Grande lançamento da Meta Company! Open source seu mais recente modelo de linguagem grande Llama 3.1 405B, com um volume de parâmetro de até 128 bilhões, e seu desempenho é comparável ao GPT-4 em múltiplas tarefas. Após um ano de preparação cuidadosa, desde o planejamento do projeto até a revisão final, os modelos da série Llama 3 finalmente chegam ao público. Este código aberto não inclui apenas o modelo em si, mas também seu processamento otimizado de dados pré-treinamento, garantia de qualidade de dados pós-treinamento e tecnologia de quantificação eficiente para reduzir os requisitos de computação e facilitar o uso pelos desenvolvedores. O editor de Downcodes explicará detalhadamente as melhorias e destaques do Llama 3.1 405B.
Ontem à noite, Meta anunciou o código aberto de seu mais recente modelo de linguagem grande, Llama3.1 405B. Esta grande novidade marca que após um ano de preparação cuidadosa, desde o planejamento do projeto até a revisão final, os modelos da série Llama3 finalmente chegaram ao público.
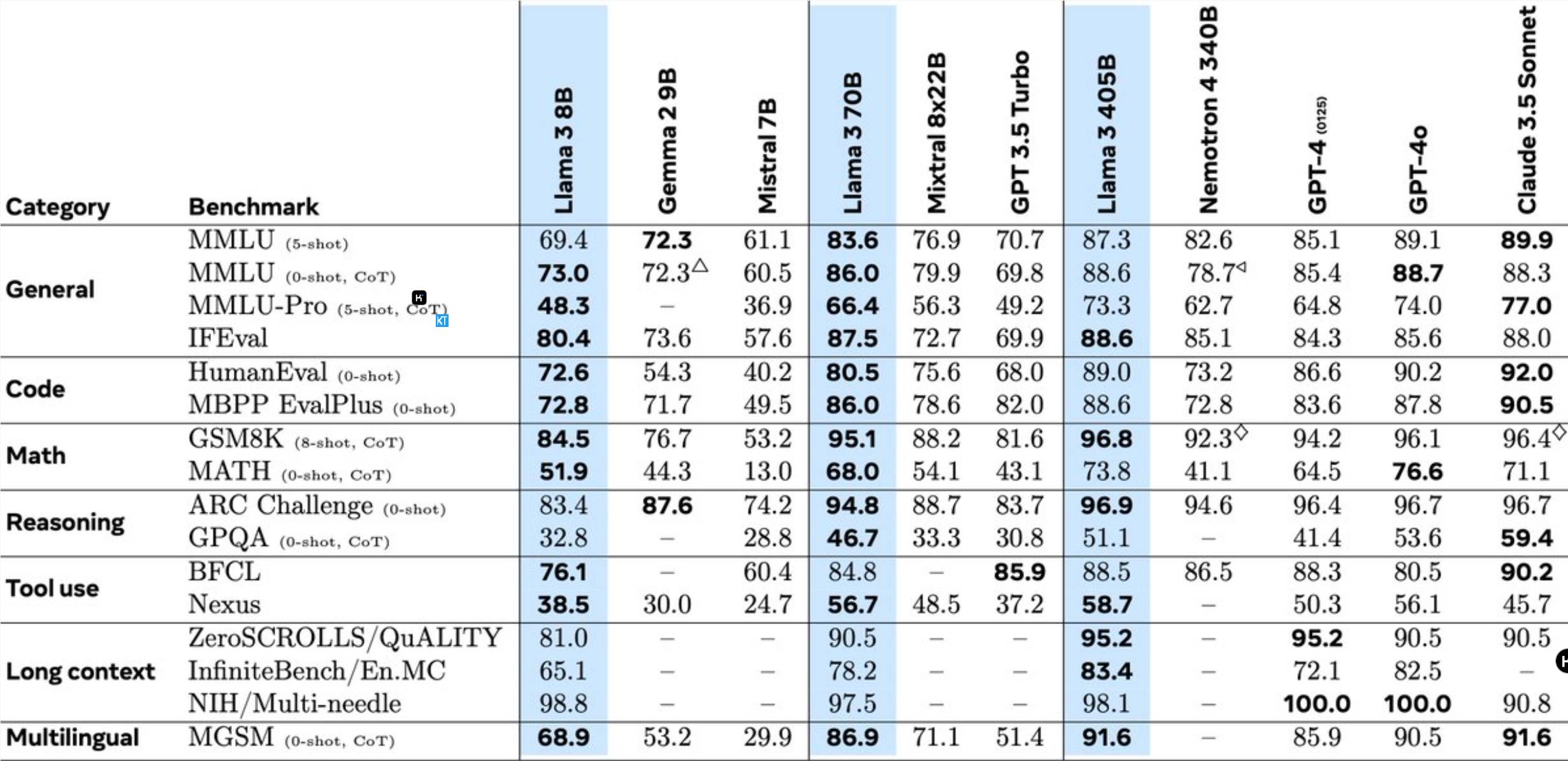
Llama3.1405B é um modelo de uso de ferramenta multilíngue com 128 bilhões de parâmetros. Após o pré-treinamento com comprimento de contexto de 8K, o modelo é treinado posteriormente com comprimento de contexto de 128K. De acordo com Meta, o desempenho deste modelo em múltiplas tarefas é comparável ao GPT-4, líder do setor.
Comparado com o modelo Llama anterior, o Meta foi otimizado em muitos aspectos:
O pré-treinamento do modelo 405B é um enorme desafio, envolvendo 15,6 trilhões de tokens e operações de ponto flutuante 3,8x10^25. Para isso, a Meta otimizou toda a arquitetura de treinamento e utilizou mais de 16.000 GPUs H100.
Para suportar a inferência de produção em massa do modelo 405B, a Meta quantizou-o de 16 bits (BF16) para 8 bits (FP8), reduzindo significativamente os requisitos de computação e permitindo que um único nó de servidor execute o modelo.
Além disso, Meta utiliza o modelo 405B para melhorar a qualidade pós-treinamento dos modelos 70B e 8B. Na fase pós-treinamento, a equipe refinou o modelo de chat por meio de múltiplas rodadas de processos de alinhamento, incluindo ajuste fino supervisionado (SFT), amostragem de rejeição e otimização de preferência direta. É importante notar que a maioria das amostras de OFVM são geradas a partir de dados sintéticos.
O Llama3 também integra funções de imagem, vídeo e voz, usando uma abordagem combinada para permitir que o modelo reconheça imagens e vídeos e suporte a interação por voz. No entanto, esses recursos ainda estão em desenvolvimento e ainda não foram lançados oficialmente.
A Meta também atualizou seu contrato de licença para permitir que os desenvolvedores usem o resultado do modelo Llama para melhorar outros modelos.
Pesquisadores da Meta disseram: É extremamente emocionante trabalhar na vanguarda da IA com os principais talentos do setor e publicar resultados de pesquisas de forma aberta e transparente. Estamos ansiosos para ver a inovação que os modelos de código aberto trazem e o potencial para os futuros modelos da série Llama!
Esta iniciativa de código aberto trará, sem dúvida, novas oportunidades e desafios ao campo da IA e promoverá o desenvolvimento de tecnologias de modelos de linguagem de grande porte.
O código aberto do Llama 3.1 405B promoverá enormemente o avanço da tecnologia de modelos de linguagem de grande porte e trará mais possibilidades para o campo de IA. Esperamos que os desenvolvedores criem mais aplicativos incríveis baseados neste modelo!