O projeto mais recente da Meta AI, Llama3, atraiu ampla atenção. O editor de Downcodes lhe dará uma compreensão profunda de sua tecnologia principal e direção de desenvolvimento futuro. O pesquisador de Meta AI, Thomas Scialom, foi entrevistado recentemente, compartilhando os detalhes do desenvolvimento do Llama3 e fornecendo insights exclusivos sobre os problemas existentes no treinamento de modelos de linguagem em larga escala. Ele enfatizou particularmente o importante papel dos dados sintéticos no treinamento do Llama3 e como usar efetivamente o feedback humano para melhorar o desempenho do modelo. Este artigo explicará detalhadamente os métodos de treinamento, áreas de aplicação e planos de desenvolvimento futuro do Llama3, apresentando aos leitores uma perspectiva abrangente e aprofundada.
Thomas Scialom, pesquisador da Meta AI, compartilhou recentemente alguns insights sobre seu projeto mais recente, Llama3, em uma entrevista. Ele ressalta sem rodeios que as grandes quantidades de texto na web são de qualidade variável e acredita que o treinamento com base nesses dados é um desperdício de recursos. Portanto, o processo de treinamento do Llama3 não depende de respostas escritas por humanos, mas é inteiramente baseado nos dados sintéticos gerados pelo Llama2.
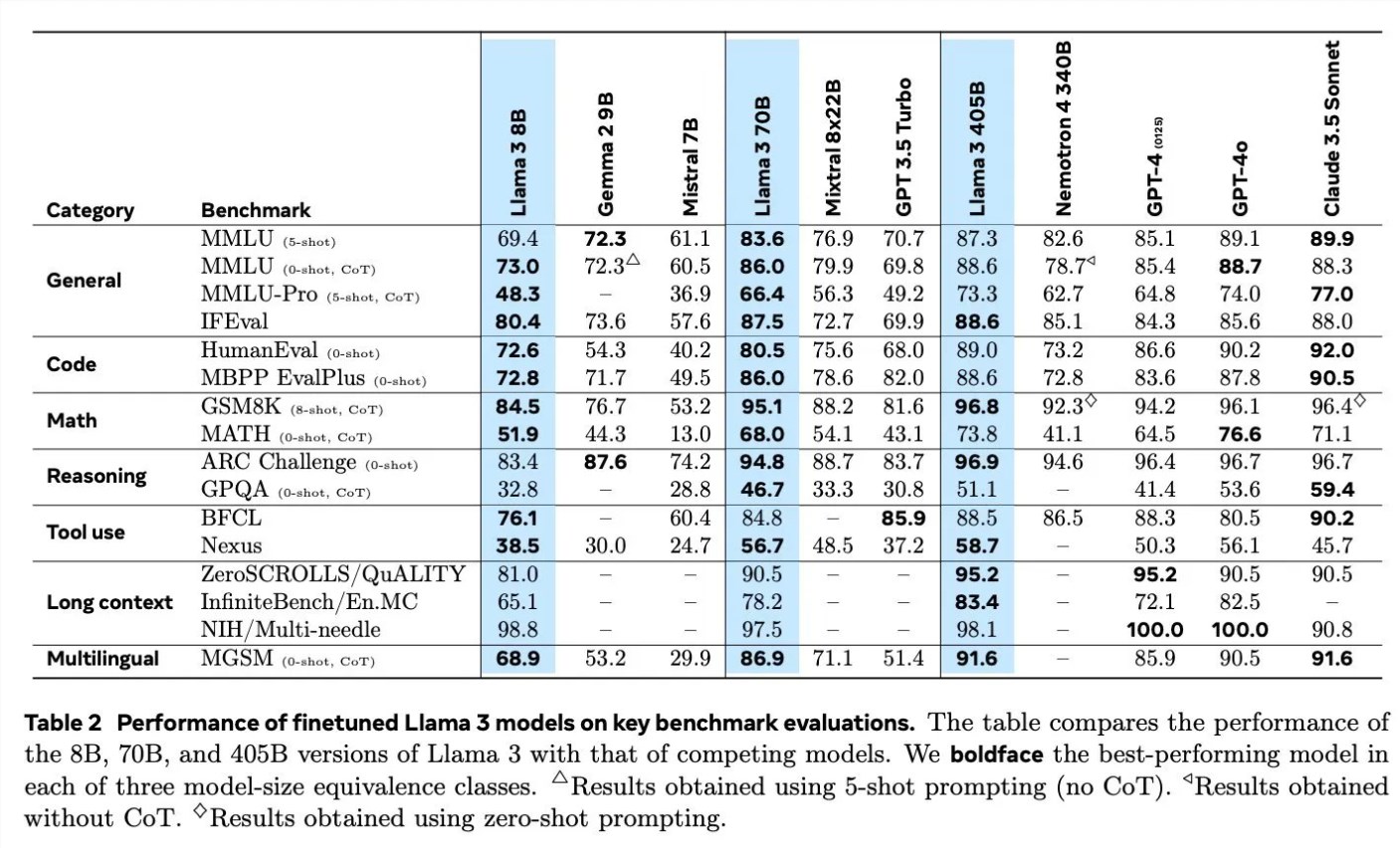
Ao discutir os detalhes do treinamento do Llama3, Scialom detalhou a aplicação de dados sintéticos em diferentes campos. Por exemplo, em termos de geração de código, utilizaram três métodos diferentes para gerar dados sintéticos, incluindo feedback da execução de código, tradução de linguagens de programação e retrotradução de documentação. Em termos de raciocínio matemático, basearam-se na abordagem de investigação “vamos passo a passo” para a geração de dados. Além disso, o Llama3 continua a ser pré-treinado com 90% de tokens multilíngues para coletar anotações humanas de alta qualidade, o que é particularmente importante no processamento multilíngue.
O processamento de textos longos também é um foco do Llama3, e eles contam com dados sintéticos para lidar com respostas a perguntas de textos longos, resumo de documentos longos e inferência de base de código. Em termos de uso de ferramentas, Llama3 foi treinado em Brave search, Wolfram Alpha e intérpretes Python para implementar chamadas de função únicas, aninhadas, paralelas e multi-rodadas.
Scialom também mencionou a importância do aprendizado por reforço com feedback humano (RLHF) no treinamento do Llama3. Eles fizeram uso extensivo de dados de preferência humana para treinar o modelo, enfatizando a capacidade dos humanos de fazer escolhas (como escolher qual dos dois poemas preferir) em vez de começar do zero.
Meta iniciou o treinamento do Llama4 em junho, e Scialom revelou que o foco principal do Llama4 será em torno do agente inteligente. Além disso, ele também mencionou uma versão multimodal do Llama, que terá mais parâmetros e está prevista para ser lançada em um futuro próximo.
A entrevista de Scialom revela os últimos progressos e direções de desenvolvimento futuro da Meta AI no campo da inteligência artificial, especialmente em como usar dados sintéticos e feedback humano para melhorar o desempenho do modelo.
Através da entrevista do Scialom, aprendemos sobre as inovações do Llama3 na utilização de dados e treinamento de modelos, bem como a exploração contínua da Meta AI no campo de modelos de linguagem em larga escala. A experiência bem-sucedida do Llama3 fornece uma referência valiosa para o desenvolvimento de futuros modelos de inteligência artificial e também indica que a tecnologia de inteligência artificial se desenvolverá numa direção mais precisa e eficiente. O editor do Downcodes aguarda com expectativa o lançamento do Llama4 e do Llama multimodal e continua prestando atenção ao progresso revolucionário da Meta AI no campo da inteligência artificial.