A comunidade ModelScope abriu o código-fonte de uma versão atualizada de seu modelo doméstico de geração de vídeo Sora de código aberto, CogVideoX - CogVideoX-5B, que é um modelo de geração de texto para vídeo baseado em um modelo DiT em grande escala. Comparado com o CogVideoX-2B anterior, o novo modelo melhorou significativamente a qualidade de vídeo e os efeitos visuais. CogVideoX-5B utiliza autoencoder variacional causal 3D (VAE causal 3D) e tecnologia de transformador especializada e usa 3D-RoPE como codificação de posição e mecanismo de atenção total 3D para modelagem de articulações espaço-temporais. , vídeos de maior qualidade e com mais recursos de movimento.
Comparado com o CogVideoX-2B anterior, o novo modelo melhorou significativamente a qualidade e os efeitos visuais da geração de vídeo.
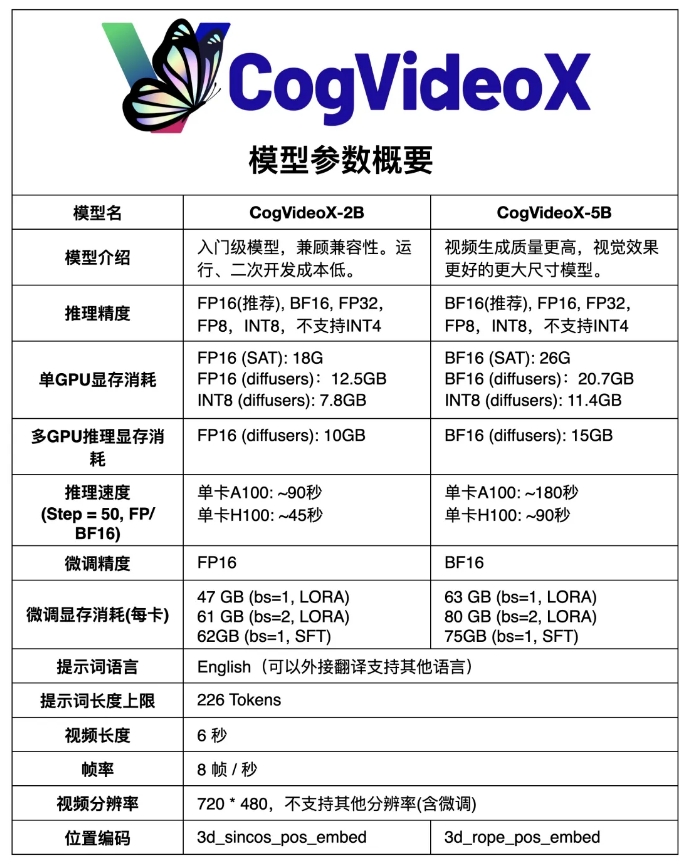
CogVideoX-5B é baseado em um modelo DiT (transformador de difusão) de grande escala, especialmente projetado para tarefas de geração de texto para vídeo. O modelo adota autoencoder variacional causal 3D (VAE causal 3D) e tecnologia Transformer especializada, combina incorporações de texto e vídeo, usa 3D-RoPE como codificação de posição e utiliza mecanismo de atenção total 3D para modelagem de articulações espaço-temporais.
Além disso, o modelo adota tecnologia de treinamento progressivo e é capaz de gerar vídeos coerentes e de longa duração de alta qualidade com recursos de movimento significativos.
Link do modelo:
https://modelscope.cn/models/ZhipuAI/CogVideoX-5b
O código aberto do CogVideoX-5B trouxe novos avanços tecnológicos e oportunidades de desenvolvimento para o campo da geração de vídeo de IA doméstica e também forneceu ferramentas e recursos poderosos para pesquisadores e desenvolvedores. Acredita-se que no futuro surgirão aplicações mais inovadoras baseadas no CogVideoX-5B, promovendo o progresso contínuo da tecnologia de geração de vídeo AI. O fácil acesso ao modelo também reduz o limiar de investigação e aplicação, promovendo uma maior divulgação e aplicação da tecnologia.