Melhorar a eficiência de grandes modelos de linguagem sempre foi um ponto importante de pesquisa no campo da inteligência artificial. Recentemente, equipes de pesquisa da Aleph Alpha, da Universidade Técnica de Darmstadt e de outras instituições desenvolveram um novo método chamado T-FREE, que melhora significativamente a eficiência operacional de grandes modelos de linguagem. Este método reduz o número de parâmetros da camada de incorporação usando triplos de caracteres para ativação esparsa e modela efetivamente a similaridade morfológica entre as palavras. Ele reduz bastante o consumo de recursos de computação e, ao mesmo tempo, garante o desempenho do modelo. Esta tecnologia inovadora traz novas possibilidades para a aplicação de grandes modelos de linguagem.
A equipe de pesquisa introduziu recentemente um novo método interessante chamado T-FREE, que permite que a eficiência operacional de grandes modelos de linguagem dispare. Cientistas de Aleph Alpha, TU Darmstadt, hessian.AI e o Centro Alemão de Pesquisa para Inteligência Artificial (DFKI) lançaram em conjunto esta tecnologia incrível, cujo nome completo é "Representação esparsa sem tags, a incorporação com eficiência de memória é possível".
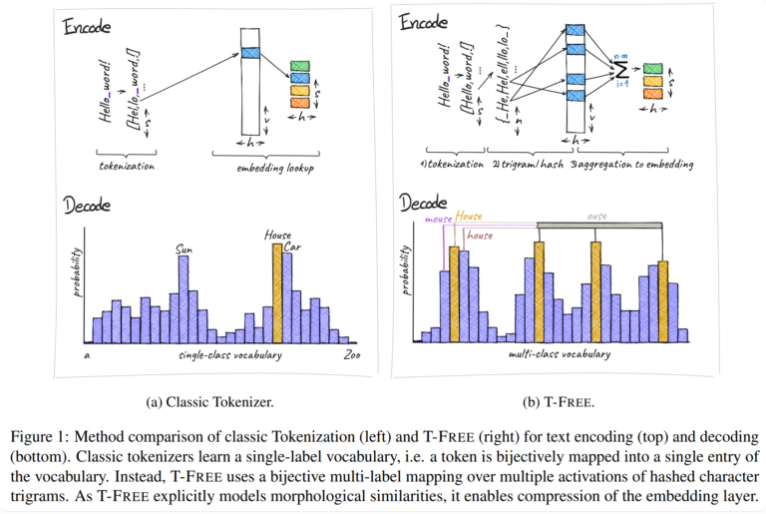
Tradicionalmente, usamos tokenizadores para converter texto em uma forma numérica que os computadores possam entender, mas a T-FREE escolheu um caminho diferente. Ele usa triplos de caracteres, o que chamamos de "triplos", para incorporar palavras diretamente no modelo por meio de ativação esparsa. Como resultado deste movimento inovador, o número de parâmetros na camada de incorporação foi reduzido em surpreendentes 85% ou mais, enquanto o desempenho do modelo não foi afetado de forma alguma ao lidar com tarefas como classificação de texto e resposta a perguntas.
Outro destaque do T-FREE é que ele modela semelhanças morfológicas entre palavras de maneira muito inteligente. Assim como as palavras “casa”, “casas” e “doméstica” que frequentemente encontramos na vida cotidiana, o T-FREE pode representar de forma mais eficaz essas palavras semelhantes no modelo. Os pesquisadores acreditam que palavras semelhantes devem ser incorporadas mais próximas umas das outras para atingir taxas de compressão mais altas. Portanto, o T-FREE não apenas reduz o tamanho da camada de incorporação, mas também reduz o comprimento médio de codificação do texto em 56%.
O que vale mais a pena mencionar é que o T-FREE tem um desempenho particularmente bom na transferência de aprendizagem entre diferentes idiomas. Numa experiência, os investigadores utilizaram um modelo com 3 mil milhões de parâmetros, treinados primeiro em inglês e depois em alemão, e descobriram que o T-FREE era muito mais adaptável do que os métodos tradicionais baseados em tagger.
No entanto, os pesquisadores permanecem modestos quanto aos seus resultados atuais. Eles admitem que as experiências até agora foram limitadas a modelos com até 3 mil milhões de parâmetros, e que estão planeadas futuras avaliações em modelos maiores e conjuntos de dados maiores.
O surgimento do método T-FREE fornece novas ideias para melhorar a eficiência de grandes modelos de linguagem. Suas vantagens na redução de custos computacionais e na melhoria do desempenho do modelo são dignas de atenção. As futuras direções de pesquisa se concentrarão na verificação de modelos e conjuntos de dados em larga escala para expandir ainda mais o escopo de aplicação do T-FREE e promover o desenvolvimento contínuo de tecnologia de modelos de linguagem em larga escala. Acredita-se que o T-FREE desempenhará um papel importante em mais campos num futuro próximo.