Andrej Karpathy, uma autoridade na área de IA, questionou recentemente a aprendizagem por reforço baseada em feedback humano (RLHF), acreditando que não é a única maneira de alcançar uma verdadeira IA de nível humano, o que desencadeou preocupação generalizada e discussões acaloradas na indústria . Ele acredita que o RLHF é mais uma medida provisória do que a solução definitiva, e tomou o AlphaGo como exemplo para comparar as diferenças na resolução de problemas entre a aprendizagem por reforço real e o RLHF. As opiniões de Karpathy fornecem, sem dúvida, uma nova perspectiva sobre as direções atuais da investigação em IA e também trazem novos desafios para o desenvolvimento futuro da IA.
Recentemente, Andrej Karpathy, um conhecido pesquisador da indústria de IA, apresentou um ponto de vista controverso. Ele acredita que a atualmente amplamente elogiada tecnologia de aprendizagem por reforço baseada em feedback humano (RLHF) pode não ser a única maneira de alcançar. verdadeiras capacidades de resolução de problemas em nível humano. Esta declaração, sem dúvida, lançou uma bomba pesada no atual campo da pesquisa em IA.
O RLHF já foi considerado um fator-chave no sucesso de modelos de linguagem em larga escala (LLM), como o ChatGPT, e foi aclamado como a arma secreta que dá compreensão, obediência e capacidades de interação natural à IA. No processo tradicional de treinamento em IA, o RLHF é geralmente usado como o último elo após o pré-treinamento e o ajuste fino supervisionado (SFT). No entanto, Karpathy comparou o RLHF a um gargalo e a uma medida provisória, acreditando que está longe de ser a solução definitiva para a evolução da IA.
Karpathy comparou habilmente o RLHF ao AlphaGo da DeepMind. AlphaGo usou o que ele chama de verdadeira tecnologia RL (aprendizado por reforço) e, ao jogar constantemente contra si mesmo e maximizar sua taxa de vitórias, acabou ultrapassando os melhores jogadores de xadrez humanos sem intervenção humana. Essa abordagem atinge níveis de desempenho sobre-humanos, otimizando redes neurais para aprender diretamente com os resultados dos jogos.
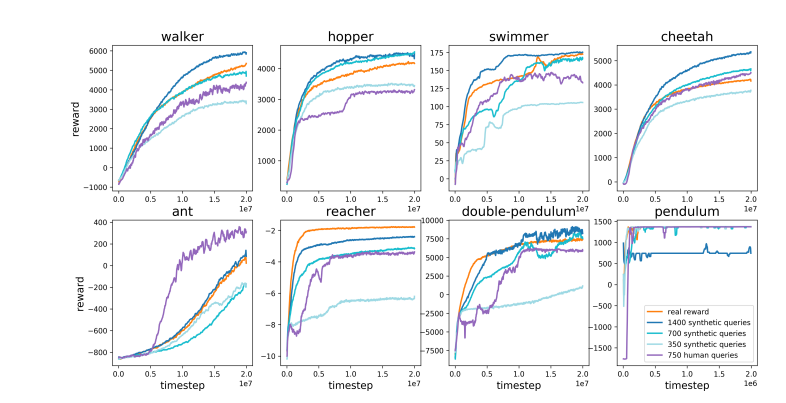
Em contraste, Karpathy acredita que o RLHF tem mais a ver com imitar as preferências humanas do que realmente resolver problemas. Ele imaginou que se o AlphaGo adotar o método RLHF, os avaliadores humanos precisarão comparar um grande número de estados do jogo e escolher preferências. Esse processo pode exigir até 100.000 comparações para treinar um modelo de recompensa que imite a verificação da atmosfera humana. No entanto, tais julgamentos baseados na atmosfera podem produzir resultados enganosos em um jogo rigoroso como o Go.
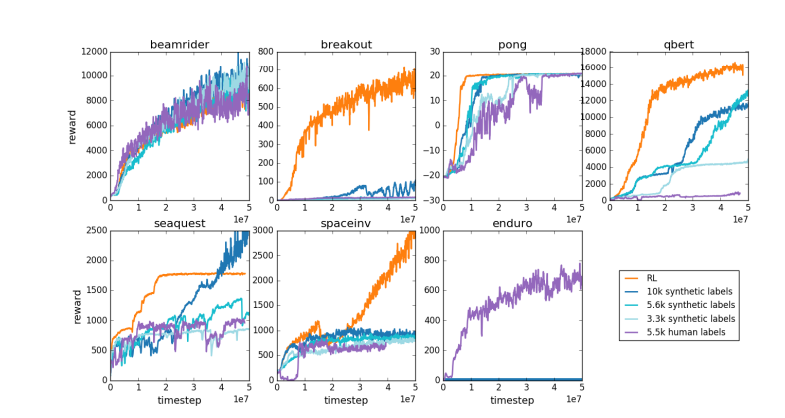
Pela mesma razão, o atual modelo de recompensa LLM funciona de forma semelhante – tende a classificar respostas altas que os avaliadores humanos parecem estatisticamente preferir. Este é mais um agente que atende às preferências humanas superficiais do que um reflexo da verdadeira capacidade de resolução de problemas. Ainda mais preocupante, os modelos podem aprender rapidamente como explorar esta função de recompensa, em vez de realmente melhorarem as suas capacidades.
Karpathy aponta que, embora a aprendizagem por reforço tenha um bom desempenho em ambientes fechados como Go, a verdadeira aprendizagem por reforço permanece ilusória para tarefas de linguagem aberta. Isto ocorre principalmente porque é difícil definir objetivos claros e mecanismos de recompensa em tarefas abertas. Como dar recompensas objetivas por tarefas como resumir um artigo, responder a uma pergunta vaga sobre a instalação do pip, contar uma piada ou reescrever o código Java em Python? Karpathy faz essa pergunta perspicaz, e ir nessa direção não é um princípio. mas também não é fácil e requer algum pensamento criativo.

Ainda assim, Karpathy acredita que se este difícil problema puder ser resolvido, os modelos de linguagem terão o potencial de realmente se igualarem ou até mesmo superarem as habilidades humanas de resolução de problemas. Esta visão coincide com um artigo recente publicado pelo Google DeepMind, que apontou que a abertura é a base da inteligência artificial geral (AGI).
Como um dos vários especialistas seniores em IA que deixaram a OpenAI este ano, Karpathy está atualmente trabalhando em sua própria startup de IA educacional. As suas observações injetaram, sem dúvida, uma nova dimensão de pensamento no campo da investigação em IA e forneceram informações valiosas sobre a direção futura do desenvolvimento da IA.
As opiniões de Karpathy geraram ampla discussão na indústria. Os defensores acreditam que ele revela uma questão fundamental na pesquisa atual sobre IA, que é como tornar a IA verdadeiramente capaz de resolver problemas complexos, em vez de apenas imitar o comportamento humano. Os opositores temem que o abandono prematuro do RLHF possa levar a um desvio na direção do desenvolvimento da IA.
Endereço do artigo: https://arxiv.org/pdf/1706.03741
As opiniões de Karpathy desencadearam discussões aprofundadas sobre a direção futura do desenvolvimento da IA. Suas dúvidas sobre o RLHF levaram os pesquisadores a reexaminar os métodos atuais de treinamento de IA e a explorar caminhos mais eficazes, com o objetivo final de alcançar a verdadeira inteligência artificial.