Recentemente, MLCommons divulgou os resultados da inferência MLPerf v4.1. Vários fabricantes de chips de inferência de IA participaram e a competição foi acirrada. Pela primeira vez, esta competição inclui chips da AMD, Google, UntetherAI e outros fabricantes, bem como os mais recentes chips Blackwell da Nvidia. Além da comparação de desempenho, a eficiência energética também se tornou uma importante dimensão competitiva. Vários fabricantes mostraram suas habilidades especiais e demonstraram suas respectivas vantagens em diferentes testes de benchmark, trazendo uma nova vitalidade ao mercado de chips de inferência de IA.
No campo do treinamento em inteligência artificial, as placas gráficas da Nvidia são quase incomparáveis, mas quando se trata de inferência de IA, os concorrentes parecem estar começando a alcançá-los, especialmente em termos de eficiência energética. Apesar do forte desempenho dos mais recentes chips Blackwell da Nvidia, não está claro se ela conseguirá manter a liderança. Hoje, o ML Commons anunciou os resultados da última competição de inferência de IA - MLPerf Inference v4.1. Pela primeira vez, o acelerador Instinct da AMD, o acelerador Trillium do Google, os chips da startup canadense UntetherAI e os chips Blackwell da Nvidia estão participando. Duas outras empresas, Cerebras e FuriosaAI, lançaram novos chips de inferência, mas não submeteram o MLPerf para teste.
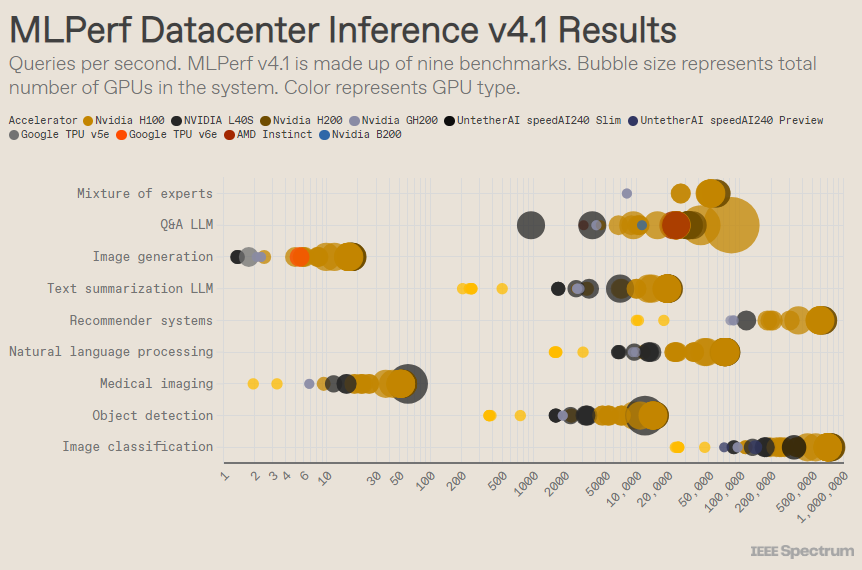
O MLPerf está estruturado como uma competição olímpica, com múltiplos eventos e subeventos. A categoria “Data Center Enclosure” teve o maior número de inscrições. Ao contrário da categoria aberta, a categoria fechada exige que os participantes realizem inferências diretamente sobre um determinado modelo, sem modificar significativamente o software. A categoria data center testa principalmente a capacidade de processar solicitações em lote, enquanto a categoria edge se concentra na redução da latência.
Existem 9 benchmarks diferentes em cada categoria, cobrindo uma variedade de tarefas de IA, incluindo geração de imagens populares (pense em Midjourney) e resposta a perguntas com grandes modelos de linguagem (como ChatGPT), bem como algumas tarefas importantes, mas menos conhecidas, como classificação de imagens, detecção de objetos e mecanismos de recomendação.
Esta rodada adiciona um novo benchmark – o “modelo híbrido especializado”. Este é um método cada vez mais popular de implantação de modelo de linguagem que divide um modelo de linguagem em vários pequenos modelos independentes, cada um ajustado para uma tarefa específica, como conversa diária, resolução de problemas matemáticos ou assistência de programação. Ao atribuir cada consulta ao seu pequeno modelo correspondente, a utilização de recursos é reduzida, reduzindo custos e aumentando o rendimento, disse Miroslav Hodak, membro sênior da equipe técnica da AMD.

