A ascensão da arquitetura Transformer revolucionou o campo do processamento de linguagem natural, mas seu alto custo computacional tornou-se um gargalo no processamento de textos longos. Em resposta a esse problema, este artigo apresenta um novo método chamado Tree Attention, que reduz efetivamente a complexidade computacional de autoatenção do modelo Transformer de contexto longo por meio da redução de árvore e aproveita ao máximo o poder dos clusters GPU modernos A topologia de rede. melhora muito a eficiência da computação.
Nesta era de explosão de informação, a inteligência artificial é como estrelas brilhantes, iluminando o céu noturno da sabedoria humana. Entre essas estrelas, a arquitetura Transformer é sem dúvida a mais deslumbrante. Com o mecanismo de autoatenção como núcleo, lidera uma nova era de processamento de linguagem natural. No entanto, mesmo as estrelas mais brilhantes têm cantos difíceis de alcançar. Para modelos Transformer de contexto longo, o alto consumo de recursos de cálculo de autoatenção torna-se um problema. Imagine que você está tentando fazer com que a IA entenda um artigo com dezenas de milhares de palavras. Cada palavra deve ser comparada com todas as outras palavras do artigo. A quantidade de cálculo é, sem dúvida, enorme.
Para resolver este problema, um grupo de cientistas da Zyphra e EleutherAI propôs um novo método chamado Tree Attention.
Autoatenção, como núcleo do modelo Transformer, sua complexidade computacional aumenta quadraticamente à medida que o comprimento da sequência aumenta. Isto se torna um obstáculo intransponível quando se trata de textos longos, especialmente para grandes modelos de linguagem (LLMs).
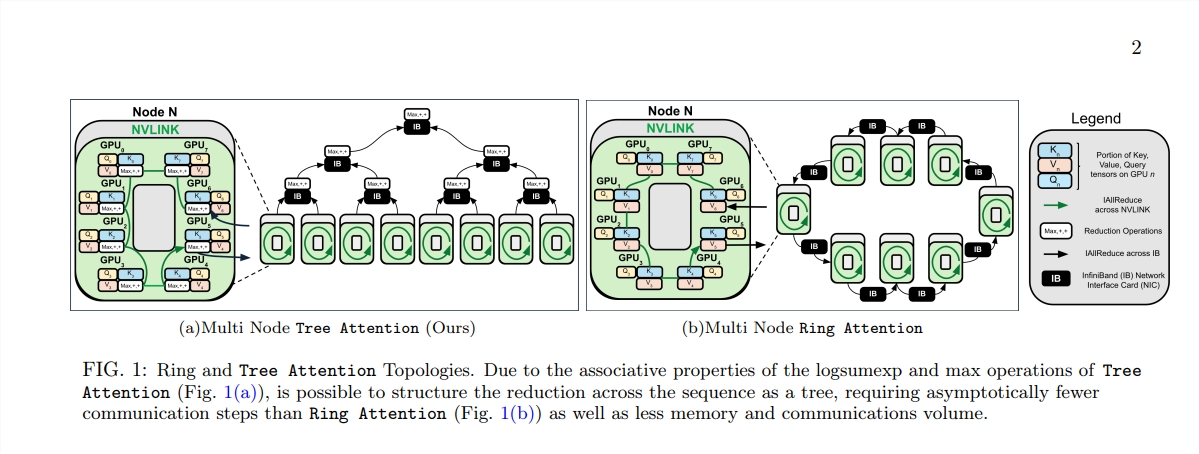
O nascimento da Tree Attention é como plantar árvores que possam realizar cálculos eficientes nesta floresta computacional. Ele decompõe o cálculo da autoatenção em múltiplas tarefas paralelas por meio da redução da árvore. Cada tarefa é como uma folha da árvore, que juntas formam uma árvore completa.
O que é ainda mais surpreendente é que os proponentes da Atenção da Árvore também derivaram a função energética da autoatenção, que não só fornece uma explicação bayesiana para a autoatenção, mas também a conecta estreitamente com modelos de energia como a rede Hopfield stand up.
A Tree Attention também leva em consideração especial a topologia de rede dos clusters de GPU modernos e reduz os requisitos de comunicação entre nós, utilizando de forma inteligente conexões de alta largura de banda dentro do cluster, melhorando assim a eficiência da computação.
Por meio de uma série de experimentos, os cientistas verificaram o desempenho do Tree Attention sob diferentes comprimentos de sequência e número de GPUs. Os resultados mostram que o Tree Attention é até 8 vezes mais rápido do que os métodos existentes de Ring Attention ao decodificar em várias GPUs, ao mesmo tempo que reduz significativamente o volume de comunicação e o pico de uso de memória.
A proposta de Tree Attention não apenas fornece uma solução eficiente para o cálculo de modelos de atenção de longo contexto, mas também fornece uma nova perspectiva para compreendermos o mecanismo interno do modelo Transformer. À medida que a tecnologia de IA continua a avançar, temos motivos para acreditar que a Atenção da Árvore desempenhará um papel importante nas futuras pesquisas e aplicações de IA.
Endereço do artigo: https://mp.weixin.qq.com/s/U9FaE6d-HJGsUs7u9EKKuQ
O surgimento do Tree Attention fornece uma solução eficiente e inovadora para resolver o gargalo computacional do processamento de textos longos. Tem um significado de longo alcance para a compreensão e desenvolvimento futuro do modelo Transformer. Este método não só alcança melhorias significativas no desempenho, mas, mais importante ainda, fornece novas ideias e orientações para pesquisas subsequentes, que merecem estudo e discussão aprofundados.