Nos últimos anos, o desempenho de grandes modelos de idiomas (LLM) atraiu muita atenção. Este artigo apresenta uma pesquisa emocionante. Esta pesquisa desafia o conceito de "modelos maiores e melhores" tradicionais, fornece novas idéias e instruções para o desenvolvimento futuro da LLM e também fornece mais possibilidades para pesquisadores e desenvolvedores com recursos limitados. Ele revela o enorme potencial das estratégias de pesquisa para melhorar os recursos de raciocínio do modelo e gatilhos, pensando sobre a relação entre os recursos de computação e os parâmetros do modelo.
Recentemente, um novo estudo tem sido emocionante e prova que os grandes modelos de idiomas (LLM) podem melhorar significativamente o desempenho através da função de pesquisa. Em particular, o modelo LLAMA3.1 com um volume de parâmetros de apenas 800 milhões passou por 100 pesquisas e não foi comparável ao GPT-4O no código Python.
Essa idéia parece lembrar as pessoas do pioneiro do aprendizado, o post clássico de Rich Sutton, "The Bitter Lição", em 2019. Ele mencionou que, com a melhoria do poder de computação, precisamos reconhecer o poder dos métodos gerais. Em particular, os dois métodos de "pesquisa" e "aprendizado" parecem ser uma excelente escolha que pode continuar a se expandir.
Embora Sutton enfatize a importância da aprendizagem, ou seja, modelos maiores podem aprender mais conhecimento, mas geralmente ignoramos o potencial da pesquisa no processo de raciocínio. Recentemente, pesquisadores de Stanford, Oxford e Deepmind descobriram que aumentar o número de tempos de amostragem repetidos durante o estágio de raciocínio podem melhorar significativamente o desempenho dos modelos nos campos da matemática, raciocínio e geração de código.
Depois de serem inspirados por esses estudos, os dois engenheiros decidiram realizar experimentos. Eles descobriram que o uso de 100 pequenos modelos de lhama para pesquisa pode superar e até amarrar o GPT-4O em tarefas de programação Python. Eles usam metáforas vívidas para descrever: "No passado, uma Malásia da Malásia poderia alcançar alguma habilidade. Agora, apenas 100 patinhos podem completar a mesma coisa".
Para obter um desempenho mais alto, eles usaram a biblioteca VLLM para realizar o raciocínio em lote e executar em 10 GPUs A100-40 GB. O autor escolheu o teste de referência do Humaneval porque pode executar o código gerado executando a avaliação de teste, que é mais objetiva e precisa.
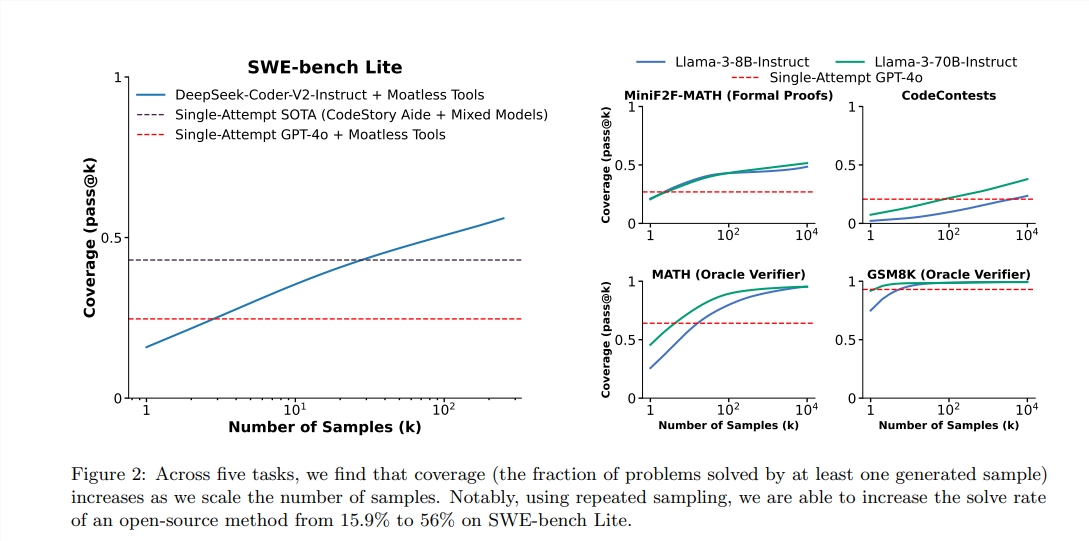
Segundo o relatório, o PASS@1 pontuação do GPT-4O é 90,2%no raciocínio zero de amostra. Através dos métodos acima, a pontuação Pass@K do LLAMA3.18B também melhorou significativamente. Quando o número de amostragem repetida é de 100, a pontuação da LLAMA atingiu 90,5%;
Vale ressaltar que, embora esse experimento não seja uma reprodução estrita da pesquisa original, enfatiza que, quando o método de pesquisa aprimora o estágio de raciocínio, o modelo menor também pode superar a possibilidade de grandes modelos dentro da faixa previsível.
A pesquisa é forte porque pode "transparentemente" expandir com o aumento dos recursos de cálculo e transferência da memória para o cálculo, alcançando assim o equilíbrio de recursos. Recentemente, o DeepMind fez um progresso importante no campo da matemática, provando o poder da pesquisa.
No entanto, o sucesso da pesquisa primeiro precisa realizar avaliação de alta qualidade dos resultados. O modelo DeepMind alcançou supervisão eficaz convertendo problemas matemáticos em linguagem natural para formar uma expressão formal. Em outras áreas, tarefas abertas de PNL, como "email de resumo", são muito mais difíceis de realizar pesquisas eficazes.
Este estudo mostra que a melhoria do desempenho da geração de modelos em campos específicos está relacionada a seus recursos de avaliação e pesquisa, e pesquisas futuras podem explorar como melhorar esses recursos por meio de um ambiente digital repetido.
Endereço da tese: https: //arxiv.org/pdf/2407.21787
Em suma, esta pesquisa fornece uma nova perspectiva para a melhoria do desempenho de grandes modelos de idiomas. No futuro, como combinar efetivamente as estratégias de aprendizado e pesquisa será uma direção importante para o desenvolvimento da LLM. O vinculado deste estudo também foi fornecido e os leitores interessados podem entendê -lo melhor.