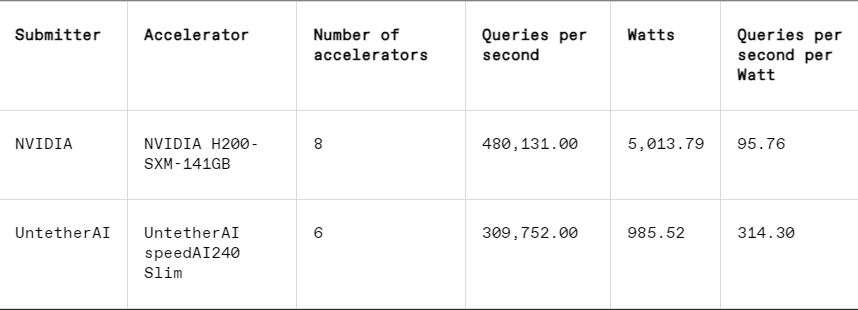
No popular benchmark de “data center fechado”, os vencedores ainda são os envios baseados na GPU Nvidia H200 e no superchip GH200, que combinam GPU e CPU em um único pacote. No entanto, uma análise mais detalhada dos resultados revela alguns detalhes interessantes. Alguns concorrentes usaram vários aceleradores, enquanto outros usaram apenas um. Os resultados serão ainda mais confusos se normalizarmos as consultas por segundo pelo número de aceleradores e retermos os envios de melhor desempenho para cada tipo de acelerador. Deve-se notar que esta abordagem ignora o papel da CPU e da interconexão.
Por acelerador, o Blackwell da Nvidia se destacou em tarefas de perguntas e respostas de modelos de linguagem grande, proporcionando uma aceleração de 2,5x em relação às iterações de chips anteriores, o único benchmark ao qual foi submetido. O chip de visualização speedAI240 do Untether AI teve um desempenho quase tão bom quanto o H200 na única tarefa de reconhecimento de imagem à qual foi submetido. O Trillium do Google tem desempenho ligeiramente inferior ao H100 e H200 em tarefas de geração de imagens, enquanto o Instinct da AMD tem desempenho equivalente ao H100 em tarefas de perguntas e respostas de modelos de linguagem grande.
Parte do sucesso da Blackwell decorre de sua capacidade de executar grandes modelos de linguagem usando precisão de ponto flutuante de 4 bits. A Nvidia e os concorrentes têm trabalhado para reduzir o número de bits representados em modelos de transformação como o ChatGPT para acelerar os cálculos. A Nvidia introduziu matemática de 8 bits no H100, e esta apresentação é a primeira demonstração de matemática de 4 bits no benchmark MLPerf.
O maior desafio de trabalhar com números de baixa precisão é manter a precisão, disse Dave Salvator, diretor de marketing de produtos da Nvidia. Para manter a alta precisão nos envios do MLPerf, a equipe da Nvidia fez inúmeras inovações no software.
Além disso, a largura de banda da memória da Blackwell quase dobra para 8 terabytes por segundo, em comparação com os 4,8 terabytes do H200.
O envio da Blackwell da Nvidia usa um único chip, mas Salvator diz que ele foi projetado para rede e escalonamento e terá melhor desempenho quando combinado com a interconexão NVLink da Nvidia. As GPUs Blackwell suportam até 18 conexões NVLink de 100 GB por segundo, com uma largura de banda total de 1,8 terabytes por segundo, quase o dobro da largura de banda de interconexão do H100.
Salvator acredita que à medida que os grandes modelos de linguagem continuam a crescer, até mesmo a inferência exigirá plataformas multi-GPU para atender à demanda, e a Blackwell foi projetada para esta situação. “Havel é uma plataforma”, disse Salvator.
A Nvidia enviou seu sistema de chip Blackwell para a subcategoria Preview, o que significa que ainda não está disponível, mas espera-se que esteja disponível antes do próximo lançamento do MLPerf, daqui a cerca de seis meses.
Em cada benchmark, o MLPerf também inclui uma seção de medição de energia que testa sistematicamente o consumo real de energia de cada sistema durante a execução de tarefas. A competição principal desta rodada (categoria Data Center Enclosed Energy) teve apenas dois inscritos, Nvidia e Untether AI. Enquanto a Nvidia participou de todos os benchmarks, a Untether apresentou apenas resultados na tarefa de reconhecimento de imagem.
Untether AI se destaca nesse aspecto, alcançando com sucesso excelente eficiência energética. Seu chip usa uma abordagem chamada “computação em memória”. O chip do Untether AI é composto por um banco de células de memória com um pequeno processador próximo. Cada processador funciona em paralelo, processando dados simultaneamente com unidades de memória adjacentes, reduzindo significativamente o tempo e a energia gastos na transferência de dados do modelo entre a memória e os núcleos de computação.
“Descobrimos que, ao executar cargas de trabalho de IA, 90% do consumo de energia está na movimentação de dados da DRAM para unidades de processamento de cache”, disse Robert Beachler, vice-presidente de produto da Untether AI. “Então o que o Untether faz é aproximar a computação dos dados, em vez de mover os dados para a unidade de computação.”
