Jina AI lançou o Reader-LM, um modelo de linguagem leve projetado especificamente para converter HTML em Markdown limpo. Ele pode remover com eficiência conteúdo desordenado de páginas da web, como anúncios e scripts, para gerar arquivos Markdown claramente estruturados, sem expressões regulares complexas ou operações manuais. O Reader-LM está disponível em duas versões: Reader-LM-0.5B e Reader-LM-1.5B, ambos otimizados para funcionar com eficiência mesmo em ambientes com recursos limitados e suportar contextos de até 256 mil tokens.
Jina AI lançou dois pequenos modelos de linguagem projetados especificamente para converter conteúdo HTML original em formato Markdown limpo e organizado, permitindo-nos livrar-nos do tedioso processamento de dados de páginas da web.
O maior destaque deste modelo denominado Reader-LM é que ele pode converter conteúdo da web em arquivos Markdown de forma rápida e eficiente.
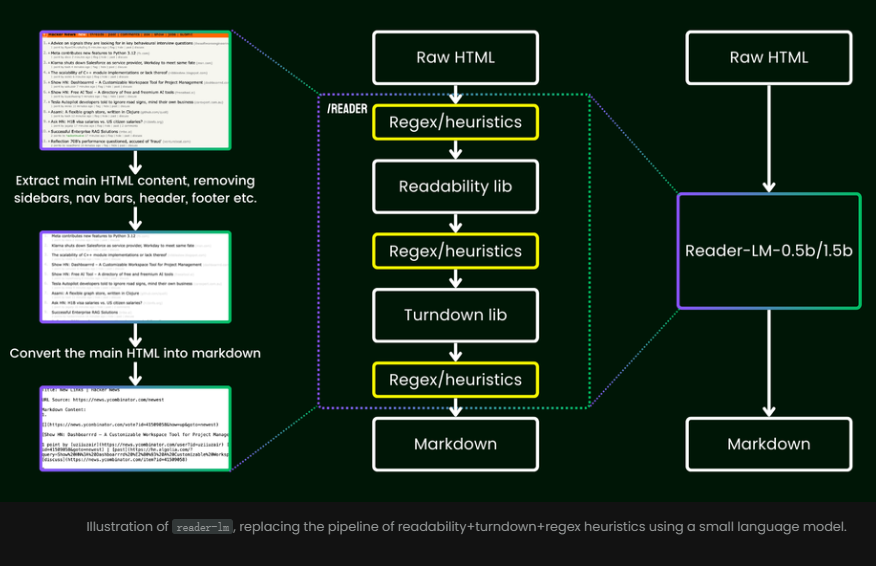
A vantagem de usá-lo é que você não precisa mais depender de regras complexas ou de expressões regulares trabalhosas. Esses modelos removem de forma inteligente e automática conteúdo desordenado de páginas da web, como anúncios, scripts e barras de navegação, e finalmente apresentam um formato Markdown claro e organizado.
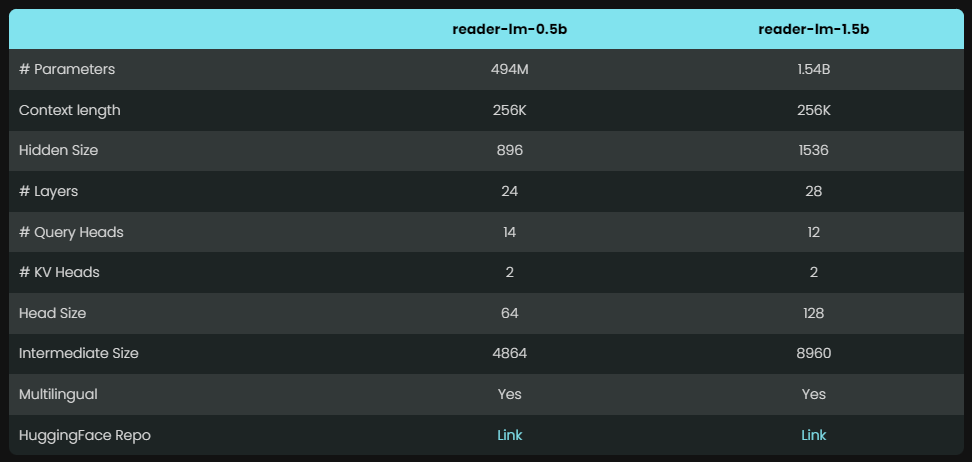
O Reader-LM oferece dois modelos com parâmetros diferentes, nomeadamente Reader-LM-0.5B e Reader-LM-1.5B. Embora o número de parâmetros desses dois modelos não seja enorme, eles são otimizados para a tarefa de conversão de HTML em Markdown. Os resultados são surpreendentes e seu desempenho supera muitos modelos de linguagem grandes.
