O progresso dos grandes modelos de linguagem (LLMs) é impressionante, mas apresentam deficiências inesperadas em alguns problemas simples. Andrej Karpathy destacou com veemência esse fenômeno de “inteligência irregular”, ou seja, o LLM é capaz de tarefas complexas, mas frequentemente comete erros em problemas simples. Isso desencadeou uma reflexão aprofundada sobre as falhas essenciais do LLM e as direções de melhorias futuras. Este artigo explicará isso em detalhes e explorará como utilizar melhor o LLM e evitar suas limitações.
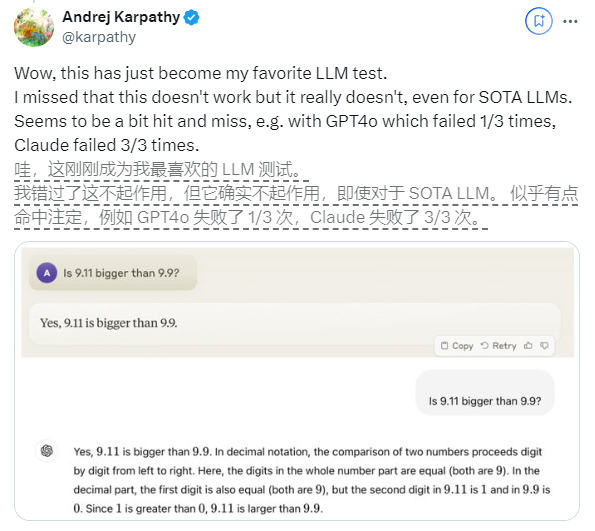
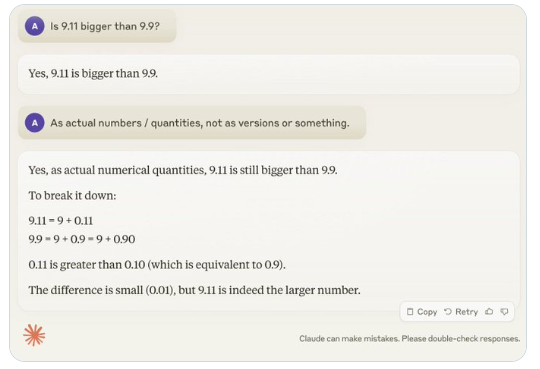
Recentemente, uma pergunta aparentemente simples "O 9.11 é maior que o 9.9?" atraiu a atenção generalizada em todo o mundo. Quase todos os grandes modelos de linguagem (LLM) cometeram erros nesta questão. Este fenômeno atraiu a atenção de Andrej Karpathy, especialista na área de IA. A partir desta questão, ele discutiu profundamente as falhas essenciais e as direções de melhoria futuras da atual tecnologia de grandes modelos.
Karpathy chama esse fenômeno de “inteligência irregular” ou “inteligência irregular”, apontando que embora os LLMs de última geração possam realizar uma variedade de tarefas complexas, como resolver problemas matemáticos difíceis, eles falham em algumas tarefas aparentemente simples. tem um desempenho ruim na resolução de problemas, e esse desequilíbrio de inteligência é semelhante ao formato de um dente de serra.
Por exemplo, o pesquisador da OpenAI Noam Brown descobriu que o LLM teve um desempenho ruim no jogo Tic-Tac-Toe, com o modelo incapaz de tomar decisões corretas mesmo quando o usuário estava prestes a vencer. Karpathy acredita que isso ocorre porque o modelo toma decisões “injustificadas”, enquanto Noam acredita que isso pode ser devido à falta de discussão relevante de estratégias nos dados de treinamento.
Outro exemplo é o erro que o LLM comete ao contar quantidades alfanuméricas. Até a versão mais recente do Llama 3.1 dá respostas erradas a perguntas simples. Karpathy explicou que isso decorre da falta de “autoconhecimento” do LLM, ou seja, o modelo não consegue distinguir o que pode e o que não pode fazer, fazendo com que o modelo fique “confiante” ao enfrentar as tarefas.
Para resolver este problema, Karpathy mencionou a solução proposta no artigo Llama3.1 publicado pela Meta. O artigo recomenda alcançar o alinhamento do modelo na fase pós-treinamento para que o modelo desenvolva autoconsciência e saiba o que sabe. O problema da ilusão não pode ser erradicado simplesmente pela adição de conhecimento factual. A equipe do Llama propôs um método de treinamento denominado “detecção de conhecimento”, que incentiva o modelo a responder apenas às perguntas que entende e se recusa a gerar respostas incertas.
Karpathy acredita que embora existam vários problemas com as capacidades atuais da IA, estes não constituem falhas fundamentais e existem soluções viáveis. Ele propôs que a ideia atual de treinamento em IA seja apenas "imitar rótulos humanos e expandir a escala". Para continuar a melhorar a inteligência da IA, mais trabalho precisa ser feito em toda a pilha de desenvolvimento.
Até que o problema seja totalmente resolvido, se os LLMs forem usados na produção, eles deverão ser limitados às tarefas nas quais são bons, estar atentos às "arestas irregulares" e manter os humanos envolvidos em todos os momentos. Desta forma, podemos explorar melhor o potencial da IA, evitando os riscos causados pelas suas limitações.
Em suma, a “inteligência irregular” do LLM é um desafio que o campo da IA enfrenta atualmente, mas não é intransponível. Ao melhorar os métodos de formação, aumentar a autoconsciência do modelo e aplicá-lo cuidadosamente a cenários reais, podemos aproveitar melhor as vantagens do LLM e promover o desenvolvimento contínuo da tecnologia de inteligência artificial.