Os otimizadores de consulta de banco de dados dependem fortemente da estimativa de cardinalidade (CE) para prever os tamanhos dos resultados da consulta e, assim, selecionar o melhor plano de execução. Estimativas imprecisas de cardinalidade podem causar degradação no desempenho da consulta. Os métodos CE existentes têm limitações, especialmente quando lidam com consultas complexas. Embora o modelo de CE de aprendizagem seja mais preciso, o seu custo de formação é elevado e carece de avaliação sistemática de benchmark.
Nos bancos de dados relacionais modernos, a estimativa de cardinalidade (CE) desempenha um papel crucial. Simplificando, a estimativa de cardinalidade é uma previsão de quantos resultados intermediários uma consulta ao banco de dados retornará. Essa previsão tem um enorme impacto nas escolhas do plano de execução do otimizador de consulta, como decidir a ordem de junção, usar índices e escolher o melhor método de junção. Se a estimativa de cardinalidade for imprecisa, o plano de execução poderá ficar bastante comprometido, resultando em velocidades de consulta extremamente lentas e afetando seriamente o desempenho geral do banco de dados.
No entanto, os métodos existentes de estimativa de cardinalidade têm muitas limitações. A tecnologia CE tradicional depende de algumas suposições simplificadoras e muitas vezes prevê com precisão a cardinalidade de consultas complexas, especialmente quando múltiplas tabelas e condições estão envolvidas. Embora o aprendizado de modelos de CE possa fornecer melhor precisão, sua aplicação é limitada por longos tempos de treinamento, pela necessidade de grandes conjuntos de dados e pela falta de avaliação sistemática de benchmark.
Para preencher esta lacuna, a equipe de pesquisa do Google lançou o CardBench, uma nova estrutura de benchmarking. O CardBench inclui mais de 20 bancos de dados reais e milhares de consultas, superando em muito os benchmarks anteriores. Isso permite que os pesquisadores avaliem e comparem sistematicamente diferentes modelos de CE de aprendizagem sob várias condições. O benchmark suporta três configurações principais: modelos baseados em instâncias, modelos zero-shot e modelos ajustados, adequados para diferentes necessidades de treinamento.
O CardBench também foi projetado para incluir um conjunto de ferramentas que podem calcular estatísticas necessárias, gerar consultas SQL reais e criar gráficos de consulta anotados para treinar modelos CE.
O benchmark fornece dois conjuntos de dados de treinamento: um para uma consulta de tabela única com vários predicados de filtro e outro para uma consulta de junção binária envolvendo duas tabelas. O benchmark inclui 9.125 consultas de tabela única e 8.454 consultas de junção binária em um dos conjuntos de dados menores, garantindo um ambiente robusto e desafiador para avaliação de modelo. O treinamento de rótulos de dados do Google BigQuery exigiu 7 anos de CPU de tempo de execução de consulta, destacando o investimento computacional significativo na criação deste benchmark. Ao fornecer esses conjuntos de dados e ferramentas, o CardBench reduz a barreira para os pesquisadores desenvolverem e testarem novos modelos de CE.
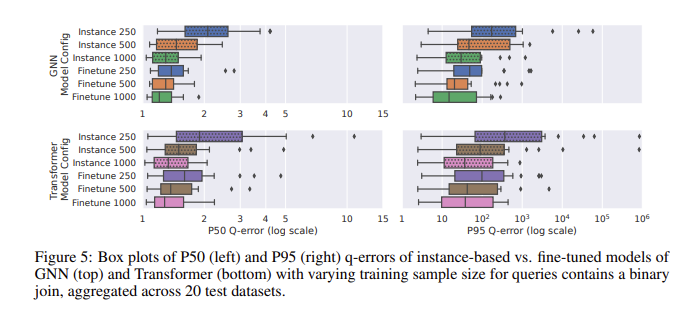
Na avaliação de desempenho usando o CardBench, o modelo ajustado teve um desempenho particularmente bom. Embora os modelos zero-shot tenham dificuldade em melhorar a precisão quando aplicados a conjuntos de dados invisíveis, especialmente em consultas complexas que envolvem junções, os modelos ajustados podem alcançar uma precisão comparável aos métodos baseados em instâncias com muito menos dados de treinamento. Por exemplo, um modelo de rede neural gráfica ajustada (GNN) alcançou um erro q mediano de 1,32 e um erro q do 95º percentil de 120 em consultas de junção binária, significativamente melhor do que o modelo zero-shot. Os resultados mostram que mesmo com 500 consultas, o ajuste fino do modelo pré-treinado pode melhorar significativamente o seu desempenho. Isto os torna adequados para aplicações práticas onde os dados de treinamento podem ser limitados.
A introdução do CardBench traz uma nova esperança ao campo da estimativa de cardinalidade aprendida, permitindo aos pesquisadores avaliar e melhorar os modelos de forma mais eficaz, impulsionando assim um maior desenvolvimento neste importante campo.
Entrada de papel: https://arxiv.org/abs/2408.16170
Resumindo, o CardBench fornece uma estrutura de benchmarking abrangente e poderosa, fornece ferramentas e recursos importantes para a pesquisa e desenvolvimento de modelos de aprendizagem de estimativa de cardinalidade e promove o avanço da tecnologia de otimização de consultas de banco de dados. O excelente desempenho do seu modelo afinado é particularmente digno de atenção, proporcionando novas possibilidades para cenários práticos de aplicação.