Alibaba Damo Academy lançou uma grande atualização para seu modelo de linguagem multimodal em grande escala Qwen2-VL em 30 de agosto de 2024. Esta atualização traz avanços significativos na compreensão de imagens, processamento de vídeo e suporte multilíngue e estabelece novos padrões de desempenho. O modelo Qwen2-VL não apenas melhora a compreensão da informação visual, mas também possui recursos avançados de compreensão de vídeo e funções integradas do agente de visualização, permitindo-lhe realizar raciocínios e tomadas de decisão mais complexos. Além disso, o suporte expandido a vários idiomas facilita o uso global.
O modelo Qwen2-VL alcançou melhorias significativas na compreensão de imagens, processamento de vídeo e suporte multilíngue, estabelecendo uma nova referência para indicadores-chave de desempenho. Os novos recursos do modelo Qwen2-VL incluem recursos aprimorados de compreensão de imagem que permitem compreensão e interpretação mais precisas de informações visuais avançadas que permitem ao modelo analisar conteúdo de vídeo dinâmico em tempo real e recursos integrados de agente de visualização que transformam o modelo; em um agente poderoso para raciocínio e tomada de decisão complexos e suporte multilíngue expandido, tornando-o mais acessível e eficaz em ambientes de diferentes idiomas;
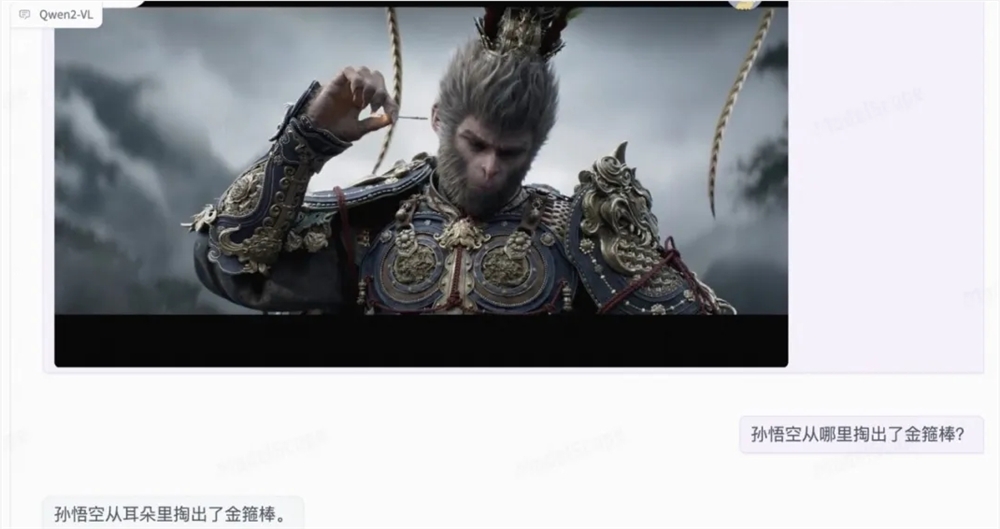
Em termos de arquitetura técnica, Qwen2-VL implementa suporte de resolução dinâmica e pode processar imagens de qualquer resolução sem dividi-las em blocos, garantindo assim consistência entre a entrada do modelo e as informações inerentes da imagem. Além disso, a inovação do Multimodal Rotary Position Embedding (M-ROPE) permite que o modelo capture e integre simultaneamente texto 1D, visão 2D e informações de posição de vídeo 3D.
O modelo Qwen2-VL-7B mantém com sucesso o suporte para entradas de imagem, multiimagem e vídeo em escala 7B e tem um bom desempenho em tarefas de compreensão de documentos e compreensão de texto multilíngue baseada em imagem.
Ao mesmo tempo, a equipe também lançou um modelo 2B otimizado para implantação móvel. Embora o número de parâmetros seja de apenas 2B, ele tem um bom desempenho em imagem, vídeo e compreensão multilíngue.
Link do modelo:
Qwen2-VL-2B-Instrução: https://www.modelscope.cn/models/qwen/Qwen2-VL-2B-Instruct
Qwen2-VL-7B-Instrução: https://www.modelscope.cn/models/qwen/Qwen2-VL-7B-Instruct
A atualização do modelo Qwen2-VL marca um novo avanço na tecnologia de modelos de linguagem multimodais em grande escala. Seus poderosos recursos de processamento de imagem, vídeo e multilíngue oferecem amplas perspectivas para aplicações futuras. O lançamento de duas versões, 7B e 2B, também oferece opções mais flexíveis para diferentes cenários de aplicação.