Graças ao seu design compacto, estes modelos podem operar de forma eficiente em ambientes com recursos limitados. O que é ainda mais louvável é que o Reader-LM não apenas suporta vários idiomas, mas também pode lidar com dados de contexto de até 256 mil tokens, tornando possível lidar com arquivos HTML complexos com facilidade.
Ao contrário dos métodos tradicionais que dependem de expressões regulares ou configurações manuais, o Reader-LM fornece uma solução ponta a ponta que limpa automaticamente os dados HTML e extrai informações importantes.
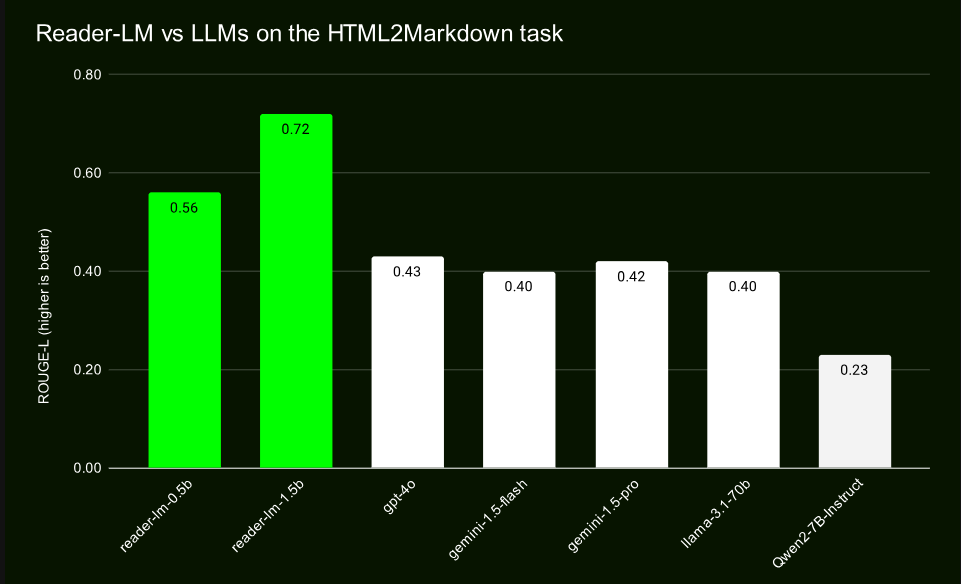
Através de testes comparativos com modelos de grande escala como GPT-4 e Gemini, o Reader-LM demonstrou excelente desempenho, especialmente em termos de preservação de estrutura e uso da sintaxe Markdown. O Reader-LM-1.5B tem um desempenho particularmente bom em vários indicadores, com uma pontuação ROUGE-L de 0,72, mostrando sua alta precisão na geração de conteúdo, e sua taxa de erro também é significativamente menor do que produtos similares.
Devido ao design compacto do Reader-LM, ele é mais leve em termos de uso de recursos de hardware, especialmente o modelo 0,5B, que pode funcionar perfeitamente em ambientes de baixa configuração como o Google Colab. Apesar de seu tamanho pequeno, o Reader-LM ainda possui poderosos recursos de processamento de contexto longo e pode processar com eficiência conteúdo da Web grande e complexo sem afetar o desempenho.
Em termos de treinamento, o Reader-LM adota um processo de vários estágios e se concentra na extração de conteúdo Markdown de HTML original e barulhento.
O processo de treinamento inclui o emparelhamento de um grande número de páginas web reais e dados sintéticos, garantindo a eficiência e precisão do modelo. Após um treinamento cuidadosamente projetado em duas etapas, o Reader-LM melhorou gradualmente sua capacidade de processar arquivos HTML complexos e evitou efetivamente o problema de geração repetida.
Introdução oficial: https://jina.ai/news/reader-lm-small-language-models-for-cleaning-and-converting-html-to-markdown/
Resumindo, o Reader-LM fornece uma solução eficiente, conveniente e precisa para conversão de HTML em Markdown. Seu design leve facilita a execução em vários ambientes, tornando-o uma escolha ideal para o processamento de dados de páginas da web. Para mais informações, visite o link de introdução oficial.