A Kunlun Technology anunciou recentemente que dois modelos de recompensa que desenvolveu, Skywork-Reward-Gemma-2-27B e Skywork-Reward-Llama-3.1-8B, alcançaram excelentes resultados no RewardBench, com o modelo 27B no topo da lista. Isto marca que Kunlun Wanwei fez um grande avanço no campo da inteligência artificial, especialmente na pesquisa e desenvolvimento de modelos de recompensa, e fornece novo suporte técnico para o treinamento de grandes modelos de linguagem. Os modelos de recompensa são cruciais na aprendizagem por reforço, pois podem orientar a aprendizagem do modelo e gerar conteúdo mais alinhado com as preferências humanas. O modelo de Kunlun Wanwei tem vantagens únicas na seleção de dados e no treinamento do modelo, o que o torna um bom desempenho em aspectos como diálogo e segurança e, especialmente, mostra fortes capacidades no processamento de amostras difíceis.
anunciou recentemente que dois novos modelos de recompensa desenvolvidos pela empresa, Skywork-Reward-Gemma-2-27B e Skywork-Reward-Llama-3.1-8B, tiveram bom desempenho no RewardBench, o modelo de recompensa com autoridade internacional benchmark de avaliação Entre eles, o modelo Skywork-Reward-Gemma-2-27B conquistou o primeiro lugar e foi altamente reconhecido pelos funcionários do RewardBench.
O modelo de recompensa ocupa uma posição central na aprendizagem por reforço, avaliando o desempenho do agente em diferentes estados e fornecendo sinais de recompensa para orientar o processo de aprendizagem do agente, para que ele possa fazer a escolha ideal em um ambiente específico. No treinamento de grandes modelos de linguagem, o modelo de recompensa desempenha um papel particularmente crítico, ajudando o modelo a compreender e gerar com mais precisão conteúdo que esteja em conformidade com as preferências humanas.
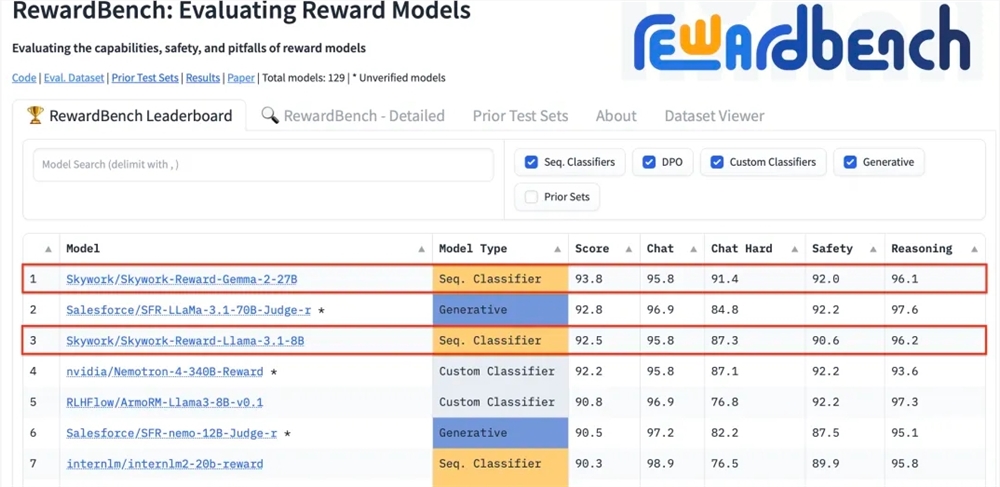
RewardBench é uma lista de benchmarks que avalia especificamente a eficácia de modelos de recompensa em grandes modelos de linguagem. Ela avalia modelos de forma abrangente por meio de múltiplas tarefas, incluindo diálogo, raciocínio e segurança. O conjunto de dados de teste desta lista consiste em triplos que consistem em palavras de prompt, respostas selecionadas e respostas rejeitadas. Ele é usado para testar se o modelo de recompensa pode classificar corretamente as respostas selecionadas entre as respostas rejeitadas, dadas as palavras de prompt. .
O modelo Skywork-Reward de Kunlun Wanwei é desenvolvido por meio de conjuntos de dados parcialmente ordenados cuidadosamente selecionados e modelos de base relativamente pequenos. Em comparação com os modelos de recompensa existentes, seus dados parcialmente ordenados vêm apenas de dados públicos na Internet e são filtrados por meio de filtros específicos para obter alta. conjuntos de dados de preferência de qualidade. Os dados abrangem uma ampla variedade de tópicos, incluindo segurança, matemática e código, e são verificados manualmente para garantir a objetividade dos dados e a importância das lacunas de recompensa.
Após o teste, o modelo de recompensa de Kunlun Wanwei mostrou excelente desempenho em áreas como diálogo e segurança. Especialmente ao enfrentar amostras difíceis, apenas o modelo Skywork-Reward-Gemma-2-27B deu previsões corretas. Esta conquista marca a força técnica e as capacidades de inovação de Kunlun Wanwei no campo global de IA e também oferece novas possibilidades para o desenvolvimento e aplicação da tecnologia de IA.
Endereço do modelo 27B:
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
Endereço do modelo 8B:
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
O excelente desempenho de Kunlun Wanwei no RewardBench demonstra suas capacidades tecnológicas e de inovação líderes no campo da inteligência artificial. Também fornece novas direções e possibilidades para o desenvolvimento futuro de grandes modelos de linguagem.