No treinamento de modelos de linguagem grande (LLM), o mecanismo de checkpoint é crucial, pois pode efetivamente evitar enormes perdas causadas por interrupções de treinamento. No entanto, os sistemas tradicionais de checkpoint muitas vezes enfrentam gargalos de E/S e são ineficientes. Para este fim, cientistas da ByteDance e da Universidade de Hong Kong propuseram um novo sistema de checkpoint denominado ByteCheckpoint, que pode melhorar significativamente a eficiência do treinamento LLM.
Num mundo digital dominado por dados e algoritmos, cada passo do crescimento da inteligência artificial é inseparável de um elemento-chave – o ponto de verificação. Imagine que quando você está treinando um modelo de linguagem em larga escala que pode entender a mente das pessoas e responder perguntas com fluência, esse modelo é extremamente inteligente, mas também é um grande devorador e requer enormes recursos de computação para alimentá-lo. Durante o processo de treinamento, se houver uma queda repentina de energia ou falha de hardware, a perda será enorme. Neste momento, o posto de controle é como uma máquina do tempo, permitindo que tudo retorne ao estado seguro anterior e continue as tarefas inacabadas.
No entanto, a própria máquina do tempo também exigia um design cuidadoso. Cientistas da ByteDance e da Universidade de Hong Kong nos trouxeram um novo sistema de checkpoint - ByteCheckpoint no artigo "ByteCheckpoint: A Unified Checkpointing System for LLM Development". Não é apenas uma ferramenta de backup simples, mas também um artefato que pode melhorar significativamente a eficiência do treinamento de grandes modelos de linguagem.
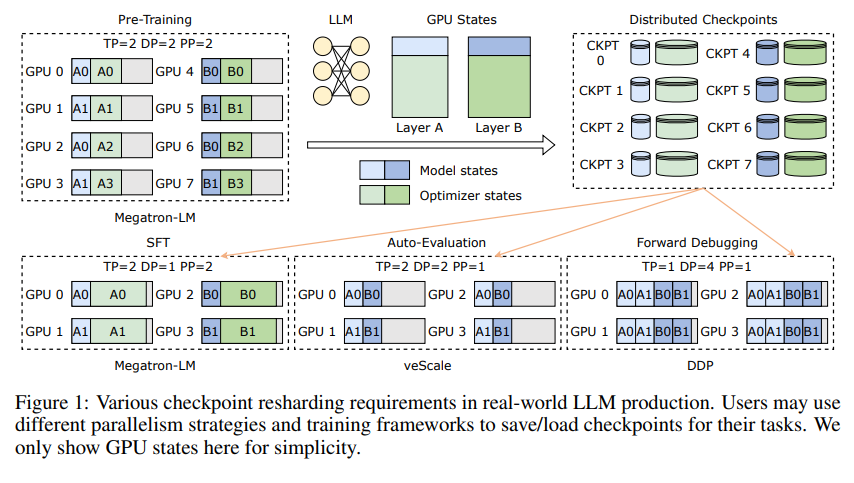
Primeiro, precisamos compreender os desafios enfrentados pelos grandes modelos de linguagem (LLMs). A razão pela qual estes modelos são grandes é que eles precisam processar e lembrar grandes quantidades de informações, o que traz problemas como altos custos de treinamento, grande consumo de recursos e fraca tolerância a falhas. Quando ocorre um mau funcionamento, um longo período de treinamento pode ser insatisfatório.
O sistema de checkpoint é como um instantâneo do modelo, salvando o estado regularmente durante o processo de treinamento, para que mesmo que algo dê errado, ele possa ser rapidamente restaurado ao estado mais recente e reduzir as perdas. No entanto, os sistemas de checkpoint existentes muitas vezes sofrem de ineficiências devido a gargalos de E/S (entrada/saída) ao processar modelos grandes.
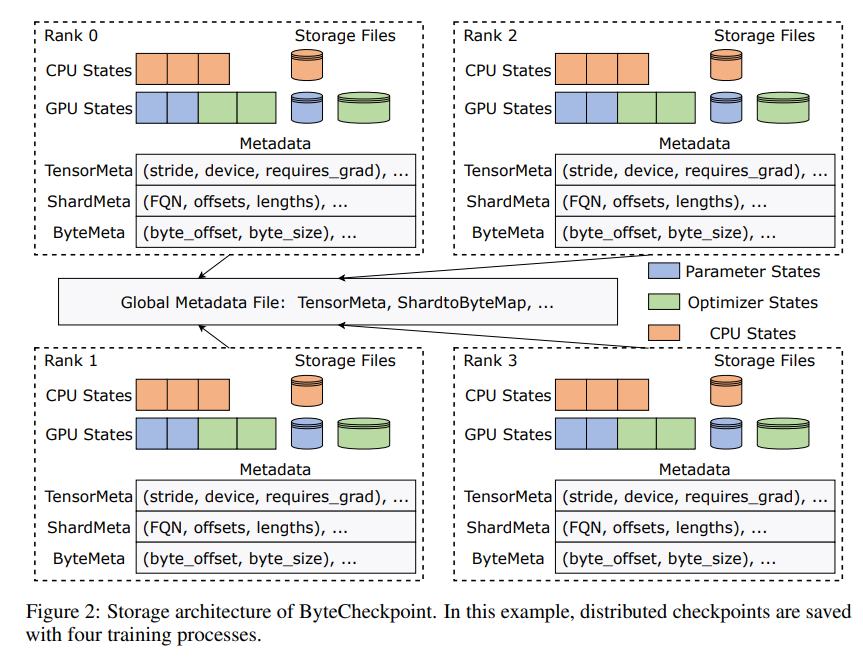
A inovação do ByteCheckpoint reside na adoção de uma nova arquitetura de armazenamento que separa dados e metadados e lida com pontos de verificação de forma mais flexível sob diferentes configurações paralelas e estruturas de treinamento. Melhor ainda, ele suporta reestilhaçamento automático de pontos de verificação online, que pode ajustar dinamicamente os pontos de verificação para se adaptarem a diferentes ambientes de hardware sem interromper o treinamento.