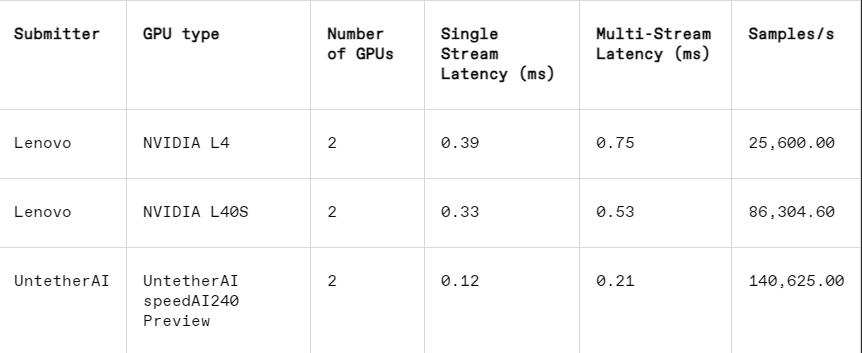
Esta abordagem funciona particularmente bem em outra subcategoria do MLPerf: fechamento de borda. Esta categoria concentra-se em casos de uso mais práticos, como inspeção de máquinas em fábricas, robôs de visão guiada e veículos autônomos – aplicações que possuem requisitos rigorosos de eficiência energética e processamento rápido, explicou Beachler.
Na tarefa de reconhecimento de imagem, o desempenho de latência do chip de visualização speedAI240 da Untether AI é 2,8 vezes mais rápido que o L40S da Nvidia, e o rendimento (número de amostras por segundo) também é aumentado em 1,6 vezes. A startup também apresentou resultados de consumo de energia nesta categoria, mas os concorrentes da Nvidia não o fizeram, dificultando comparações diretas. No entanto, o chip de visualização speedAI240 da Untether AI tem um consumo nominal de energia de 150 watts, enquanto o L40S da Nvidia tem 350 watts, mostrando uma vantagem de 2,3x no consumo de energia e melhor desempenho de latência.
Embora Cerebras e Furiosa não tenham participado do MLPerf, elas também lançaram novos chips respectivamente. A Cerebras revelou seu serviço de inferência na conferência IEEE Hot Chips na Universidade de Stanford. A Cerebras, com sede em Sunny Valley, Califórnia, fabrica chips gigantes que são tão grandes quanto os wafers de silício permitem, evitando assim interconexões entre chips e aumentando significativamente a largura de banda da memória do dispositivo. Agora, eles atualizaram seu computador mais recente, o CS3, para oferecer suporte à inferência.
Embora a Cerebras não tenha apresentado um MLPerf, a empresa afirma que sua plataforma supera o H100 em 7x e o chip concorrente Groq em 2x no número de tokens LLM gerados por segundo. “Hoje, estamos na era dial-up da IA generativa”, disse Andrew Feldman, CEO e cofundador da Cerebras. "Isso tudo ocorre porque há um gargalo na largura de banda da memória. Seja o H100 da Nvidia, o MI300 ou TPU da AMD, todos eles usam a mesma memória externa, resultando nas mesmas limitações. Quebramos essa barreira porque fazemos isso no design de nível de wafer. "
Na conferência Hot Chips, a Furiosa de Seul também demonstrou seu chip RNGD de segunda geração (pronuncia-se “rebelde”). O novo chip da Furiosa apresenta sua arquitetura Tensor Contraction Processor (TCP). Nas cargas de trabalho de IA, a função matemática básica é a multiplicação de matrizes, muitas vezes implementada em hardware como uma primitiva. No entanto, o tamanho e a forma da matriz, ou seja, o tensor mais amplo, podem variar significativamente. RNGD implementa esta multiplicação de tensores mais geral como um primitivo. “Durante a inferência, os tamanhos dos lotes variam muito, por isso é fundamental aproveitar ao máximo o paralelismo inerente e a reutilização de dados de um determinado formato de tensor”, disse June Paik, fundadora e CEO da Furiosa, na Hot Chips.
Embora a Furiosa não tenha MLPerf, eles compararam o chip RNGD com o benchmark resumido LLM do MLPerf em testes internos, e os resultados foram comparáveis aos do chip L40S da Nvidia, mas consumiram apenas 185 watts em comparação com os 320 watts do L40S. Paik disse que o desempenho melhorará com mais otimizações de software.
A IBM também anunciou o lançamento de seu novo chip Spyre, projetado para empresas gerarem cargas de trabalho de IA e deverá estar disponível no primeiro trimestre de 2025.
Claramente, o mercado de chips de inferência de IA estará movimentado no futuro próximo.
Referência: https://spectrum.ieee.org/new-inference-chips
Em suma, os resultados do MLPerf v4.1 mostram que a concorrência no mercado de chips de inferência de IA está se tornando cada vez mais acirrada. Embora a Nvidia ainda mantenha a liderança, a ascensão de fabricantes como AMD, Google e Untether AI não pode ser ignorada. No futuro, a eficiência energética tornar-se-á um factor competitivo fundamental e as novas tecnologias, como a computação in-memory, também desempenharão um papel importante. As inovações tecnológicas de vários fabricantes continuarão a promover a melhoria das capacidades de raciocínio da IA e a fornecer um forte impulso à popularização e ao desenvolvimento de aplicações de IA.