A experiência da Meta no treinamento do modelo de linguagem em grande escala Llama 3.1 nos mostrou desafios e oportunidades sem precedentes no desenvolvimento da IA. O enorme cluster de 16.384 GPUs sofreu uma falha média a cada 3 horas durante o período de treinamento de 54 dias. Isso não apenas destacou o rápido crescimento da escala do modelo de IA, mas também expôs o enorme gargalo na estabilidade da supercomputação. sistema. Este artigo irá aprofundar os desafios que Meta encontrou durante o processo de treinamento do Llama 3.1, as estratégias que adotaram para lidar com esses desafios e analisar suas implicações para toda a indústria de IA.
No mundo da inteligência artificial, cada avanço é acompanhado por dados impressionantes. Imagine que 16.384 GPUs estejam rodando ao mesmo tempo. Esta não é uma cena de um filme de ficção científica, mas um retrato real do Meta ao treinar o modelo mais recente do Llama3.1. Porém, por trás deste banquete tecnológico está uma falha que ocorre em média a cada 3 horas. Este número surpreendente não só demonstra a velocidade do desenvolvimento da IA, mas também expõe os enormes desafios enfrentados pela tecnologia atual.
Das 2.028 GPUs usadas no Llama1 às 16.384 GPUs usadas no Llama3.1, esse salto de crescimento não é apenas uma mudança na quantidade, mas também um desafio extremo à estabilidade do sistema de supercomputação existente. Os dados da pesquisa da Meta mostram que durante o ciclo de treinamento de 54 dias do Llama3.1, ocorreram um total de 419 falhas inesperadas de componentes, cerca de metade das quais relacionadas à GPU H100 e sua memória HBM3. Esses dados nos fazem pensar: ao mesmo tempo em que buscamos avanços no desempenho da IA, a confiabilidade do sistema também melhorou simultaneamente?
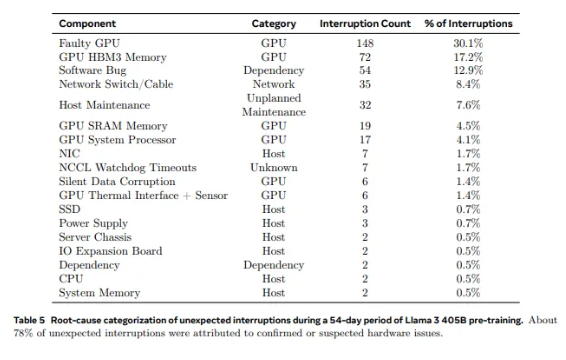
Na verdade, há um fato indiscutível no campo da supercomputação: quanto maior a escala, mais difícil é evitar falhas. O cluster de treinamento Llama 3.1 da Meta consiste em dezenas de milhares de processadores, centenas de milhares de outros chips e centenas de quilômetros de cabos, um nível de complexidade comparável ao da rede neural de uma pequena cidade. Em tal gigante, o mau funcionamento parece ser uma ocorrência comum.
Diante de falhas frequentes, a equipe Meta não ficou desamparada. Eles adotaram uma série de estratégias de enfrentamento: redução do tempo de inicialização do trabalho e dos pontos de verificação, desenvolvimento de ferramentas de diagnóstico proprietárias, aproveitamento do gravador de voo NCCL da PyTorch, etc. Estas medidas não só melhoram a tolerância a falhas do sistema, mas também melhoram as capacidades de processamento automatizado. Os engenheiros da Meta são como os bombeiros modernos, prontos para apagar qualquer incêndio que possa atrapalhar o processo de treinamento.
No entanto, os desafios não vêm apenas do hardware em si. Fatores ambientais e flutuações no consumo de energia também trazem desafios inesperados aos clusters de supercomputação. A equipe Meta descobriu que mudanças diurnas e noturnas de temperatura e flutuações drásticas no consumo de energia da GPU terão um impacto significativo no desempenho do treinamento. Esta descoberta lembra-nos que, ao mesmo tempo que procuramos avanços tecnológicos, não podemos ignorar a importância da gestão ambiental e do consumo de energia.
O processo de treinamento do Llama3.1 pode ser considerado um teste final da estabilidade e confiabilidade do sistema de supercomputação. As estratégias adotadas pela equipe Meta para lidar com os desafios e as ferramentas automatizadas desenvolvidas proporcionam experiência e inspiração valiosas para toda a indústria de IA. Apesar das dificuldades, temos motivos para acreditar que, com o avanço contínuo da tecnologia, os futuros sistemas de supercomputação serão mais poderosos e estáveis.
Nesta era de rápido desenvolvimento da tecnologia de IA, a tentativa da Meta é, sem dúvida, uma aventura corajosa. Não só ultrapassa os limites de desempenho dos modelos de IA, mas também nos mostra os desafios reais que enfrentamos na prossecução dos limites. Olhemos com expectativa para as infinitas possibilidades trazidas pela tecnologia de IA e, ao mesmo tempo, elogiemos os engenheiros que trabalham incansavelmente na vanguarda da tecnologia. Cada tentativa, cada fracasso e cada avanço que fazem abrem o caminho para o progresso tecnológico humano.
Referências:
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training- uma falha a cada três horas para metas-16384-gpu-training-cluster
O caso de treinamento do Llama 3.1 nos forneceu lições valiosas e apontou a direção futura do desenvolvimento de sistemas de supercomputação: ao buscarmos desempenho, devemos atribuir grande importância à estabilidade e confiabilidade do sistema e explorar ativamente estratégias para lidar com diversas falhas. Só desta forma poderemos garantir o desenvolvimento contínuo e estável da tecnologia de IA e beneficiar a humanidade.