A empresa israelense de inteligência artificial aiOla lançou recentemente um modelo de reconhecimento de voz de código aberto chamado Whisper Medusa. O modelo alcançou um avanço significativo em velocidade e sua velocidade de processamento é 50% mais rápida do que o modelo Whisper da OpenAI. Este avanço atraiu a atenção generalizada da indústria e o seu núcleo reside na melhoria do design arquitetónico e nos métodos de formação inovadores. Whisper Medusa não é apenas mais rápido, mas também mantém um alto nível de precisão e estabilidade, trazendo novas possibilidades para o desenvolvimento da tecnologia de reconhecimento de fala.
A empresa israelense de inteligência artificial aiOla fez recentemente um grande avanço no campo da tecnologia de reconhecimento de fala e lançou um modelo de reconhecimento de fala de código aberto chamado Whisper Medusa. A velocidade de processamento deste novo modelo é 50% mais rápida do que o modelo Whisper da OpenAI, que atraiu ampla atenção na indústria.
A principal inovação do Whisper Medusa é o seu design arquitetônico aprimorado. aiOla modificou a arquitetura original do Whisper e introduziu um mecanismo de atenção com várias cabeças. Este mecanismo permite que o modelo foque simultaneamente nas informações de diferentes subespaços de representação, usando múltiplas cabeças de atenção em paralelo. Essa inovação permite que o modelo preveja dez tokens por vez, em vez do tradicional token de um por vez, melhorando significativamente a velocidade de previsão de fala e o tempo de execução de geração.
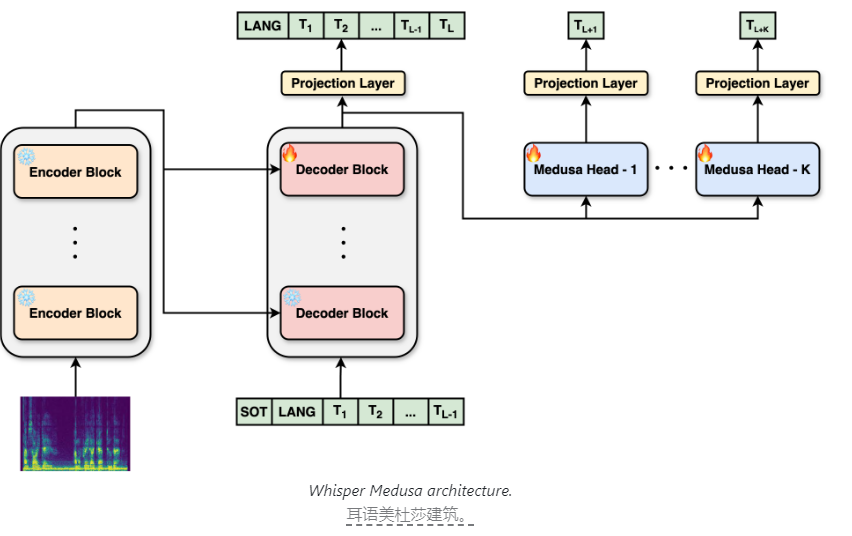
É importante notar que Whisper Medusa aumenta a velocidade sem sacrificar o desempenho. Isso se deve ao fato de seu sistema backbone ainda ser baseado no Whisper, garantindo a precisão e estabilidade do modelo. Durante o processo de treinamento, aiOla usa um método de aprendizado de máquina denominado supervisão fraca. Especificamente, eles congelaram os principais componentes do Whisper e usaram as transcrições de áudio geradas pelo modelo como rótulos para treinar módulos adicionais de previsão de tokens. Este método de treinamento inovador melhora ainda mais a eficiência e a precisão do aprendizado do modelo.
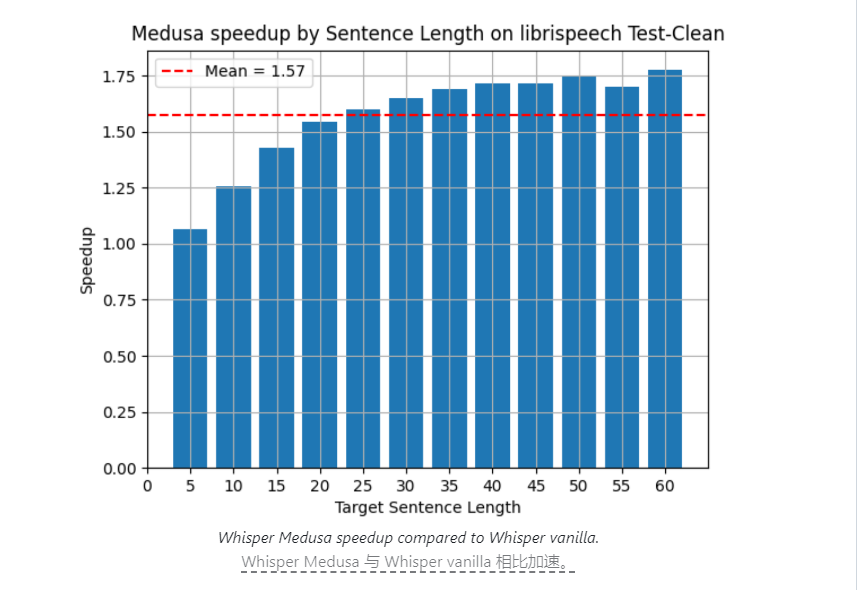
O lançamento de código aberto do Whisper Medusa poderá ter um impacto profundo no desenvolvimento da tecnologia de reconhecimento de fala. Ele não apenas fornece aos pesquisadores e desenvolvedores uma nova ferramenta poderosa, mas também pode impulsionar o desenvolvimento de aplicativos de processamento de fala mais rápidos e eficientes. No contexto da crescente procura de interacção por voz, este avanço tecnológico abrirá, sem dúvida, novas possibilidades para a aplicação da inteligência artificial no domínio do reconhecimento de voz.
Com o lançamento do Whisper Medusa, podemos esperar ver mais aplicações inovadoras baseadas neste modelo, desde assistentes inteligentes até tradução em tempo real e sistemas de controle de voz, todos os quais podem obter melhorias significativas de desempenho como resultado. Este progresso não só marca um marco importante na tecnologia de reconhecimento de voz, mas também traça um plano mais eficiente e suave para o futuro da interação entre a inteligência artificial e os humanos.
Endereço do projeto: https://github.com/aiola-lab/whisper-medusa
abraço: https://huggingface.co/aiola/whisper-medusa-v1
O código aberto e o alto desempenho do Whisper Medusa indicam que a tecnologia de reconhecimento de fala dará início a uma nova onda de desenvolvimento, trazendo uma experiência mais suave e eficiente para vários aplicativos de voz e promovendo a aplicação da tecnologia de inteligência artificial em mais campos. Esperamos ver surgir mais aplicações inovadoras baseadas neste modelo.