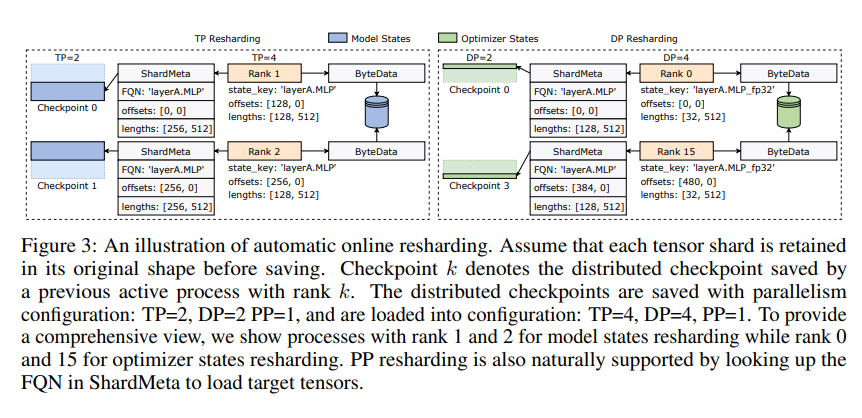
ByteCheckpoint também introduz uma tecnologia chave - fusão assíncrona de tensores. Isso pode lidar com tensores distribuídos de forma desigual em diferentes GPUs com eficiência, garantindo que a integridade e a consistência do modelo não sejam afetadas quando o ponto de verificação for fragmentado novamente.
Para melhorar a velocidade de salvamento e carregamento de pontos de verificação, o ByteCheckpoint também integra uma série de medidas de otimização de desempenho de E/S, como pipeline sofisticado de salvamento/carregamento, pool de memória Ping-Pong, salvamento balanceado de carga de trabalho e carga com redundância zero, etc. , o que reduz bastante o tempo de espera durante o processo de treinamento.
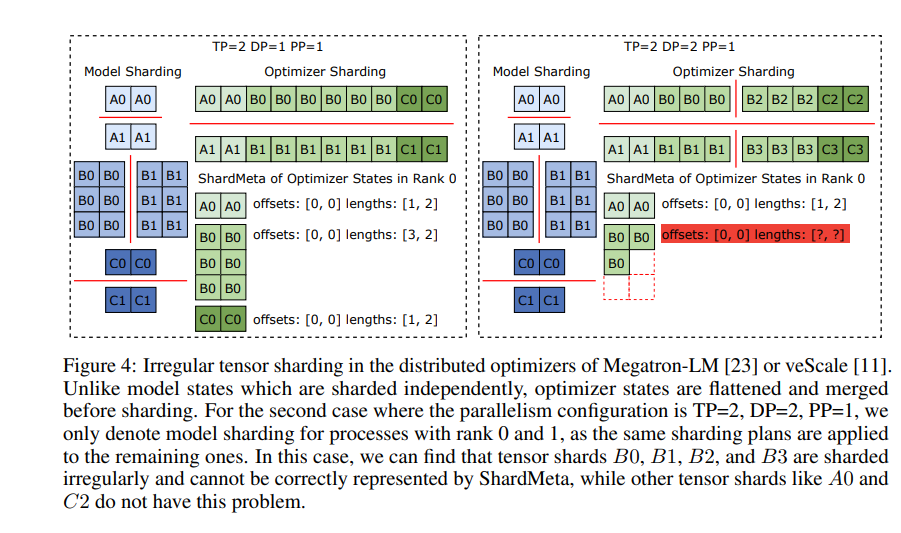
Através da verificação experimental, em comparação com os métodos tradicionais, as velocidades de salvamento e carregamento de pontos de verificação do ByteCheckpoint são aumentadas em dezenas ou mesmo centenas de vezes, respectivamente, melhorando significativamente a eficiência de treinamento de grandes modelos de linguagem.
ByteCheckpoint não é apenas um sistema de checkpoint, mas também um poderoso assistente no processo de treinamento de grandes modelos de linguagem. É a chave para um treinamento de IA mais eficiente e estável.
Endereço do artigo: https://arxiv.org/pdf/2407.20143
O editor de Downcodes resume: O surgimento do ByteCheckpoint resolve o problema da baixa eficiência dos pontos de verificação no treinamento LLM e fornece forte suporte técnico para o desenvolvimento de IA. Vale a pena prestar atenção!