemotron15B para um modelo de 800 milhões de parâmetros por meio de poda e destilação e, eventualmente, reduziram-no ainda mais para 400 milhões de parâmetros. Este processo não só melhora o desempenho em 16% no famoso benchmark MMLU, mas também requer 40 vezes menos dados de treinamento do que o treinamento do zero.
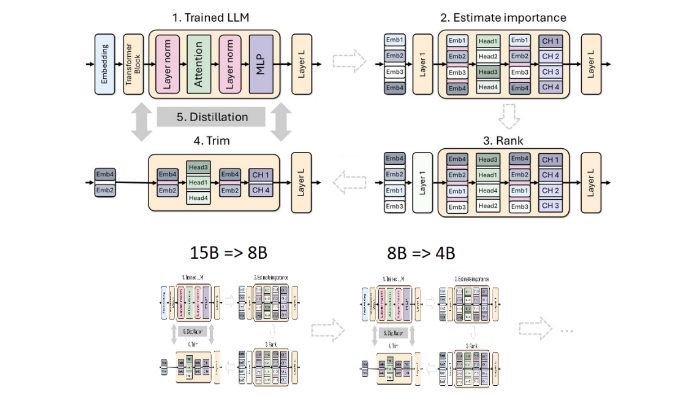
Desta vez, a equipe da Nvidia usou o mesmo método para criar um modelo de 400 milhões de parâmetros baseado no modelo Llama3.18B. Primeiro, eles ajustaram o modelo 8B não podado em um conjunto de dados contendo 94 bilhões de tokens para lidar com as diferenças de distribuição entre os dados de treinamento e o conjunto de dados destilado. Em seguida, foram utilizados dois métodos de poda em profundidade e poda em largura e, finalmente, foram obtidas duas versões diferentes do Llama-3.1-Minitron4B.
Os pesquisadores ajustaram o modelo podado por meio do NeMo-Aligner e avaliaram suas capacidades em acompanhamento de instruções, dramatização, geração de aumento de recuperação (RAG) e chamada de função.
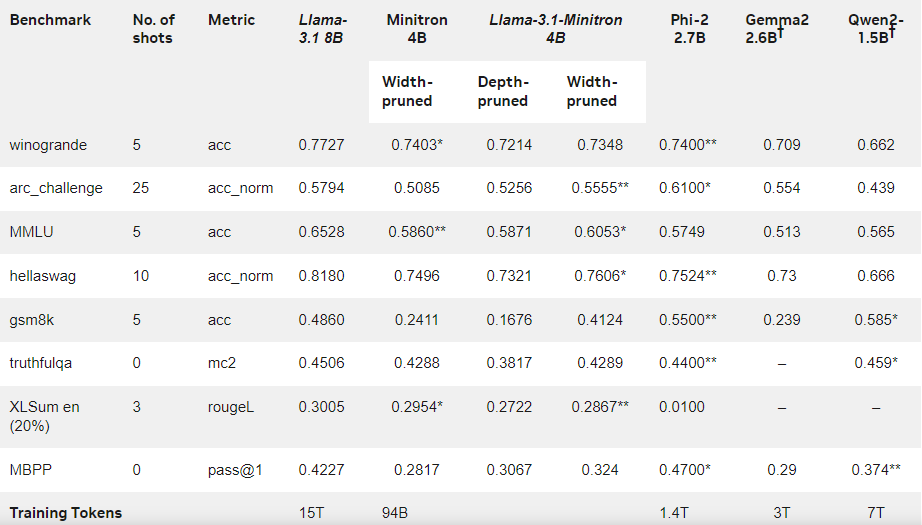
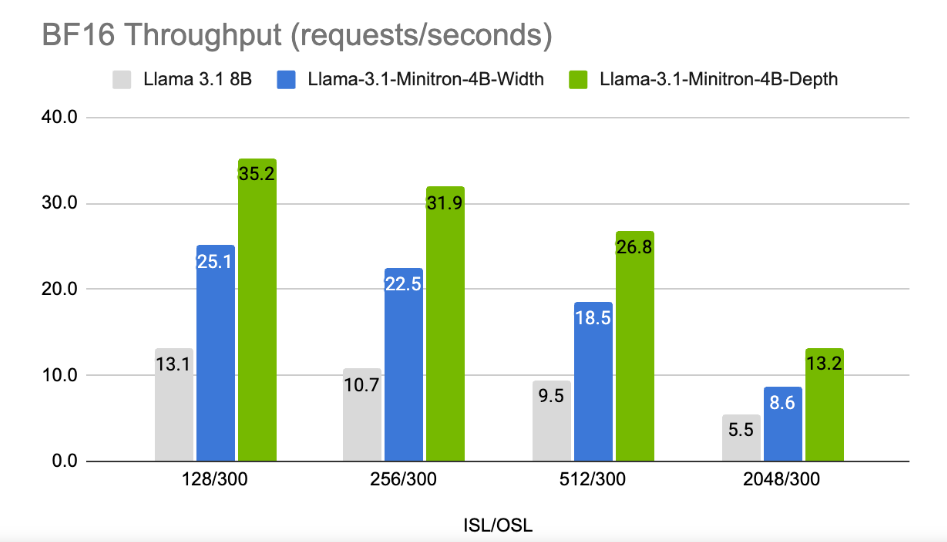
Os resultados mostram que apesar da pequena quantidade de dados de treinamento, o desempenho do Llama-3.1-Minitron4B ainda está próximo de outros modelos pequenos e tem um bom desempenho. A versão com largura reduzida do modelo foi lançada no Hugging Face, permitindo o uso comercial para ajudar mais usuários e desenvolvedores a se beneficiarem de sua eficiência e excelente desempenho.
Blog oficial: https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model /
Destaque:
Llama-3.1-Minitron4B é um modelo de linguagem pequena lançado pela Nvidia baseado em tecnologia de poda e destilação, com treinamento eficiente e recursos de implantação.
A quantidade de marcadores utilizados no processo de treinamento deste modelo é reduzida em 40 vezes em comparação com o treinamento do zero, mas o desempenho é significativamente melhorado.
? A versão de poda de largura foi lançada no Hugging Face para facilitar o uso comercial e o desenvolvimento dos usuários.
Em suma, o surgimento do Llama-3.1-Minitron4B marca um novo marco no desenvolvimento de modelos de linguagem pequena. Seu desempenho eficiente e método de implantação conveniente trarão boas notícias para mais desenvolvedores e usuários e acelerarão a popularização e aplicação da tecnologia de IA. O editor do Downcodes espera mais inovações semelhantes no futuro.