O Google DeepMind se uniu a várias universidades para desenvolver um novo método chamado Generative Reward Model (GenRM), que visa resolver o problema de precisão e confiabilidade insuficientes da IA generativa em tarefas de raciocínio. Embora os modelos de IA generativos existentes sejam amplamente utilizados em campos como o processamento de linguagem natural, eles muitas vezes produzem informações erradas com segurança, especialmente em campos que exigem precisão extremamente alta, o que limita o escopo de sua aplicação. A inovação do GenRM é redefinir o processo de verificação como uma tarefa de previsão da próxima palavra, integrar os recursos de geração de texto de grandes modelos de linguagem (LLMs) no processo de verificação e apoiar o raciocínio em cadeia, alcançando assim uma verificação mais abrangente e sistemática.
Recentemente, a equipe de pesquisa do Google DeepMind se uniu a várias universidades para propor um novo método chamado Modelo de Recompensa Generativa (GenRM), que visa melhorar a precisão e a confiabilidade da IA generativa em tarefas de raciocínio.
A IA generativa é amplamente utilizada em muitos campos, como processamento de linguagem natural. Ela gera principalmente texto coerente prevendo a próxima palavra de uma série de palavras. No entanto, estes modelos por vezes produzem informações incorretas com segurança, o que é um grande problema, especialmente em áreas onde a precisão é crítica, como educação, finanças e saúde.
Atualmente, os pesquisadores têm tentado diferentes soluções para as dificuldades encontradas pelos modelos generativos de IA na precisão dos resultados. Entre eles, modelos de recompensa discriminativos (RMs) são usados para determinar se as respostas potenciais estão corretas com base nas pontuações, mas este método não utiliza plenamente as capacidades generativas dos grandes modelos de linguagem (LLMs). Outro método comumente usado é o "LLM como juiz", mas muitas vezes esse método não é tão eficaz quanto um verificador profissional ao resolver tarefas complexas de raciocínio.
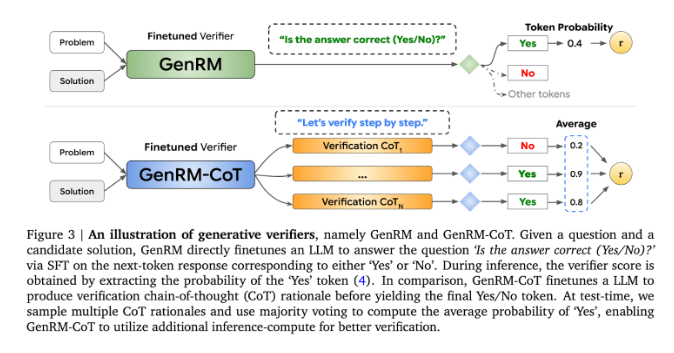
A inovação do GenRM é redefinir o processo de verificação como uma tarefa de previsão da próxima palavra. Isto significa que, ao contrário dos modelos tradicionais de recompensa discriminativa, o GenRM incorpora as capacidades de geração de texto dos LLMs no processo de verificação, permitindo que o modelo gere e avalie simultaneamente soluções potenciais. Além disso, o GenRM também suporta o raciocínio encadeado (CoT), ou seja, o modelo pode gerar etapas intermediárias de raciocínio antes de chegar à conclusão final, tornando o processo de verificação mais abrangente e sistemático.
Ao combinar geração e validação, a abordagem GenRM adota uma estratégia de treinamento unificada que permite ao modelo melhorar simultaneamente as capacidades de geração e validação durante o treinamento. Em aplicações reais, o modelo gera etapas intermediárias de inferência que são utilizadas para verificar a resposta final.
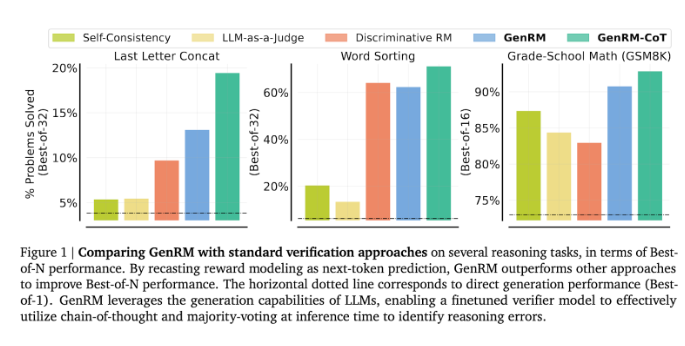
Os pesquisadores descobriram que o modelo GenRM teve um bom desempenho em vários testes rigorosos, como uma precisão significativamente melhorada em matemática pré-escolar e tarefas algorítmicas de resolução de problemas. Em comparação com o modelo de recompensa discriminativo e o LLM como método de juiz, a taxa de sucesso na resolução de problemas do GenRM aumentou de 16% para 64%.
Por exemplo, ao verificar o resultado do modelo Gemini1.0Pro, o GenRM aumentou a taxa de sucesso na resolução de problemas de 73% para 92,8%.
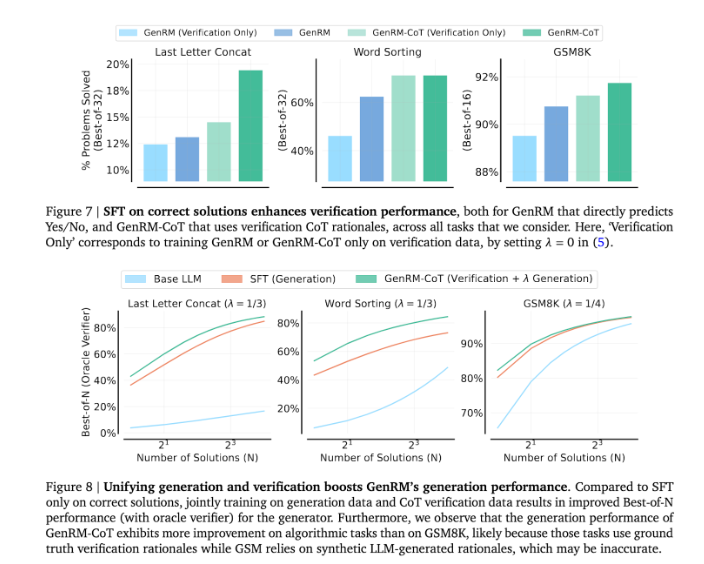
A introdução do método GenRM marca um grande avanço no campo da IA generativa, melhorando significativamente a precisão e a confiabilidade das soluções geradas por IA, unificando a geração e verificação de soluções em um único processo.
Em suma, o surgimento do GenRM fornece novas ideias para melhorar a fiabilidade da IA generativa. A sua melhoria significativa na resolução de problemas de raciocínio complexos indica a possibilidade de a IA generativa ser aplicada em mais campos, o que merece mais investigação e exploração.