A pesquisa da equipe Mamba fez um grande avanço. Eles "destilaram" com sucesso o grande modelo Transformer Llama em um modelo Mamba mais eficiente. Esta pesquisa combina habilmente tecnologias como destilação progressiva, ajuste fino supervisionado e otimização de preferência direcional, e projeta um novo algoritmo de decodificação de inferência baseado na estrutura única do modelo Mamba, que melhora significativamente a velocidade de inferência do modelo sem garantir uma melhoria substancial. em eficiência foi alcançada sem perdas. Esta pesquisa não apenas reduz o custo do treinamento de modelos em larga escala, mas também fornece novas ideias para otimização futura de modelos, que têm importante significado acadêmico e valor de aplicação.
Recentemente, a pesquisa da equipe do Mamba é atraente: pesquisadores de universidades como Cornell e Princeton "destilaram" com sucesso o Llama, um grande modelo do Transformer, no Mamba e projetaram um novo algoritmo de decodificação de inferência que melhorou significativamente a velocidade de inferência do modelo.
O objetivo dos pesquisadores é transformar Llama em Mamba. Por que fazer isso? Porque treinar um modelo grande a partir do zero é caro e o Mamba recebeu ampla atenção desde o seu início, mas poucas equipes realmente treinam eles próprios modelos Mamba em grande escala. Embora existam algumas variantes respeitáveis no mercado, como o Jamba da AI21 e o Hybrid Mamba2 da NVIDIA, há uma riqueza de conhecimento incorporado nos muitos modelos de Transformer de sucesso. Se pudéssemos consolidar esse conhecimento e ajustar o Transformer para o Mamba, o problema estaria resolvido.
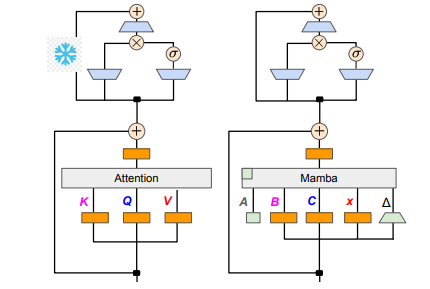
A equipe de pesquisa alcançou esse objetivo com sucesso combinando vários métodos, como destilação progressiva, ajuste fino supervisionado e otimização de preferência direcional. Vale ressaltar que a velocidade também é crucial sem comprometer o desempenho. O Mamba tem vantagens óbvias no raciocínio de sequência longa, e o Transformer também possui soluções de aceleração de raciocínio, como decodificação especulativa. Como a estrutura única do Mamba não pode aplicar diretamente essas soluções, os pesquisadores projetaram especialmente um novo algoritmo e combinaram-no com recursos de hardware para implementar a decodificação especulativa baseada no Mamba.
Finalmente, os pesquisadores converteram com sucesso Zephyr-7B e Llama-38B em modelos RNN lineares, e seu desempenho foi comparável ao modelo padrão antes da destilação. Todo o processo de treinamento usa apenas tokens de 20B e os resultados são comparáveis ao modelo Mamba7B treinado do zero usando tokens de 1,2T e ao modelo NVIDIA Hybrid Mamba2 treinado com tokens de 3,5T.
Em termos de detalhes técnicos, o RNN linear e a atenção linear estão conectados, para que os pesquisadores possam reutilizar diretamente a matriz de projeção no mecanismo de atenção e completar a construção do modelo por meio da inicialização dos parâmetros. Além disso, a equipe de pesquisa congelou os parâmetros da camada MLP no Transformer, substituiu gradualmente a cabeça de atenção por uma camada RNN linear (ou seja, Mamba) e processou a atenção de consulta de grupo para chaves e valores compartilhados entre cabeças.
Durante o processo de destilação, é adotada uma estratégia de substituição gradual das camadas de atenção. O ajuste fino supervisionado inclui dois métodos principais: um é baseado na divergência KL em nível de palavra e o outro é a destilação de conhecimento em nível de sequência. Na fase de ajuste das preferências do usuário, a equipe utilizou o método Direct Preference Optimization (DPO) para garantir que o modelo pudesse atender melhor às expectativas do usuário ao gerar conteúdo, comparando-o com o resultado do modelo do professor.
Em seguida, os pesquisadores começaram a aplicar a decodificação especulativa do Transformer ao modelo Mamba. A decodificação especulativa pode ser simplesmente entendida como o uso de um modelo pequeno para gerar múltiplas saídas e, em seguida, o uso de um modelo grande para verificar essas saídas. Modelos pequenos são executados rapidamente e podem gerar vários vetores de saída rapidamente, enquanto modelos grandes são responsáveis por avaliar a precisão dessas saídas, aumentando assim a velocidade geral de inferência.
Para implementar esse processo, os pesquisadores projetaram um conjunto de algoritmos que usam um modelo pequeno para gerar K saídas de rascunho a cada vez e, em seguida, o modelo grande retorna a saída final e o cache de estados intermediários por meio de verificação. Este método alcançou bons resultados na GPU Mamba2.8B, atingindo 1,5 vezes de aceleração de inferência e a taxa de aceitação atingiu 60%. Embora os efeitos variem em GPUs de diferentes arquiteturas, a equipe de pesquisa otimizou ainda mais integrando kernels e ajustando métodos de implementação e, finalmente, alcançou o efeito de aceleração ideal.
Na fase experimental, os pesquisadores usaram Zephyr-7B e Llama-3Instruct8B para realizar o treinamento de destilação em três estágios. No final, levou apenas 3 a 4 dias para executar um 80G A100 de 8 placas para reproduzir com sucesso os resultados da pesquisa. Esta pesquisa não apenas mostra a transformação entre Mamba e Llama, mas também fornece novas ideias para melhorar a velocidade de inferência e o desempenho de modelos futuros.
Endereço do artigo: https://arxiv.org/pdf/2408.15237
Esta pesquisa fornece experiência valiosa e soluções técnicas para melhorar a eficiência de modelos de linguagem em grande escala. Espera-se que os resultados sejam aplicados a mais campos e promovam o desenvolvimento da tecnologia de inteligência artificial. O fornecimento do endereço do artigo facilita aos leitores uma compreensão mais profunda dos detalhes da pesquisa.