A NVIDIA lançou recentemente a série Minitron de modelos de linguagem pequena, incluindo versões 4B e 8B. Esta mudança visa reduzir os custos de treinamento e implantação de grandes modelos de linguagem e permitir que mais desenvolvedores utilizem facilmente esta tecnologia avançada. Através de tecnologias de "poda" e "destilação de conhecimento", o modelo Minitron reduz significativamente o tamanho do modelo, mantendo desempenho comparável a modelos grandes, e até supera outros modelos conhecidos em alguns indicadores. Isto é de grande importância para promover a popularização da tecnologia de inteligência artificial.
Recentemente, a NVIDIA fez novos movimentos no campo da inteligência artificial. Eles lançaram a série Minitron de modelos de linguagem pequena, incluindo versões 4B e 8B. Esses modelos não apenas aumentam a velocidade de treinamento em 40 vezes, mas também tornam mais fácil para os desenvolvedores usá-los para diversas aplicações, como tradução, análise de sentimentos e IA conversacional.
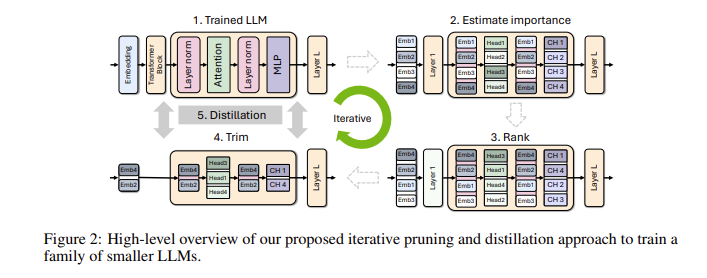
Você pode perguntar: por que os modelos de linguagem pequena são tão importantes? Na verdade, embora os modelos tradicionais de linguagem grande tenham um forte desempenho, seus custos de treinamento e implantação são muito altos e muitas vezes exigem uma grande quantidade de recursos de computação e dados. Para tornar essas tecnologias avançadas acessíveis a mais pessoas, a equipe de pesquisa da NVIDIA criou uma maneira brilhante: combinar duas tecnologias: “poda” e “destilação de conhecimento” para reduzir eficientemente o tamanho do modelo.
Especificamente, os pesquisadores começarão primeiro a partir de um grande modelo existente e o modificarão. Eles avaliam a importância de cada neurônio, camada ou núcleo de atenção no modelo e removem aqueles que são menos importantes. Desta forma, o modelo torna-se muito menor e os recursos e o tempo necessários para o treinamento também são bastante reduzidos. Em seguida, eles também usarão um conjunto de dados em pequena escala para realizar treinamento de destilação de conhecimento no modelo podado para restaurar a precisão do modelo. Surpreendentemente, este processo não só economiza dinheiro, mas também melhora o desempenho do modelo!
Nos testes reais, a equipe de pesquisa da NVIDIA obteve bons resultados na família de modelos Nemotron-4. Eles reduziram com sucesso o tamanho do modelo em 2 a 4 vezes, mantendo um desempenho semelhante. O que é ainda mais interessante é que o modelo 8B supera outros modelos conhecidos, como Mistral7B e LLaMa-38B em vários indicadores, e requer 40 vezes menos dados de treinamento durante o processo de treinamento, economizando 1,8 vezes em custos de computação. Imagine o que isso significa? Mais desenvolvedores podem experimentar recursos poderosos de IA com menos recursos e custos!
A NVIDIA torna esses modelos Minitron otimizados de código aberto no Huggingface para que todos possam usar livremente.
Entrada de demonstração: https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
Destaques:
** Melhor velocidade de treinamento **: A velocidade de treinamento do modelo Minitron é 40 vezes mais rápida que os modelos tradicionais, permitindo que os desenvolvedores economizem tempo e esforço.
**Economia de custos**: por meio da tecnologia de remoção e destilação de conhecimento, os recursos de computação e o volume de dados necessários para o treinamento são significativamente reduzidos.
? **Compartilhamento de código aberto**: O modelo Minitron tem código aberto no Huggingface, para que mais pessoas possam acessá-lo e usá-lo facilmente, promovendo a popularização da tecnologia de IA.
O código aberto do modelo Minitron marca um avanço importante na aplicação prática de modelos de linguagem pequena. Também indica que a tecnologia de inteligência artificial se tornará mais popular e mais fácil de usar, capacitando mais desenvolvedores e cenários de aplicação. No futuro, podemos esperar mais inovações semelhantes para promover o desenvolvimento contínuo da tecnologia de inteligência artificial.